This blog is a kick-off the series that will be dedicated to the graph databases and engines, being more specifically focused on the SQL Graph, that is the newest extension to the SQL Server engine, as well as the Azure SQL Database (upcoming).
What are Graph Databases
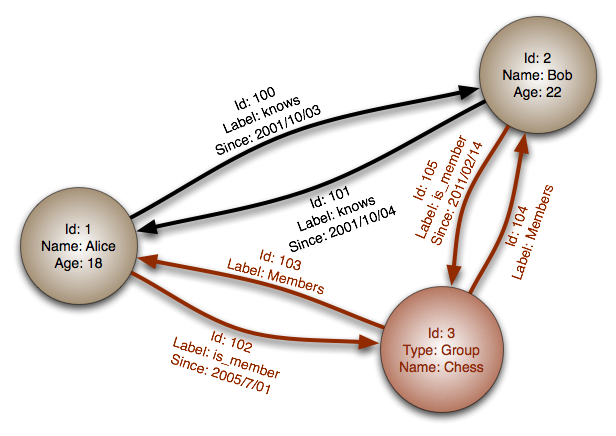 Graph databases are based on graph theory, and employ nodes, edges, and properties. The graph theory is the study of the graphs that are mathematical structures used to model pairwise relations between objects. A graph in this context is made up of nodes, edges which are connected by edges, arcs, or lines.
Graph databases are based on graph theory, and employ nodes, edges, and properties. The graph theory is the study of the graphs that are mathematical structures used to model pairwise relations between objects. A graph in this context is made up of nodes, edges which are connected by edges, arcs, or lines.
A graph can be directed or undirected (uni or bi-directional) that might point the direction of the relationship between the edges.
Graph databases can be compared to the Network Model Databases, that were focusing on solving the same problem the interconnected world.
The most popular graph database in the world currently is NEO4J, which is implemented in Java and is using CQL (Cypher Query Language), a language that has definitely inspired the SQL Graph T-SQL language extension.
SQL Graph
For SQL Server 2017 Microsoft has decided to do some very important addition in the form of the Graph engine, which is tentatively called SQL Graph.
Lead by Shreya Verma, this is most probably one of the most underrated and unappreciated effort with the relational engine.
The graph of the SQL Graph will consist from a collection of the Nodes & Edges that will be represented as tables.
Current implementation will allow to place one logical graph within a database (and I totally believe that this will change in the future releases of SQL Server, most probably on vNext).
SQL Graph currently contains 2 types of tables (Nodes & Edges), plus the extensions for the Query Processor that allow to process Nodes & Edges.
Node Table
Node table represents the entity (or vertice/point) that is the crucial part of the objects for the graph schema.
To create a node table you will simply need to specify that the table should be created as a node, and here below I am giving you an example of a Person table, containing 3 simple attributes that will be created for SQLGraph as a Node (you might consider the syntax to be similar to the In-Memory table creation, which type is defined after the effective table declaration:
DROP TABLE IF EXISTS dbo.Person; CREATE TABLE dbo.Person ( Id INT NOT NULL identity(1,1) primary key, FullName NVARCHAR(75) NOT NULL, Age TINYINT NOT NULL, ) AS NODE;
Within every Node Table there is a $node_id column, that will internally have a unique automatically generated name, helping to identify uniquely the object. This column will be created as a NVARCHAR(1000) with values stored as JSON.
Additionally another implicit identity column will be generated as a Graph_Id, which name will contain internal graph_id column with another hex string automatically added to it.
To see this in action, consider the following script which will display 5 columns of the dbo.Person table as rows:
select QUOTENAME(SCHEMA_NAME(tab.schema_id)) as SchemaName, QUOTENAME(OBJECT_NAME(tab.object_id)) as TableName, cols.name as ColumnName, t.name as DataType, cols.graph_type, cols.graph_type_desc, cols.* from sys.all_columns cols inner join sys.tables tab ON tab.object_id = cols.object_id INNER JOIN sys.types t ON cols.user_type_id = t.user_type_id WHERE tab.is_node = 1 ORDER BY SchemaName, TableName;

You can see that the first 2 columns within my table are graph_id_DE10743C3D514B0C8BA7B4FDAC8A6E83 & $node_id_6A94F9B73C414329B9EDBD059EB882C8, even though in the table definition they are not present at all. As I explained earlier, they are automatically generated if we define our table as a node.
