Continuation from the previous 56 parts, the whole series can be found at https://www.nikoport.com/columnstore/
In this post I want to focus on a very important aspect of Columnstore Indexes maintenance – Segment Alignment. I have extensively blogged and presented on the matters of the Segment Elimination in the past (Columnstore Indexes – part 34 (“Deleted Segments Elimination”) & Columnstore Indexes – part 29 (“Data Loading for Better Segment Elimination”), for example), but in this post I want to show how to analyse the Segment Alignment, for making the right decision if Columnstore Index is dealigned.
I have already written some of my thoughts about Columnstore Indexes maintenance in Columnstore Indexes – part 36 (“Maintenance Solutions for Columnstore”), but in this post I wanted to focus on the Segment Alignment maintenance.
Notice that this blogpost applies for any SQL Server version starting from 2012 with non-updateable Nonclustered Columnstore Indexes, because basic structure (Compressed Segment) for Columnstore Indexes is available through the sys.column_store_segments DMV, which can be found in every SQL Server version since Columnstore Indexes inception.
The difference in performance of the aligned Segments versus the non-aligned Segments can be huge, because of less Hard Drive involvement. Imagine that your query is reading 100GB of Columnstore Data instead of reading lets say 150GB, or in the very worst case 500GB. You will notice a great performance improvement once you will use it correctly on your Fact Tables, and even if you are applying Columnstore Indexes as Operational Analytics (in SQL Server 2016 for example), the impact can be quite significant, even through just the amount of Data your CPUs will be processing.
Let’s see how the things are functioning in practice and how can we analyse the current Columnstore alignment situation.
My favourite basic test Database ContosoRetailDW is here to support me once again.
I am simply restoring a copy of it, and after upgrading to SQL Server 2014 compatibility level, dropping all Foreign Keys and Primary Key on the test table FactOnlineSales, before creating Clustered Columnstore Index. Notice that this test is executed on SQL Server 2014, but can be adapted for SQL Server 2012,2014,2016 and of course Azure SQLDatabase:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 120
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Now let’s run a simple test query to see how good our Segment Elimination is:
set statistics io on select sum(sales.SalesAmount), count(*) from dbo.FactOnlineSales sales inner join dbo.DimDate dat on sales.DateKey = dat.Datekey where dat.CalendarYear = 2008;
Notice that you will need SQL Server 2014 SP1 or superior to see the results of the segment elimination, as I have already disclosed in Columnstore Indexes – part 53 (“What’s new for Columnstore in SQL Server 2014 SP1”), alternatively you will be able to determine it through the column_store_segment_eliminate extended event – which was described in Columnstore Indexes – part 47 (“Practical Monitoring with Extended Events”).
After executing the query, I have received the following results (filtering out the concrete Reads, which are less relevant for the point I am trying to make):
Table 'FactOnlineSales'. Segment reads 9, segment skipped 5.
For improving the performance of this query I will align Segments of my Columnstore Index on the DateKey column:
create clustered index PK_FactOnlineSales on dbo.FactOnlineSales (DateKey) with (DROP_EXISTING = ON); create clustered columnstore index PK_FactOnlineSales on dbo.FactOnlineSales with (MAXDOP = 1, DROP_EXISTING = ON);
Executing the test query again,
set statistics io on select sum(sales.SalesAmount), count(*) from dbo.FactOnlineSales sales inner join dbo.DimDate dat on sales.DateKey = dat.Datekey where dat.CalendarYear = 2008;
leads us to the following result:
Table 'FactOnlineSales'. Segment reads 5, segment skipped 8.
The main thing here is that we simply went from 9 read Segments to 5 Segments, which means we have improved our IO performance almost 2 times, with the very same data. Cool feature. :)
In the real-life situation we will have a number of updates on daily/weekly basis, and at some point we might need to make decision if the Columnstore Indexes are truly dealigned or they are still finely tuned.
The issue with the Columnstore Indexes in the real life is that the order of the Segments is not guaranteed at all. We can observe Segments appearing in any order possible, and loading data ordered into the table/partition multiple times will make you loose all that perfect order you have created.
Basically in order to detect Segment overlapping we have 2 situations:
