Continuation from the previous 11 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
In the previous blog posts of this series on Clustered Columnstore Indexes, we have created some Clustered Columnstore Indexes and NonClustered Columnstore Indexes, we have compared different type of compressions and we have even considered some of the internals of the Columnstore Indexes. Now it is time to play with some data and see how what we can actually see and discover by looking at the internal information of the SQL Server 2014 CTP 1.
Once again, in order to play with the scripts you need to download and restore the Contoso BI Database. As in the previous post, I am dropping all the foreign and primary keys in order to be able to start creating Columnstore Indexes :
-- Drop all Foreign Keys ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimAccount] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimCurrency] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimDate] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimEntity] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimProductCategory] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimScenario] -- Drop the Primary Key ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [PK_FactStrategyPlan_StrategyPlanKey]
Now lets create a Clustered Columnstore Index and let us see what we can see inside of the Columnstore related DMV’s:
-- Create Clustered Columnstore Index Create Clustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan WITH (DATA_COMPRESSION = COLUMNSTORE); -- Get the dictionaries select * from sys.column_store_dictionaries -- Get the Segments select * from sys.column_store_segments -- Get all the Row Groups select * from sys.column_store_row_groups
Here are the screenshots of the respective results, already placed in the Excel tables:
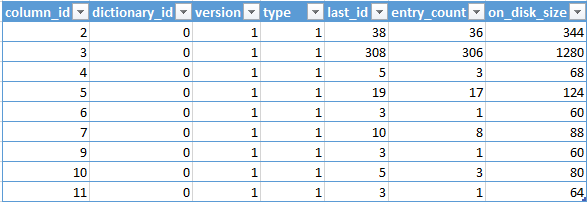
Dictionaries:
Column Store Segments:
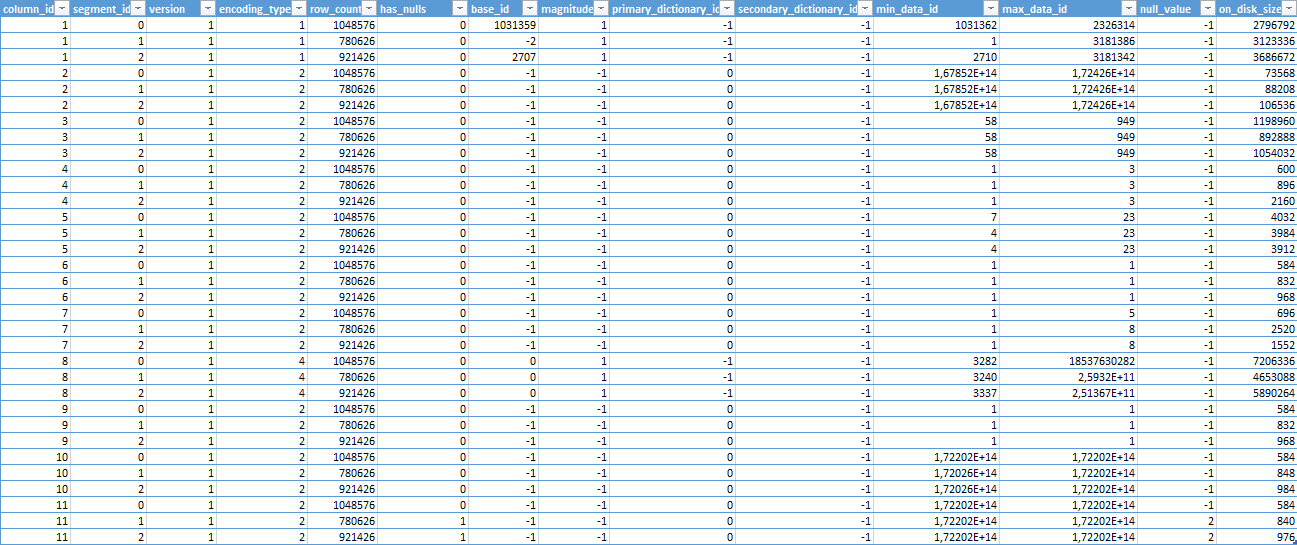
Row Groups:
![]()
What can we see there ? From 11 columns available inside of the dbo.FactStrategyPlan table, only 9 columns have deserved their right to have a dictionary. The very first columns is an Integer Identity and so far I have seen, Columnstore Indexes does not create any dictionaries for this types of columns. Another columns which did not receive any dictionary was a column Number 8, which has a MONEY datatype. At this point lets just remember it and move forward.
