I have been fascinated with another new feature of the upcoming SQL Server release and so I decided to blog about it.
The new version of SQL Server (2017) introduces a very exciting feature for the DBA’s – the Resumable Online Index Rebuild.
This feature is targeting the installations that are doing regular maintenance but which maintenance windows are very limited, and sometimes there is an importance of suspending the indexes rebuild operation. Not canceling it, but suspending or pausing. Sometimes, when the system resources are suddenly needed for a more important business activity.
There have always been a need to have a different option of “everything or nothing” when doing a maintenance for the internal structures of the database, unlike for the data operations where we typically desire for every data manipulation to be successfully executed or to be rolled back entirely.
This new type of the index operation is what Microsoft is bringing in the SQL Server 2017. The Resumable Online Index Rebuild will provide you with an option of executing, suspending, resuming or aborting an online index operation.
In its first iteration the Resumable Online Index Rebuild is supporting Rowstore Indexes only. Boo! – I can hear thousands of voices screaming!
Since SQL Server 2014 there are very few reasons (exceptions) to store biggest tables with any other technologies besides the Columnstore.
The thing is – currently, there is only one online index rebuild operation available for the Columnstore Indexes, and I totally understand why Microsoft decided to focus on the Rowstore Indexes in this iteration.
The syntax for executing the Resumable Online Index Rebuild is described below:
ALTER INDEX { index_name | ALL } ON
there are
– ONLINE (for using ROIR (Resumable Online Index Rebuild), you will have to specify this option, otherwise there is no Online operation :))
– RESUMABLE (this is how you will specify that the rebuild process should be executed, with the possible values OFF (default) – when we do execute online rebuild in a good old way, and ON – where we use the new resumable build )
– MAX_DURATION =
The tests
Let’s do some test to find out how this feature behaves and for that I will use my own generated copy of the TPCH database (10GB version), that I have done with the help of the HammerDB (free software).
/*
* This script restores backup of the TPC-H Database from the C:\Install
*/
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1gb_new.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
-- SQL Server 2017
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 140
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
This time I will be using ORDERS table for the online rebuild operation tests. This table contains 2 indexes: [o_orderdate_ind] & [orders_pk]. To make operation runs faster, I will be focusing on the clustered index [o_orderdate_ind] index, containing the column [o_orderdate] (Date).
To measure the index fragmentation, I will be using the following query:
SELECT dbschemas.[name] as [Schema], dbtables.[name] as [Table], dbindexes.[name] as [Index], cast(indexstats.avg_fragmentation_in_percent as Decimal(5,2)) as FragmentationPercent, indexstats.page_count as PageCount FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats INNER JOIN sys.tables dbtables ON dbtables.[object_id] = indexstats.[object_id] INNER JOIN sys.schemas dbschemas ON dbtables.[schema_id] = dbschemas.[schema_id] INNER JOIN sys.indexes dbindexes ON dbindexes.[object_id] = indexstats.[object_id] AND indexstats.index_id = dbindexes.index_id WHERE indexstats.database_id = DB_ID() and dbtables.[name] = 'orders' and dbindexes.[name] = 'o_orderdate_ind';
Now let’s do some serious updates this 15.000.000 rows table, by simply increasing the date of the orders by 1 for the 1 million rows:
update top (1000000) dbo.orders set o_orderdate = dateadd(day,1,o_orderdate);
Checking on the provoked fragmentation level, gives us the following information:
![]() Your milage will vary and in my case I have already executed a couple of tests before seeing very different numbers, but I will follow the trail with the current ones and I do recommend not to worry about them, but mostly to focus on the execution process at the moment. Should your system not allow you to have reasonable (~1 minute) execution times, then simply increase the number of rows you are updating or decrease them if it takes too long to see operations executed.
Your milage will vary and in my case I have already executed a couple of tests before seeing very different numbers, but I will follow the trail with the current ones and I do recommend not to worry about them, but mostly to focus on the execution process at the moment. Should your system not allow you to have reasonable (~1 minute) execution times, then simply increase the number of rows you are updating or decrease them if it takes too long to see operations executed.
Now, let’s start the ROIR to fix the fragmentation:
ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON );
This operation will instantly fail because I did not specify the ONLINE = ON option, delivering the following error message:
Msg 11438, Level 15, State 1, Line 5 The RESUMABLE option cannot be set to 'ON' when the ONLINE option is set to 'OFF'.