Microsoft recommends that a default unique, non-clustered constraint or index should be created on the $node_id, and if one is not created, than it is automatically added on the creation.
Here is a script to verify this (feel free to add more filter to limit the results, if you have more tables defined as nodes):
SELECT QUOTENAME(SCHEMA_NAME(tab.schema_id)) as SchemaName, QUOTENAME(OBJECT_NAME(tab.object_id)) as TableName, ind.name as IndexName, indcol.column_id as ColumnId, cols.name as ColumnName FROM sys.indexes ind INNER JOIN sys.tables tab ON ind.object_id = tab.object_id RIGHT JOIN sys.index_columns indcol ON ind.object_id = indcol.object_id AND ind.index_id = indcol.index_id INNER JOIN sys.all_columns cols ON ind.object_id = cols.object_id AND indcol.column_id = cols.column_id WHERE tab.is_node = 1 AND ind.type = 2 /* Nonclustered */ ORDER BY SchemaName, TableName;
![]()
These are the basic internals of the Node table.
Edge Table
The Edge table represents a relationship between 2 Nodes within our graph (FROM and TO). For the current implementation the edges are always directed and it allows to represent many-to-many relationships very easily.
You can define a number (including none) of the attributes of the relationship between those Nodes.
The Edge will have 8 implicit columns that will be automatically added for every single created table, where only 3 of them will be visible for any query automatically (not hidden).
– graph_id_<hex_string> – the internal graph_id column of the graph (currently we have can have only one graph per database)
– $edge_id_<hex_string> – external $edge_id, which will uniquely identify the edge (relationship)
– from_obj_id_<hex_string> – stores the object_id of the FROM Node
– from_id_<hex_string> – stores the graph_id of the FROM Node
– $from_id_<hex_string> – stores the node_id of the FROM Node
– to_obj_id_<hex_string> – stores the object_id of the TO Node
– to_id_<hex_string> – stores the graph_id of the TO Node
– $to_id_<hex_string> – stores the node_id of the TO Node
The default visible 3 implicit columns are: $edge_id, $from_id & $to_id (those names exclude here the
To create an Edge (relationship) table you will simply need to specify that the table should be created as an Edge, and here below I am giving you an example of a FriendsWith table, containing 1 single attributes defining the number of years that people are friends:
DROP TABLE IF EXISTS dbo.FriendsWith; CREATE TABLE dbo.FriendsWith( YearsOfFriendship TINYINT NULL, ) AS EDGE;
To see the internals columns of our created Edge, let us use a very similar query, which has only modification in the form of is_edge = 1 property of the sys.tables DMV:
select QUOTENAME(SCHEMA_NAME(tab.schema_id)) as SchemaName, QUOTENAME(OBJECT_NAME(tab.object_id)) as TableName, cols.name as ColumnName, t.name as DataType, cols.graph_type, cols.graph_type_desc, cols.* from sys.all_columns cols inner join sys.tables tab ON tab.object_id = cols.object_id INNER JOIN sys.types t ON cols.user_type_id = t.user_type_id WHERE tab.is_edge = 1 ORDER BY SchemaName, TableName;

And on the picture above this text, you can that the created table has 9 columns, from which 8 are those implicitly created ones.