The second DMV returns us information about data distribution between compressed Segments. We can see that the columns 1 & 8 don’t have any primary (I assume that it means a global dictionary) dictionaries associated. Notice, that no Columns have any secondary dictionary at all (I assume that this means a local dictionary).
The last of the 3 consulted views (sys.column_store_row_groups) is showing us information about all available Row Groups, and in our case they are all compressed Segments.
That is all fine, but what about the NonClustered Columnstore Indexes ? Lets create the very same covering Nonclustered Columnstore Index, which will include every column of the table and see what the SQL Server DMV’s will show us:
-- Drop existing Clustered Index Drop Index PK_FactStrategyPlan on dbo.FactStrategyPlan; -- Create a Nonclustered Columnstore Index: Create NonClustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan (StrategyPlanKey, Datekey, EntityKey, ScenarioKey, AccountKey, CurrencyKey, ProductCategoryKey, Amount, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); -- Get the dictionaries select * from sys.column_store_dictionaries -- Get the Segments select * from sys.column_store_segments -- Get all the Row Groups select * from sys.column_store_row_groups
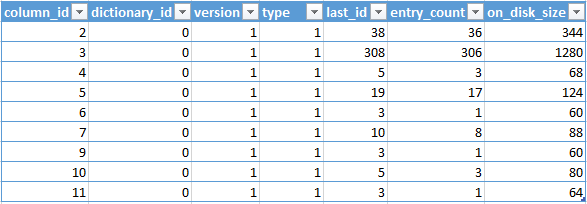
Dictionaries:
Column Store Segments:
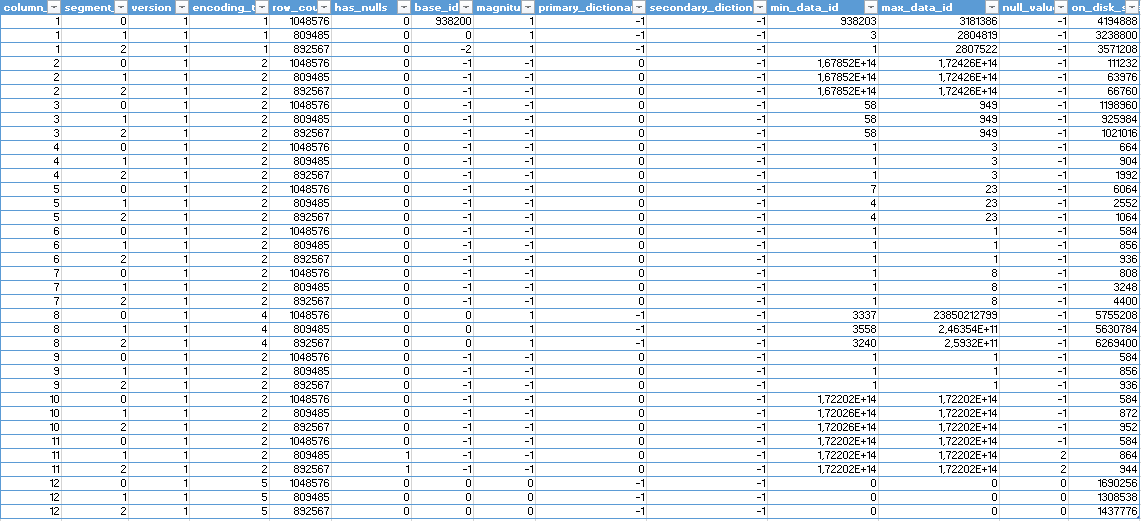
Row Groups:
![]()
The results from the DMV’s of the Nonclustered Columnstore Index are very self-explanatory: The dictionaries are absolutely identical, and so from here I assume that the data analysis is the very same process that has been used for the Clustered Columnstore Indexes.
The segments are different to the Clustered Columnstore Indexes: first of all we have a 12th column, which actually does not exist in the original table. What does it serve for ? In our case this is a unique identifier to serve as a connection between the clustered and so is the occupied space, like there is one for the traditional Nonclustered Indexes build on a HEAP.
Naturally the Row Groups DMV is showing us the aggregated info which is involving all Segments, because we don’t have any other type of the Row Groups.