That was what I expected, so let’s correct and run the Resumable Online Index Rebuild with the ONLINE = ON option, as we should:
ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
Immediately after starting the operation I will open a new window in SSMS and fire the following command /* new in SQL Server 2017 */ suspending the rebuild operation:
ALTER INDEX o_orderdate_ind ON [dbo].[orders] PAUSE;
The original window where I have started rebuild Resumable Online Index Rebuild process will be immediately terminated and disconnected, delivering the following error messages of the levels 16-21:
Msg 1219, Level 16, State 1, Line 3 Your session has been disconnected because of a high priority DDL operation. Msg 1219, Level 16, State 1, Line 3 Your session has been disconnected because of a high priority DDL operation. Msg 596, Level 21, State 1, Line 2 Cannot continue the execution because the session is in the kill state. Msg 0, Level 20, State 0, Line 2 A severe error occurred on the current command. The results, if any, should be discarded.
Do not get worried when seeing this – this is totally expected. If you carefully read the messages – you will understand that your process was simply canceled and the connection was terminated, so that other commands would not proceed executing.
Let’s fire up a query against the sys.index_resumable_operations DMV, that will provide us information and the details on the operations:
SELECT total_execution_time, percent_complete, page_count, * FROM sys.index_resumable_operations;
![]()
From the picture above you can see that we have canceled our online resumable index rebuild process, right after 3.5% of the work completion. Some of the most important columns in this DMV are total_execution_time, percent_complete, page_count & state, where state & state_desc will provide with the status of the executed process, and in our case the process has been Paused, meaning that we can simply restart and complete it.
Let’s do this by invoking the original command once again:
ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
We shall immediately get a warning message:
Warning: An existing resumable operation with the same options was identified for the same index on 'orders'. The existing operation will be resumed instead.
Giving us information that the previous Resumable Online Index Rebuild operation was found as paused and will be resumed.
Naturally I was monitoring the current progress of the operation with the help of the sys.index_resumable_operations DMV help, and below you will find a screenshot:
![]()
This is very cool, we can really work with our maintenance by controlling the process and without losing the progress.
But what if I say I have just 1 minute of time that I can do maintenance, can I program the process to pause right after 1 minute (after my tests it takes a little bit over 1 minutes typically)?
Absolutely, as I have already mentioned above, there is a new parameter for the ALTER INDEX REBUILD for that.
But first, let’s update 2 million rows in order to introduce some fragmentation:
update top (2000000) o set o_orderdate = dateadd(day,1,o_orderdate) from dbo.orders o;
Now, we can execute the resumable .. that will be running for 1 minute only, by specifying MAX_DURATION parameter with the value of 1 minute:
ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON, MAX_DURATION = 1 MINUTE);
The operation ran it’s course and was terminated around 1 minute after it’s start, leaving the following messages behind:
Msg 3643, Level 16, State 1, Line 1 The operation elapsed time exceeded the maximum time specified for this operation. The execution has been stopped. Msg 3643, Level 16, State 1, Line 1 The operation elapsed time exceeded the maximum time specified for this operation. The execution has been stopped. The statement has been terminated. Msg 596, Level 21, State 1, Line 0 Cannot continue the execution because the session is in the kill state. Msg 0, Level 20, State 0, Line 0 A severe error occurred on the current command. The results, if any, should be discarded.
Checking on the status of the ROIR operation, I have received the following results:
SELECT total_execution_time, percent_complete, page_count, * FROM sys.index_resumable_operations;
![]()
This status shows that the operation has been paused with 86% of the progress automatically – this is exactly what we needed!
Because Resumable Online Index Rebuild will consume additional space resources even when it is paused, you might want to add the next step of canceling (option ABORT) the resumable processes, if you wish so, and with the sys.index_resumable_operations DMV it will be very easy to identify those ones.
We can resume the operation to let it finish
ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON)
How fast it runs
To measure how fast ROIR operations are, I decided to rebuild a couple of tables from the TPCH database a couple of times and compare the ONLINE rebuild with Resumable Online Index Rebuild and without.
First candidate for that was the index I have been experimenting before, the clustered index o_orderdate_ind on the dbo.orders table.