Similarly to the Node table, we have a default unique Nonclustered Index on the graph_id, as you can see below:
SELECT QUOTENAME(SCHEMA_NAME(tab.schema_id)) as SchemaName, QUOTENAME(OBJECT_NAME(tab.object_id)) as TableName, ind.name as IndexName, indcol.column_id as ColumnId, cols.name as ColumnName FROM sys.indexes ind INNER JOIN sys.tables tab ON ind.object_id = tab.object_id RIGHT JOIN sys.index_columns indcol ON ind.object_id = indcol.object_id AND ind.index_id = indcol.index_id INNER JOIN sys.all_columns cols ON ind.object_id = cols.object_id AND indcol.column_id = cols.column_id WHERE tab.is_edge = 1 AND ind.type = 2 /* Nonclustered */ ORDER BY SchemaName, TableName;
![]()
Graph Tables in SSMS
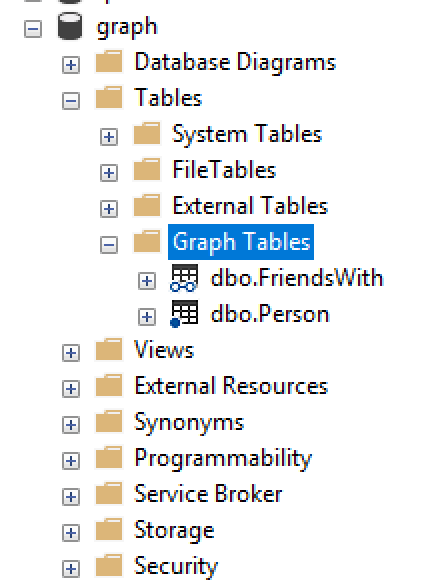 In SSMS, graph tables have their own category, or more precisely speaking – subfolders for the “tables” folder. Opening this subfolders will allow you to list the of the graph tables with their icons helping you to identify the type of the table – the one with a dot near the table is a Node table, and the one with a vector connecting 2 nodes is a naturally the edge table. I love this solution, because it will help developers & DBAs to be more precise and more productive, while making less mistakes.
In SSMS, graph tables have their own category, or more precisely speaking – subfolders for the “tables” folder. Opening this subfolders will allow you to list the of the graph tables with their icons helping you to identify the type of the table – the one with a dot near the table is a Node table, and the one with a vector connecting 2 nodes is a naturally the edge table. I love this solution, because it will help developers & DBAs to be more precise and more productive, while making less mistakes.
Overall I hope that there will be some support for the visualisation of the graphs within SSMS, even though rudimentary in the beginning, one definitely has a need to be able to visualise the structure that is built/used within a graph. Alternatively in 2-3 years there will be some vendor company that will provide this can of SSMS extension, but the lack of the visualisation will harm the acceptance of the SQLGraph in SQL Server.
Almost CQL
CQL – or better known as a Cypher query language is a declarative query language that serves for querying & manipulating the graph database.
The CQL was originally developed by the Neo Technology for their flagship database product Neo4J, but was later opened in 2015 and starts to conquer the graph database space as a default language.
The well-known format for the CQL queries is starts with the MATCH clause that identifies what data needs to be matched with, in the following example below we are matching actor to the movie (thus their relationship). The MATCH filter for the SQL would be an extension of the WHERE clause, but in CQL this is a simple matching criteria, thus the WHERE clause should follow it (in the example we are doing wildcard search that would be doing a search for the titles that starts with letter T – like ‘T%’).
Next step is to identify the information that will be returned to the user (SELECT statement for the SQL),
and the last one is the ORDER BY which is quite universally understood and interpreted, the LIMIT 10 is the MySQL type of clause for filtering only 10 results and this syntax can be found in SQL Server for many years under ORDERY BY FETCH NEXT:
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie) WHERE movie.title STARTS WITH "T" RETURN movie.title AS title, collect(actor.name) AS cast ORDER BY title ASC LIMIT 10;
Now, let’s see a couple of things about the T-SQL implementation of the graph engine.
The MATCH extension for the T-SQL language is a built-in improvement that allows support of the pattern matching and traversal through the graph within SQL Server.
This extension is not exclusive to the SELECT statement, meaning that you can use this extension to filter rows while inserting, updating or removing rows. Notice that there is a current limitation that the MERGE statement is not supported.