Important Observation: at this point it is quite visible that the dictionary is exactly the same but what it looks like the compression itself is different, but let’s not forget that we are dealing with a HEAP table in the case of the Nonclustered Columnstore Index. To get a better insight, let’s do the whole process from the start, this time creating a traditional Clustered Index with a Nonclustered Columnstore Index and then compare it to a freshly created Clustered Columnstore Index:
-- Drop existing Columnstore Index
Drop Index PK_FactStrategyPlan on dbo.FactStrategyPlan;
-- Create a traditional Unique Clustered Index
create clustered Index PK_FactStrategyPlan
on dbo.FactStrategyPlan (StrategyPlanKey ASC)
WITH ( DATA_COMPRESSION = PAGE);
-- Create a Nonclustered Columnstore Index:
Create NonClustered Columnstore Index NC_PK_FactStrategyPlan
on dbo.FactStrategyPlan (StrategyPlanKey, Datekey, EntityKey, ScenarioKey, AccountKey, CurrencyKey, ProductCategoryKey, Amount, ETLLoadID, LoadDate, UpdateDate)
WITH ( DATA_COMPRESSION = COLUMNSTORE);
-- Get the dictionaries
select *
from sys.column_store_dictionaries
-- Get the Segments
select *
from sys.column_store_segments
-- Get all the Row Groups
select *
from sys.column_store_row_groups
As expected, the dictionaries stays the same – untouched.
For the sys.column_store_segments DMV – also, as expected the 12th columns is completely gone and the results are quite different: 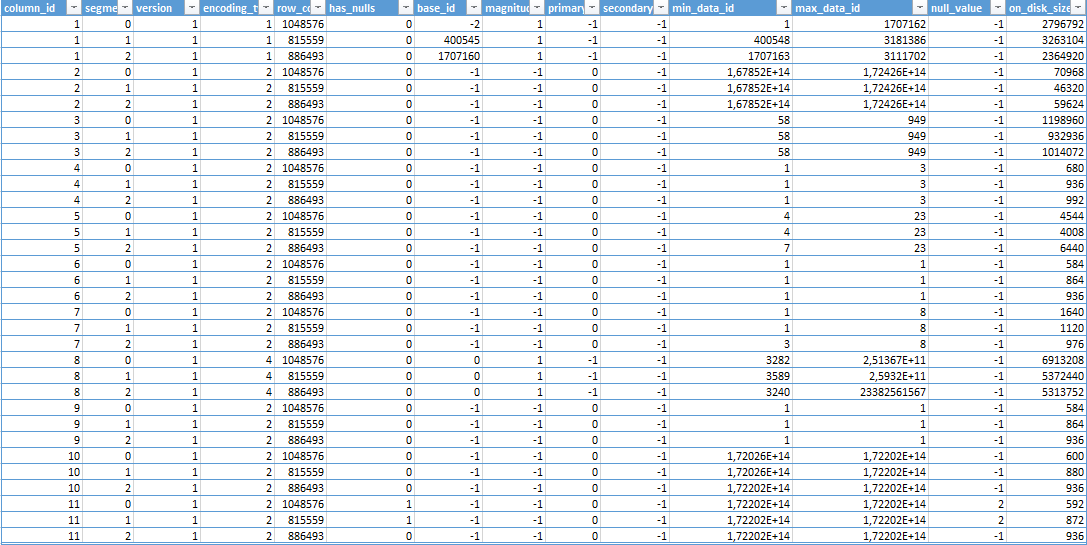 The compression results are much better, which definitely should be attributed to the sorted order of the data, since we have built a traditional Clustered Index before creating a Nonclustered Columnstore one.
The compression results are much better, which definitely should be attributed to the sorted order of the data, since we have built a traditional Clustered Index before creating a Nonclustered Columnstore one.
Lets run the following script to create a Clustered Columnstore to compare the results with the combination of the traditional Clustered Index + Nonclustered Columnstore Index:
-- Drop Nonclustered Columnstore Index: Drop Index NC_PK_FactStrategyPlan on dbo.FactStrategyPlan; -- Create Clustered Columnstore Index Create Clustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE); -- Get the dictionaries select * from sys.column_store_dictionaries -- Get the Segments select * from sys.column_store_segments -- Get all the Row Groups select * from sys.column_store_row_groups
The results are absolutely equal, which makes perfect sense. At this point I am quite confident that this combination (Clustered + Nonclustered_Columntore = Clustered_Columnstore). Viewing the results of the DMVs proves that in my opinion. I have tried a couple of other tables and always have obtained the exact results.