For that purpose, I have executed the following script:
set statistics time on ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON) ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = OFF, ONLINE = ON)
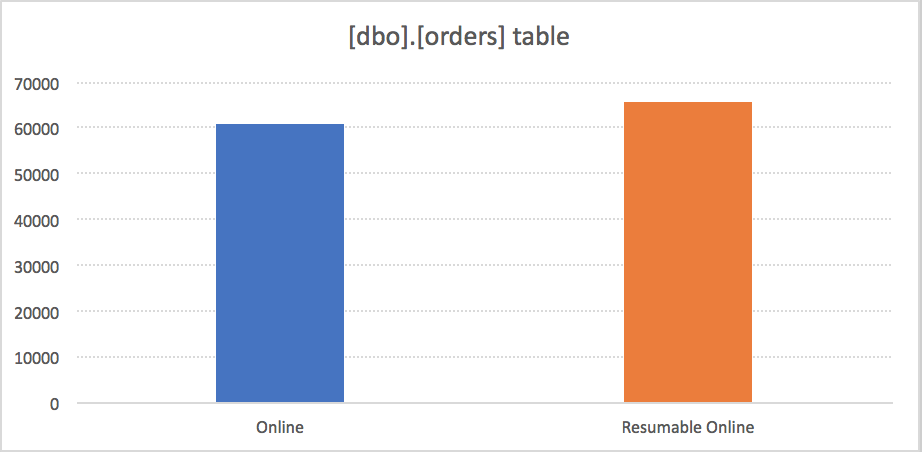 After multiple executions, the first process (Resumable Online Index Rebuild) on the average took 65.8 seconds, while the second one (a simple online) took only 60.8 seconds, representing 8% of the improvement of the overall performance. I can’t say if it looks acceptable to you or not, but for me this is something I will be definitely considering to be as an advantage for the cases where the resumable process is needed.
After multiple executions, the first process (Resumable Online Index Rebuild) on the average took 65.8 seconds, while the second one (a simple online) took only 60.8 seconds, representing 8% of the improvement of the overall performance. I can’t say if it looks acceptable to you or not, but for me this is something I will be definitely considering to be as an advantage for the cases where the resumable process is needed.
I decided to run a test on much bigger table, the lineitem which for 10GB TPCH database contains 60 Million Rows. My expectation here was to see if the percentage would stay the same or will jump to a whole new level (please make sure that you do execute the following script at least a couple of times, to get the real results and not the results of your disk-drive prefetching :)):
set statistics time on ALTER INDEX [l_shipdate_ind] ON [dbo].[lineitem] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON); ALTER INDEX [l_shipdate_ind] ON [dbo].[lineitem] REBUILD WITH ( RESUMABLE = OFF, ONLINE = ON);
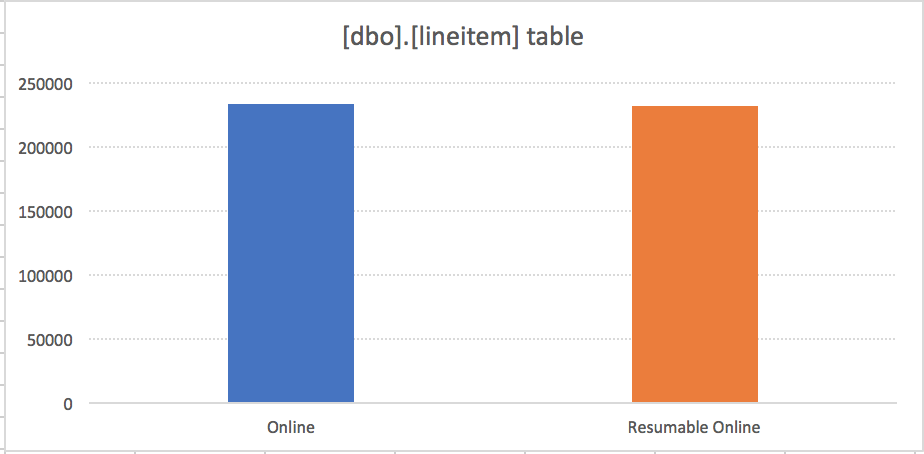 Well, here I have seen a very nice surprise – the ROIR operation took 232 seconds (3 Minutes and 52 seconds) while the default online rebuild took 230 seconds (3 Minutes and 50 seconds) with a difference of just 2 seconds, representing an incredibly small difference of just 1%. This price would be more than acceptable, in my personal opinion.
Well, here I have seen a very nice surprise – the ROIR operation took 232 seconds (3 Minutes and 52 seconds) while the default online rebuild took 230 seconds (3 Minutes and 50 seconds) with a difference of just 2 seconds, representing an incredibly small difference of just 1%. This price would be more than acceptable, in my personal opinion.
Naturally running an online operation without the concurrent workload is a kind of a fake test, and I am considering to post another blog post after the RTM release of the SQL Server 2017 to measure the performance as close to the real situations as possible.
How it works
To my understanding, internally the process will create small transactions, splitting the overall workload between some certain number and in the case when operation is stopped/paused/aborted, the internal rollback mechanism will cancel the data for the current small piece and will rollback to the last known committed transaction. In this way the loss of the information is very limited and to the final user/dba it looks like the process is canceled almost instantly.
