Continuation from the previous 94 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
I have been wanting to write on this topic for quite some time, but with all the exciting themes that I have on my todo list and as drafts on this blog post, prevented me until today – when I finally decided to put a couple of words and a rather simple test for the Columnstore Indexes partitioning, especially since one of the next blog posts will be dedicated to this topic in even bigger details.
Partitioning – the unsung hero of the Columnstore Indexes, one of the most essential elements for the success when using Columnstore Indexes. Rebuilding multiple billion rows table is a daunting task that even the bravest of the DBAs will not (or SHOULD NOT) take easy.
With so many incredible changes, improvements and additions in SQL Server 2016, was there something under the hood, hiding from the public eye? Something that nobody thought was worth mentioning? Something that can improve performance of the huge tables ?
Anything ?
Anything at all ?
Let’s do a quick test between 2 equal instances of SQL Server 2014 and SQL Server 2016. I will use my own generated copy of the TPCH database (1GB version), that I have done with the help of the HammerDB (free software).
Notice that to do a proper comparison, set the compatibility level to 120, even when working with SQL Server 2016:
/*
* This script restores backup of the TPC-H Database from the C:\Install
*/
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1gb_new.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
-- SET Compatibility level to 120, even when working with SQL Server 2016
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 120
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
To make results more visible, we shall need to go a little bit “crazy” with partitioning, creating daily partitioning for the 6 Million Rows table with just 2375 rows per partition on average, like I did it in Columnstore Indexes – part 94 (“Use Partitioning Wisely”):
DECLARE @bigString NVARCHAR(MAX) = '', @partFunction NVARCHAR(MAX); ;WITH cte AS ( SELECT CAST( '1 Jan 1992' AS DATE ) testDate UNION ALL SELECT DATEADD( day, 1, testDate ) FROM cte WHERE testDate < '31 Dec 1998' ) SELECT @bigString += ',' + QUOTENAME( CONVERT ( VARCHAR, testDate, 106 ), '''' ) FROM cte OPTION ( MAXRECURSION 5000 ) SELECT @partFunction = 'CREATE PARTITION FUNCTION fn_DailyPartition (DATE) AS RANGE RIGHT FOR VALUES ( ' + cast(STUFF( @bigString, 1, 1, '' )as nvarchar(max)) + ' )' EXEC sp_Executesql @partFunction CREATE PARTITION SCHEME ps_DailyPartScheme AS PARTITION fn_DailyPartition ALL TO ( [PRIMARY] );
Now let's add a copy of the original table lineitem, by building a Clustered Columnstore Index on a new table lineitem_cci (notice that I am running the same script on the 2014 & 2016 SQL Server versions):
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
GO
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
After that we shall need to build a partitioned table lineitem_cc_parti on both SQL Server 2014 & SQL Server 2016:
USE [tpch]
GO
CREATE TABLE [dbo].[lineitem_cci_part](
[l_shipdate] [date] NULL,
[l_orderkey] [bigint] NOT NULL,
[l_discount] [money] NOT NULL,
[l_extendedprice] [money] NOT NULL,
[l_suppkey] [int] NOT NULL,
[l_quantity] [bigint] NOT NULL,
[l_returnflag] [char](1) NULL,
[l_partkey] [bigint] NOT NULL,
[l_linestatus] [char](1) NULL,
[l_tax] [money] NOT NULL,
[l_commitdate] [date] NULL,
[l_receiptdate] [date] NULL,
[l_shipmode] [char](10) NULL,
[l_linenumber] [bigint] NOT NULL,
[l_shipinstruct] [char](25) NULL,
[l_comment] [varchar](44) NULL
)
GO
-- Create Clustered Index
create clustered index cci_lineitem_cci_part
on dbo.lineitem_cci_part ( [l_shipdate] )
WITH (DATA_COMPRESSION = PAGE)
ON ps_DailyPartScheme( [l_shipdate] );
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci_part
on dbo.lineitem_cci_part
WITH (DROP_EXISTING = ON)
ON ps_DailyPartScheme( [l_shipdate] );
-- Load the Data
insert into dbo.lineitem_cci_part (l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
FROM [dbo].[lineitem_cci]
To make sure that we are dealing with only compressed segments, let's force the closure and compression of all Delta-Stores, by executing the following statement:
alter index cci_lineitem_cci_part on dbo.lineitem_cci_part reorganize with (COMPRESS_ALL_ROW_GROUPS = ON);
As the next step, I will use my CISL open source library to show the details on both of the partitioned tables, in order to ensure their equality:
EXEC dbo.cstore_GetRowGroups @tableName = 'lineitem_cci_part';
![]()
On my instances their look equal like I presented on the picture above with 0.12GB of space occupied and the 2528 different Row Groups :)
First let's run the test query, that I have built, against the basis table containing Clustered Columnstore Index, but that was not partitioned:
select TOP 10 l_discount, SUM(l_discount * 1.123) as TotalDiscount from dbo.lineitem_cci where l_shipdate <= '1998-01-01' group by l_discount order by TotalDiscount desc
I have observed some incredible results here, and here they are:
CPU time = 640 ms, elapsed time = 186 ms. CPU time = 657 ms, elapsed time = 175 ms.