1. The minimum value of the compared Segment is between the Min & Max values of the current Segment
2. The maximum value of the compared Segment is between the Min & Max values of the current Segment.
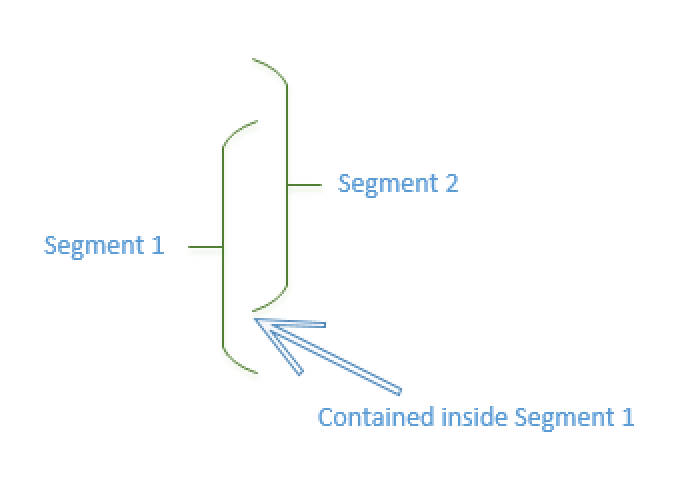
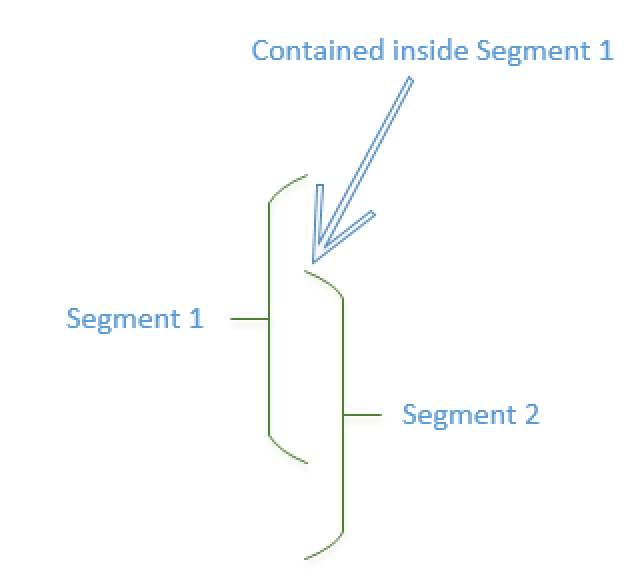
Additionally, I have included the message for the support of the respective datatype for Segment Elimination (you do not want to waste your time aligning on the wrong data type, which shall simply won’t do any Segment Elimination at all).
I could have went much into this beta-version implementation, but at this point it is as simple loop through each of the available Segment in the Table partition and compared its maximum & minimum values.
I understand that it performance can be improved and I promise to post updates for this post very soon. :)
;with cte as ( select part.object_id, part.partition_number, seg.partition_id, seg.column_id, cols.name as ColumnName, tp.name as ColumnType, seg.segment_id, isnull(min(seg.max_data_id - filteredSeg.min_data_id),-1) as SegmentDifference from sys.column_store_segments seg inner join sys.partitions part on seg.hobt_id = part.hobt_id and seg.partition_id = part.partition_id inner join sys.columns cols on part.object_id = cols.object_id and seg.column_id = cols.column_id inner join sys.types tp on cols.system_type_id = tp.system_type_id and cols.user_type_id = tp.user_type_id outer apply (select * from sys.column_store_segments otherSeg where seg.hobt_id = otherSeg.hobt_id and seg.partition_id = otherSeg.partition_id and seg.column_id = otherSeg.column_id and seg.segment_id <> otherSeg.segment_id and ((seg.min_data_id < otherSeg.min_data_id and seg.max_data_id > otherSeg.min_data_id ) -- Scenario 1 or (seg.min_data_id < otherSeg.max_data_id and seg.max_data_id > otherSeg.max_data_id ) -- Scenario 2 ) ) filteredSeg group by part.object_id, part.partition_number, seg.partition_id, seg.column_id, cols.name, tp.name, seg.segment_id ) select object_name(object_id) as TableName, partition_number, cte.column_id, cte.ColumnName, cte.ColumnType, case cte.ColumnType when 'numeric' then 'Segment Elimination is not supported' when 'datetimeoffset' then 'Segment Elimination is not supported' when 'char' then 'Segment Elimination is not supported' when 'nchar' then 'Segment Elimination is not supported' when 'varchar' then 'Segment Elimination is not supported' when 'nvarchar' then 'Segment Elimination is not supported' when 'sysname' then 'Segment Elimination is not supported' when 'binary' then 'Segment Elimination is not supported' when 'varbinary' then 'Segment Elimination is not supported' when 'uniqueidentifier' then 'Segment Elimination is not supported' else 'OK' end as TypeSupport, sum(case when SegmentDifference > 0 then 1 else 0 end) as DealignedSegments, count(*) as TotalSegments, cast( sum(case when SegmentDifference > 0 then 1 else 0 end) * 100.0 / (count(*)) as Decimal(6,2)) -- -1 because of the first segment which has no difference to the previous one as SegmentDealignment from cte group by object_name(object_id), partition_number, cte.column_id, cte.ColumnName, cte.ColumnType order by object_name(object_id), partition_number, cte.column_id;