Having a long pause for an index operation may impact the DML performance on a specific table as well as the database disk capacity since both indexes the original one and the newly created one require disk space and need to be updated during DML operations. If MAX_DURATION option is omitted, the index operation will continue until its completion or until a failure occurs.
A couple of words on Monitoring
You might say – wait a second, but what about the good old sys.dm_exec_requests DMV, I have all my monitoring queries and tools using it since like the last 10 years! How can I find out if a currently running query is a resumable operation or not ? Currently (23.04.2017) there is nothing in the documentation that mentions Resumable Online Index Rebuild!
Here is a little tip – when working with CTP or RC version, try checking out the real code of the DMVs, DMFs and other objects, to find out if there is something that can help you:
exec sys.sp_describe_first_result_set N' select * from sys.dm_exec_requests;';
 If you look carefully at the results and scroll to the bottom of the list, you will find a number of new columns, such DOP – the Degree of Parallelism, external_script_request_id, and most relevant to this blog post – is_resumable!
If you look carefully at the results and scroll to the bottom of the list, you will find a number of new columns, such DOP – the Degree of Parallelism, external_script_request_id, and most relevant to this blog post – is_resumable!
This means that you can easily identify the resumable operations (hopefully there will be much more than just a rowstore index rebuild in the nearest future).
Right now for SQL Server 2017, you can identify Resumable Online Index Rebuild operations easily by issuing the following query with a predicate:
select * from sys.dm_exec_requests where is_resumable = 1;
So now you can go and update your scripts to include this clause, if needed :)
Trying out less clear waters
Well, there are some limitations to the current V1 implementation (and keep in mind, that this is still CTP 2.0, not the RTM – meaning there will be improvements).
One of most screaming one is the lack of the SORT_IN_TEMPDB option. On the SQL Servers where the TEMPDB is saving the operations by having a fast drive, you won’t be able to count on the Resumable Online Index Rebuild:
ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON, SORT_IN_TEMPDB = ON );
Running the above script will give you the following error message:
Msg 11438, Level 15, State 2, Line 5 The SORT_IN_TEMPDB option cannot be set to 'ON' when the RESUMABLE option is set to 'ON'.
:(
I truly want this one to be fixed as soon as possible. In the perfect world I would love to see it being fixed before RTM.
And I have a bad feeling that this feature will wait for at least one release… :(
Timestamps:
There is a lot of software (and even own from Microsoft, such as Dynamics Navision that is using TIMESTAMP data type very heavily, let’s try out rebuilding an index that contains the timestamp as the leading column:
drop table if exists dbo.ROIR_Test1; create table dbo.ROIR_Test1( c1 int identity(1,1) not null, c2 timestamp, constraint pk_roir_test1 primary key(c1), index ix_ROIR_Test1 nonclustered(c2) ); GO set nocount on insert into dbo.ROIR_Test1 default values; GO 10 alter index ix_ROIR_Test1 on ROIR_Test1 REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
Msg 10639, Level 16, State 1, Line 15 Resumable index operation for index 'ix_ROIR_Test1' failed because the index contains column 'c2' of type timestamp as a key column.
Insert a sad face here.: (
Computed Columns:
Oh those computed columns, they can be so helpful, but they are so much unsupported (especially in the Columnstore Indexes :():
drop table if exists dbo.ROIR_Test2; create table dbo.ROIR_Test2( c1 int identity(1,1) not null, c2 as c1 * 1.23 PERSISTED, constraint pk_ROIR_Test2 primary key(c1), index ix_ROIR_Test2 nonclustered(c2) ); GO set nocount on insert into dbo.ROIR_Test2 default values; GO 10 alter index ix_ROIR_Test2 on ROIR_Test2 REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
This script delivers the error message, no matter if try a persisted or non-persisted computed columns:
Msg 10644, Level 16, State 1, Line 15 Resumable index operation for index 'ix_ROIR_Test2' failed because the index contains the computed column 'c2' as a key or partitioning column. If this is a non clustered index, the column will be implicitly included as a key column if it is part of the clustered index key.
Disabled Indexes
In the real life, we do disable and enable indexes, especially in the DWH space where before the data loading process speed is almost always of the highest importance.