The format of the first release of the MATCH extension is following:
MATCH () ::= { { { <-( )- } | { -( )-> } } } [ { AND } { ( ) } ] [ ,...n ]
Where we use node_alias as the alias of the Node Table, mapping its relationship to the Edge Tables through the ‘-‘ or the ‘->’ indication, selecting the type of the relationship (if we are using the Edge Table to relate to the other Node Table for the ‘-‘ symbol or we are using the Edge Table to search within our Node Table, in the case of the ‘->’ symbol usage).
Notice that the node names inside the MATCH extension can be used, while the edge name can not be repeated.
One thing that I greatly dislike from the current implementation is that only the 20+ years style of join is supported, meaning that in order to take advantage of this extension, you will need to write the list of the tables that you are joining, separated by comma (,), instead of doing the modern joins, where you would right the name of the table with the join condition for each of the tables separately.
Example of the old-style join, required for the MATCH extension:
SELECT a.NAME
FROM dbo.Table1 a, dbo.Table2 b
WHERE a.Id = b.Id;
Example of the modern-style join that I have been using for way too long:
SELECT a.NAME
FROM dbo.Table1 a
INNER JOIN dbo.Table2 b
ON a.Id = b.Id;
I really hope that with a service pack or within the next version after SQL Server 2017, there will be this absolutely essential improvement for the query writing.
The other really painful limitation of the current implementation is the impossibility of using the OR & NOT expressions, making the real applications more difficult (one can not guarantee to the responsible that there will be no such requirement in the project)
Msg 13905, Level 16, State 1, Line 6 A MATCH clause may not be directly combined with other expressions using OR or NOT.
Basic Examples
We have already created a Node table (Person) and an Edge table (FriendsWith), and so let’s put some data into it. For this purpose, I will put top 10 Male & Female names for the kids born in Portugal in 2015, while putting information of their respective age that corresponds to the occupied place in the popularity ranking:
TRUNCATE TABLE dbo.Person;
INSERT INTO dbo.Person
(Fullname, Age )
VALUES
('João', 1),
('Martim', 2),
('Rodrigo', 3),
('Santiago', 4),
('Francisco', 5),
('Afonso', 6),
('Tomás', 7),
('Miguel', 8),
('Guilherme', 9),
('Gabriel', 10);
INSERT INTO dbo.Person
(Fullname, Age )
VALUES
('Maria', 1),
('Leonor', 2),
('Matilde', 3),
('Beatriz', 4),
('Carolina', 5),
('Mariana', 6),
('Ana', 7),
('Inês', 8),
('Margarida', 9),
('Sofia', 10);
Let us also add the information on the edges (relationships) that interconnects the people with the same age (one directional):
TRUNCATE TABLE dbo.FriendsWith; INSERT INTO dbo.FriendsWith ([$from_id_51EA2C6488A34AF293E6643771BF7C2D], [$to_id_5C5DCB0767CE459B930EB9032B4B757E]) SELECT p1.$node_id as from_obj_id, p2.$node_id as to_obj_id FROM dbo.Person p1 INNER JOIN dbo.Person p2 on p1.Age = p2.Age WHERE p1.$node_id <> p2.$node_id and p1.Id <= 10;
Let us also add some 21 random connections to create a graph of those random connections:
INSERT INTO dbo.FriendsWith ([$from_id_51EA2C6488A34AF293E6643771BF7C2D], [$to_id_5C5DCB0767CE459B930EB9032B4B757E]) SELECT TOP 21 p1.$node_id as from_obj_id, p2.$node_id as to_obj_id FROM dbo.Person p1 INNER JOIN dbo.Person p2 on p1.Age < p2.Age WHERE p1.$node_id <> p2.$node_id ORDER BY NEWID();
Now we are ready to run a couple of test queries, that will show you the beauty of the graph engine. For the start, let's run a simple query that will give us the list of all people with friends (out of 20) and their respective number of connections - which will serve as a sorting factor for this data set:
-- People with the most friends SELECT p1.FullName, COUNT(*) as FriendsCount FROM dbo.Person p1, dbo.FriendsWith friend, dbo.Person p2 WHERE MATCH(p1-(friend)->p2) GROUP BY p1.FullName ORDER BY FriendsCount DESC;
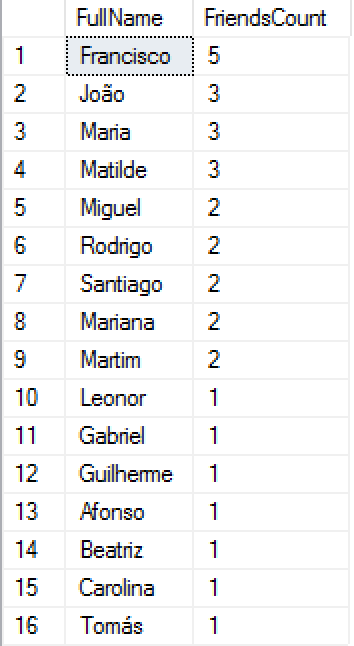 As you can see from the displayed results on the left, we have just 16 people who received those random friendship connections (out of 20), with Fransisco leading the pack with those incredible 5 connections. Is he the most important node in the graph ? We might find this out at a later stage in the next blog series, but for the moment I am already happy to be able to ask a couple more questions to this data.