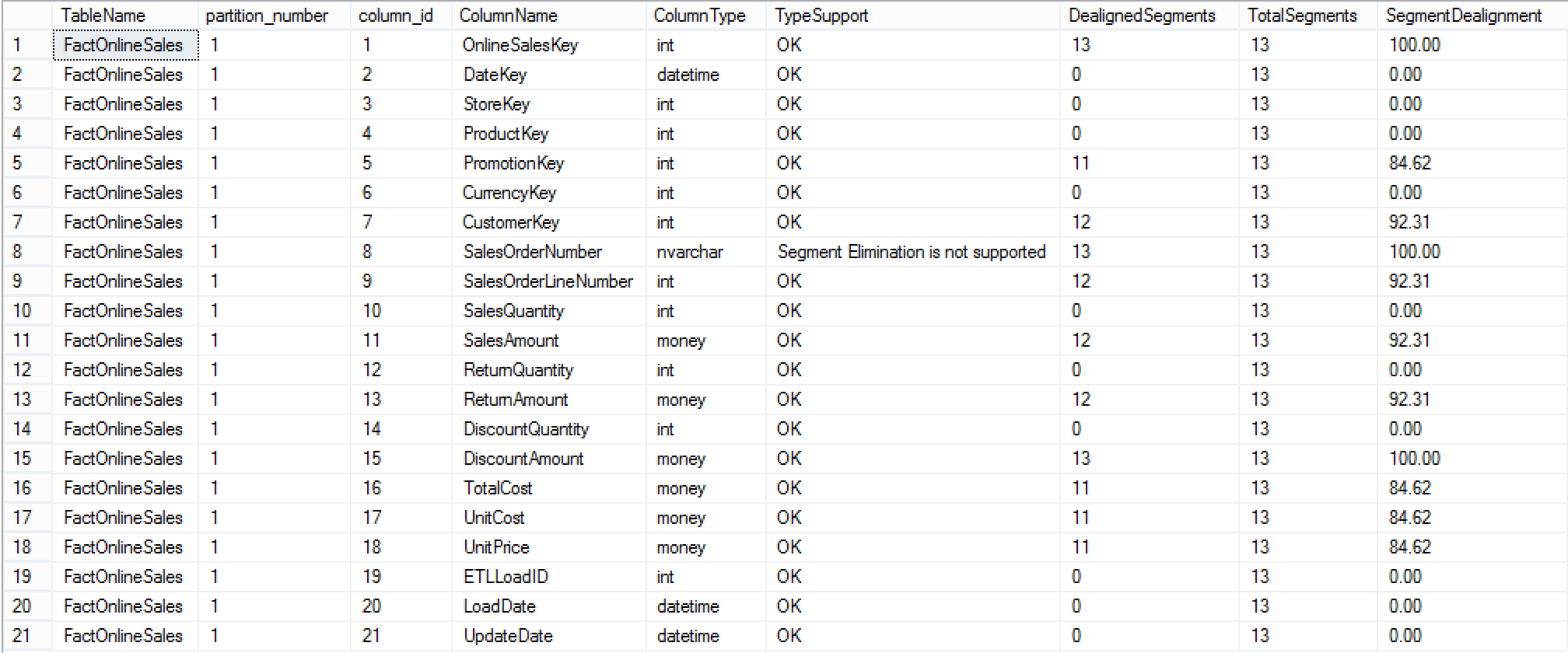 Here is the result of this query, which shows Segment Dealignment for each of the available columns in my FactOnlineSales table. You can clearly see which columns Segments are 100% aligned, which are totally overlapping and which you should not care about.
Here is the result of this query, which shows Segment Dealignment for each of the available columns in my FactOnlineSales table. You can clearly see which columns Segments are 100% aligned, which are totally overlapping and which you should not care about.
You can try to order the Segments on the different column and re-execute the script to see what combination and alignment percentage it will show.
Feel free to play with this script and let me know about the results.
to be continued with Columnstore Indexes – part 58 (“String Predicate Pushdown”)
Hi Niko,
There is actually a simpler way to detect overlapping segments. Key is to first think about the scenario’s of non-overlapping: either the other segment ends before the current segment starts, or the other segments starts after the current segment ends. All other scenarios are then overlap.
In T-SQL terms, the condition for overlap can be written as
WHERE seg.hobt_id = otherSeg.hobt_id
AND seg.partition_id = otherSeg.partition_id
AND seg.column_id = otherSeg.column_id
AND seg.segment_id otherSeg.segment_id
AND seg.min_data_id otherSeg.min_data_id
I expect this to perform a bit better as well (but you’ll need a REALLY huge table before you get so many rows in sys.column_store_segments that you will notice the difference)
Hey Hugo,
Interesting. Currently in the CISL, the algorithm used is different to the one posted originally in this blog post. Looking at your suggestion I would guess that they are equal or extremely similar. :)
I start to believe, I should go back to my elder posts and update them – but generally I am too lazy for that.
Best regards,
Niko Neugebauer
Thank you for your article.
When you drop the existing index to create the clustered (Rowstore) index on DateKey, that is to reorder the physical data by the DateKey right?
In my own environment for some reason, when I follow this step with dropping the index and creating the columnstore index, I am not achieving the segment alignment as you have. In fact I have 90 to 100 dealignment, even though I am first creating a clustered index. Can you recommend what I look into?
Hi Alex, please check the following :
– are you using MAXDOP 1 ?
– is there enough memory ?
– is there a dictionary pressure for the table ?
Best regards,
Niko Neugebauer
Yes, I did notice that for higher DOP than 1 then the CCI build will not keep the ordering, thank you for writing about that. I have no dictionaries and I did set MAXDOP = 1, so memory may be where I’m having a problem – I only have 8GB.
Run the Extended Event “column_store_index_build_throttle” to see if you being throttled because of the lack of memory.