In the script below I am disabling the ix_ROIR_Test3 index before trying to execute Resumable Online Index Rebuild:
drop table if exists dbo.ROIR_Test3; create table dbo.ROIR_Test3( c1 int identity(1,1) not null, c2 int default(1.23), constraint pk_ROIR_Test3 primary key(c1), index ix_ROIR_Test3 nonclustered(c2) ); GO set nocount on insert into dbo.ROIR_Test3 default values; GO 10 -- Disable the NC index alter index ix_ROIR_Test3 on ROIR_Test3 disable alter index ix_ROIR_Test3 on ROIR_Test3 REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
This attempt will bring another error message saying that the disabled indexes are not supported:
Msg 11434, Level 15, State 1, Line 19 The RESUMABLE option is not supported for the disabled index 'ix_ROIR_Test3' on table 'ROIR_Test3'.
Rebuild ALL
In the real production environment a lot of times one can find the attempts to rebuild all indexes with a single command – ALTER INDEX ALL or ALTER TABLE .. REBUILD
Let’s see if we can get Resumable Online Index Rebuild to function correctly with both of them:
drop table if exists dbo.ROIR_Test4; create table dbo.ROIR_Test4( c1 int identity(1,1) not null, c2 int default(1.23), constraint pk_ROIR_Test4 primary key(c1), index ix_ROIR_Test4 nonclustered(c2) ); GO set nocount on insert into dbo.ROIR_Test4 default values; GO 10
Let’s try ALTER INDEX ALL:
alter index ALL on dbo.ROIR_Test4 REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
The result is quite sad:
Msg 11433, Level 15, State 1, Line 17 'ALTER INDEX ALL' with RESUMABLE option is not suppported on table 'dbo.ROIR_Test4'.
I wonder why this option is not supported.
Multiple indexes tracking is a difficult problem ?
We can’t rebuild them in parallel guaranteeing the same progress, is it ?
I am absolutely fine with indexes being rebuilt in a different order with different progress.
I would be fine if such invocation would start rebuilds for all indexes, instantly pausing them and then carrying on with the first of them.
The pause process is what might have prevented this operation from being implemented so far, since by default as I have shown you above, the connection is shut down for the running SPID and this is something that the developers of this feature are still trying to solve…
But this item is truly important, since no one will want to run through dozens of indexes manually!
alter table dbo.ROIR_Test4 REBUILD WITH ( RESUMABLE = ON, ONLINE = ON );
Msg 155, Level 15, State 1, Line 23 'RESUMABLE' is not a recognized ALTER TABLE option.
Hmmm … Ok … a kind of… :S
Let’s hope that Microsoft will focus on ALTER INDEX ALL first and then will implement the table operation.
Transactions
If you are rebuilding your tables within transactions, you will find that Resumable Online Index Rebuild does not support this option:
BEGIN TRAN ALTER INDEX o_orderdate_ind ON [dbo].[orders] REBUILD WITH ( RESUMABLE = ON, ONLINE = ON, MAXDOP = 1 ); COMMIT TRAN
The error message is quite clear:
Msg 574, Level 16, State 6, Line 3 RESUMABLE INDEX statement cannot be used inside a user transaction.
and I really do not worry about this part right at this moment. I imagine that getting rollbacks right in a complex environment might not be the easiest task and Microsoft wants to evaluate if there are enough people excited about the direction of the Resumable Online Index Rebuild.
I know I am :)
Final Thoughts
Looks like a well thought enhancement for the SQL Server Storage Engine! I am truly excited to start using SQL Server 2017 and Azure SQL Database to take advantage of this functionality.
I am really looking forward to see future iterations and support for the Columnstore Indexes, as well as the missing elements, such as computed columns or TIMESTAMPs (come on, there are enough Microsoft Dynamics family products are heavily depending on that data type!).
The REBUILD ALL options is something that I believe should be fixed before RTM of SQL Server 2017, this might give a functionality a bad name.
I encountered the following error when running Ola Hallengren’s “IndexOptimize – USER_DATABASES” script on a database that was upgraded, following its restore, from 2016 to 2017:
Msg 155, ‘RESUMABLE’ is not a recognized ALTER INDEX REORGANIZE option.
The fix was to manually rebuild the index and then re-run Ola’s script, which executed without error.
Hi Richard,
I guess this is not just a solution specific situation, but a generic requirement. In any case, rebuilding your indexes after upgrade is a desired situation where you will get the new functionalities sometimes only after a rebuild.
Best regards,
Niko
I love how Microsoft Documentation leaves this out.
Hi Kenny,
:) Well, if you wish to contribute – the documentation is on the GitHub :)
Best regards,
Niko
Please here wait_at_low_priority option is still valid , part of online index operation.
Hi Maneesh,
wait_at_low_priority is an option for the online index rebuilds, which is not a resumable functionality. You will be able to SUSPEND TEMPORARY your rebuild by waiting, but not indefinitely and you will not be able to resume this operation after suspending the process.
Best regards,
Niko