As you can see from the displayed results on the left, we have just 16 people who received those random friendship connections (out of 20), with Fransisco leading the pack with those incredible 5 connections. Is he the most important node in the graph ? We might find this out at a later stage in the next blog series, but for the moment I am already happy to be able to ask a couple more questions to this data.
For example here is a rather simple & understandable query, for finding the most number of boys who have girls as friends (1st & 2nd level connections in the graph):
-- People with biggest number of friends of the opposite sex (1st & 2nd connections) SELECT p1.FullName, COUNT(*) as FriendsCount-- p2.FullName, p3.FullName FROM dbo.Person p1, dbo.FriendsWith friend, dbo.Person p2, dbo.FriendsWith friend2, dbo.Person p3 WHERE MATCH(p1-(friend)->p2-(friend2)->p3) AND p1.Id <= 10 AND (p2.Id > 10 OR p3.Id > 10) GROUP BY p1.FullName ORDER BY FriendsCount DESC;
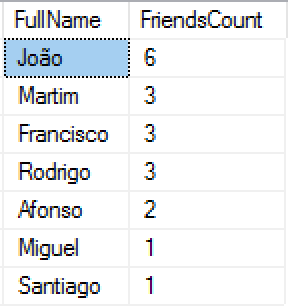 This is an example of building an easy understandable and processable query with this new SQL Graph engine.
This is an example of building an easy understandable and processable query with this new SQL Graph engine.
Another example here is on finding the people who have a common friend:
-- Find the people who are friends of the same person SELECT p1.FullName as Friend1, p3.FullName as Friend2--, * FROM dbo.Person p1, dbo.FriendsWith friend, dbo.Person p2, dbo.FriendsWith friend2, dbo.Person p3 WHERE MATCH(p1-(friend)->p2<-(friend2)-p3) AND p1.$node_id <> p3.$node_id;
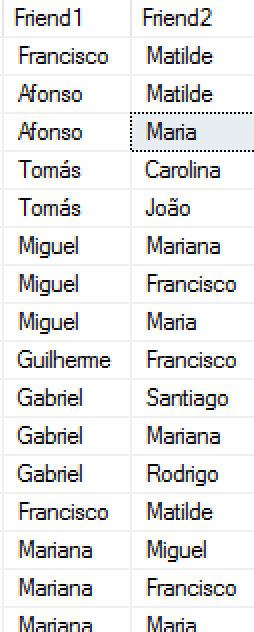 The results on the right side represent a non-complete set of the results, which is showing the names of the people who have a common friend. I love the easiness of the query construction, that will allow a lot of T-SQL developers to dive into the graph databases, without acquiring additional knowledge of a brand new language. The MATCH search condition is the only thing that one needs to learn right now to be able to start querying the graph.
The results on the right side represent a non-complete set of the results, which is showing the names of the people who have a common friend. I love the easiness of the query construction, that will allow a lot of T-SQL developers to dive into the graph databases, without acquiring additional knowledge of a brand new language. The MATCH search condition is the only thing that one needs to learn right now to be able to start querying the graph.