At this point I decided to turn my attention to the new type of compression that exists in the SQL Server 2014 CTP1 – Columnstore Archive:
-- Create a traditional Unique Clustered Index
create unique clustered Index PK_FactStrategyPlan
on dbo.FactStrategyPlan (StrategyPlanKey ASC)
WITH (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE);
-- Create Clustered Columnstore Index
Create Clustered Columnstore Index PK_FactStrategyPlan
on dbo.FactStrategyPlan
WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);
-- Get the dictionaries
select *
from sys.column_store_dictionaries
-- Get the Segments
select *
from sys.column_store_segments
-- Get all the Row Groups
select *
from sys.column_store_row_groups
Here are the results, already stacked with the comparison between Columnstore and Columnstore Archive compression:
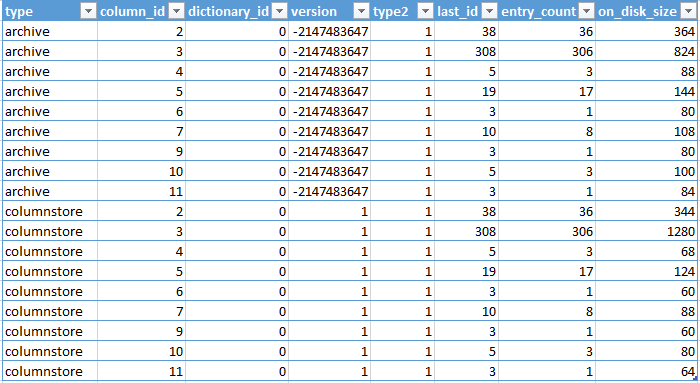
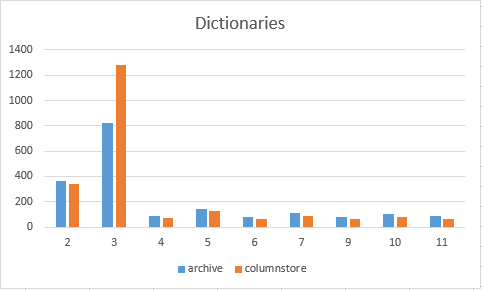
Analysis: The Columnstore Archival process is not only just a modified LZ77 compression. The dictionary size is clearly differs from the default Columnstore compression. In the case of the Columnstore Archive compression, for the majority of the columns the size of the dictionary is somehow bigger then in the default Columnstore compression by the precise amount of 20 bytes. The only case when the Columnstore dictionary is bigger then the Columnstore Archive – is the column number 3: EntityKey int. The difference is so significant in this case, that there is something going on and at this point I am not sure what exactly is. I am definitely looking forward into trying to get a look into the dictionary values to understand this difference. This column is an Integer, which in a lot of cases does not get any dictionary at all, but since we have just 306 distinct values it is clearly a column that can get a good compression.
 If we look at the compressed segments we can also clearly notice the difference in the way that the data has been shuffled between the Segments. I can only guess, that some of the difference in the compression is achieved by this move of the data between different Segments. We shall see ;)
If we look at the compressed segments we can also clearly notice the difference in the way that the data has been shuffled between the Segments. I can only guess, that some of the difference in the compression is achieved by this move of the data between different Segments. We shall see ;)
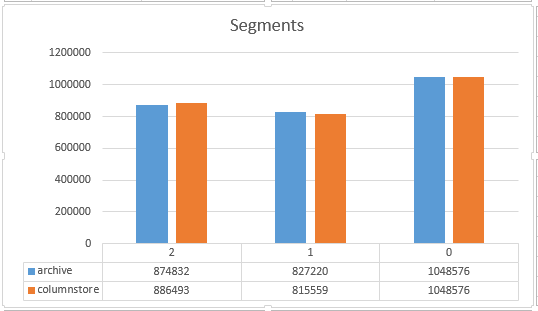
Row Count for each of the Segments:
to be continued with Clustered Columnstore Indexes – part 13 (“Dictionaries Analyzed”)
Pingback: Clustered Columnstore Indexes – part 1 (“Intro”) | Nikoport
Hi Niko,
First of all, I would like to say a big Thank you for all great posts.
I was following this part and I’ve seen that on SQL Server 2017 creating a traditional clustered b-tree and nonclustered columnstore by reviewing both dictionaty&store segments I am seeing the column 12th displayed as result whereas in your post with SQL 2014 they were missing.
Right now, I do not have handy and SQL2014 instance to test it out. Do you know if this is expected to happen?
Florin