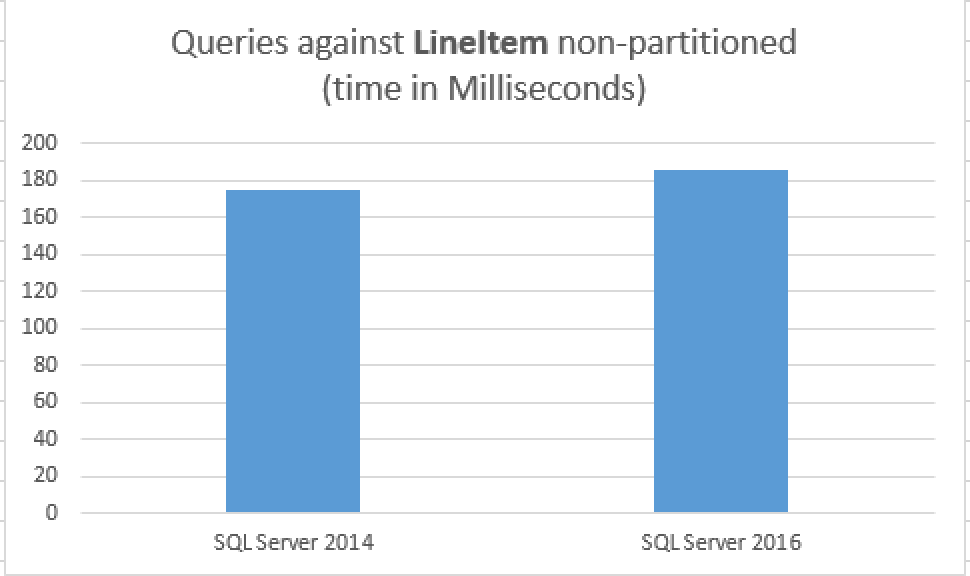 One of the lines corresponds to the SQL Server 2014, while the other corresponds to the SQL Server 2016. The numbers on my VM were pretty much constant, with some not so positive variations in the favour of SQL Server 2014 - I say because of the simpler structure.
One of the lines corresponds to the SQL Server 2014, while the other corresponds to the SQL Server 2016. The numbers on my VM were pretty much constant, with some not so positive variations in the favour of SQL Server 2014 - I say because of the simpler structure.
Well, 186ms was the average result on SQL Server 2016 running under the 2014 compatibility level while 175ms of the total elapsed time was for the SQL Server 2014!