Not so final Thoughts
While R & Python integrations were and are greatly celebrated by virtually everyone, it looks to me that bashing the initial effort of SQL Graph is a kind of a popular activity online, and this is badly wrong.
Judging the very first initial step in the development and evolution of the graph engine is not a very easy thing from my point of view. Of course I would love to have there transitive closure or betweenness centrality right away, but given the amount of time that the SQL Server 2017 had since the release of the SQL Server 2016, I will be more than happy to have the basic structures (nodes, edges) and the graph query processing (MATCH clause).
I perfectly understand that we do not have the usual depth of the graph analysis right now (we just have new table structures & query processing format), but consider this a gentle step into the right direction which needs to be further encouraged and supported, and I am fully inclined to do so. Given the amazing people are driving this effort, I have not doubt that should they have enough time and resources, they will drive SQL Graph to become daily used by almost all data professionals part of the SQL Server and Azure SQL Database offer.
Even though we must still rely on the brute force calculations for getting the full graph functionality, I feel like a number of tasks are already can be taken advantage of.
The huge advantage of the progress of this rapid development is that we can start using all available technologies in combination with SQL Graph, such as Columnstore or Partitioning, without having to adapt anything.
I will be showing off more examples of the SQL Graph usage in the next weeks to come and this is why this topic is 100%
to be continued ...
Great introduction, Niko!
I am excited how long it will take you to have 100 blog posts about Graph DB (like you managed to do for ColumnStore Index). :-)
I spotted a typo:
“The format of the first release of the MERGE extension is following:”
should probably be corrected to
“The format of the first release of the MATCH extension is following:”
According to https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-architecture you should stick to the pseudo-names of the special columns (eg. “([$from_id]” instead of “([$from_id_51EA2C6488A34AF293E6643771BF7C2D]”) in your query examples.
Hi Markus,
thank you for pointing out the typo, it is now corrected.
Regarding the pseudo-names for the columns, I prefer to vary my scripts in order to explore different aspects, even those which are not suggested.
Best regards,
Niko
Another typo
The graph of the SQL Graph will consist from a collection of the Nodes & Tables that will be represented as tables.
should be
Nodes & Edges
Hi Steve,
thank you very much ! I have corrected the typo.
Best regards,
Niko
With respect to the Microsoft recommendation that “a default unique, non-clustered constraint or index should be created on the $node_id, and if one is not created, than it is automatically added on the creation”, I noticed that the actual result seems to be a generated unique index on the graph_id column instead of the expected column $node_id, as is shown in your screenprint.
Hi Erwin,
good catch – let me clear that out. Maybe this is a documentation error…
I think this is an old, pre-release information that simply did not get up to date, but I will clear this out and post an update soon.
Best regards,
Niko Neugebauer
Thanks for the great blog post Niko
I played around with these new graph features but didn’t find a way to MATCH outer Joins. Do you know how this can be done?
Thanks in advance.
Hi Pascal,
to my understanding, this can not be done in the regular way of the supported Syntax. I have better hopes for the vNext release, there must be a number of great improvements, after the initial alpha-release :)
Best regards,
Niko
Can you do a post real-time syncing your relational data in SQL server to the graph db tables?
Where should this be done? What tools should we use? We can easily see the benefits of the graph, but getting the data and keeping it updated in real-time is always the roadblock.
i also would love to see this. It seems like if Microsoft wants to encourage users to build hybrid databases that combine Relational and Graph tables we need a way to keep denormalized graph versions in sync with the relational tables they are derived from.
Can anyone advise me on this? I’m trying to use this for an experimental project.
How do we actually access these tables outside of SSMS? So far it seems impossible. I’ve tried with PowerBI, Linqpad and Entity Framework.
All I get are these pointless errors :(
Cannot access internal graph column ‘from_obj_id
Hi Richard,
I assume that you have already got your problem solved.
The column ‘from_obj_id_<hex_string> in my blog post got axed by the editor and that was the source of the misunderstanding. Sorry for that.
Best regards,
Niko