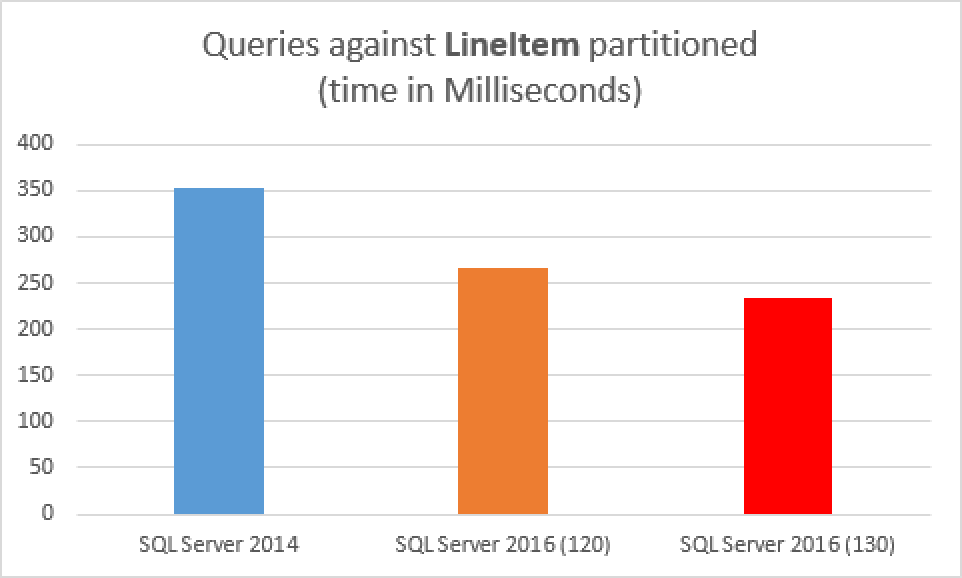
Now, let's re-run the query, but this time against both SQL Server 2014 & SQL Server 2016 with their fully partitioned tables:
select TOP 10 l_discount, SUM(l_discount * 1.123) as TotalDiscount from dbo.lineitem_cci_part where l_shipdate <= '1998-01-01' group by l_discount order by TotalDiscount desc
What about now ? Which result belongs to which SQL Server?
CPU time = 951 ms, elapsed time = 266 ms. CPU time = 1061 ms, elapsed time = 353 ms.
 266ms was the partitioned table under SQL Server 2016 (compatibility level 120) while 353ms of the total elapsed time was obtained on SQL Server 2014! This represents a solid 25% improvement
266ms was the partitioned table under SQL Server 2016 (compatibility level 120) while 353ms of the total elapsed time was obtained on SQL Server 2014! This represents a solid 25% improvement
All execution plans will have the same iterators, but will differ on the overall estimated cost (the non-partitioned queries will be way lower than the partitioned ones), as well as the distribution of the estimated costs within the execution plan, but as for the rest - it will be quite similar, like the one shown on the image below:

One more thing - what about Compatibility Level 130 on SQL Server 2016?
Making sure that there is no mistake, I wanted to see how the query are performing when we enable the 2016 compatibility level (130):
USE [master] GO ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 130 GO
Running the very same queries, obtains better results, as you can see on the images below:
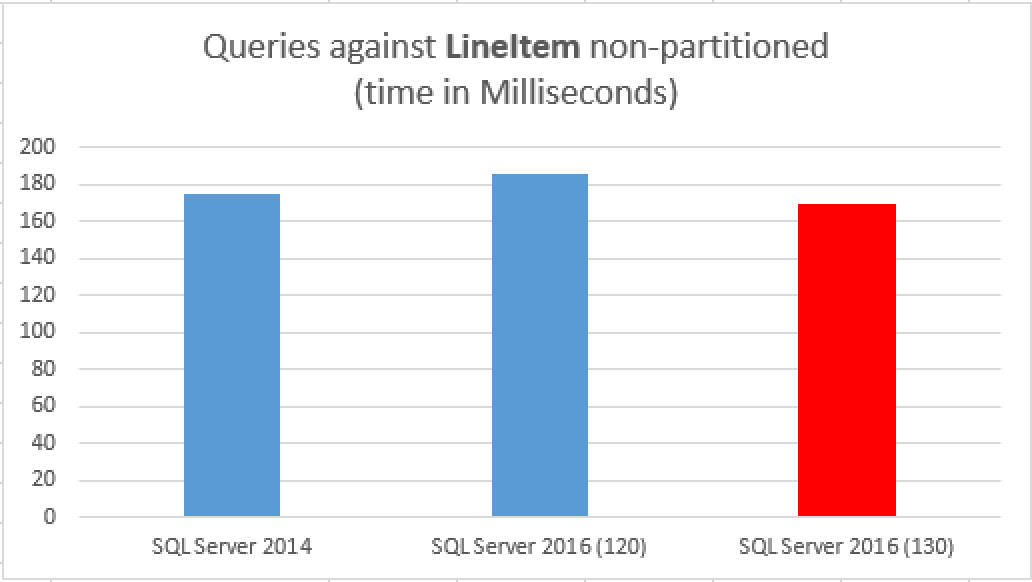
One of the reasons that we shall instantly notice is that the actual execution plan for the queries will suffer some changes, including TOP SORT(N) iterator running in the batch execution mode, for example:

From this point you can take is that 2016 really runs faster, especially if you are using it's newest features :)
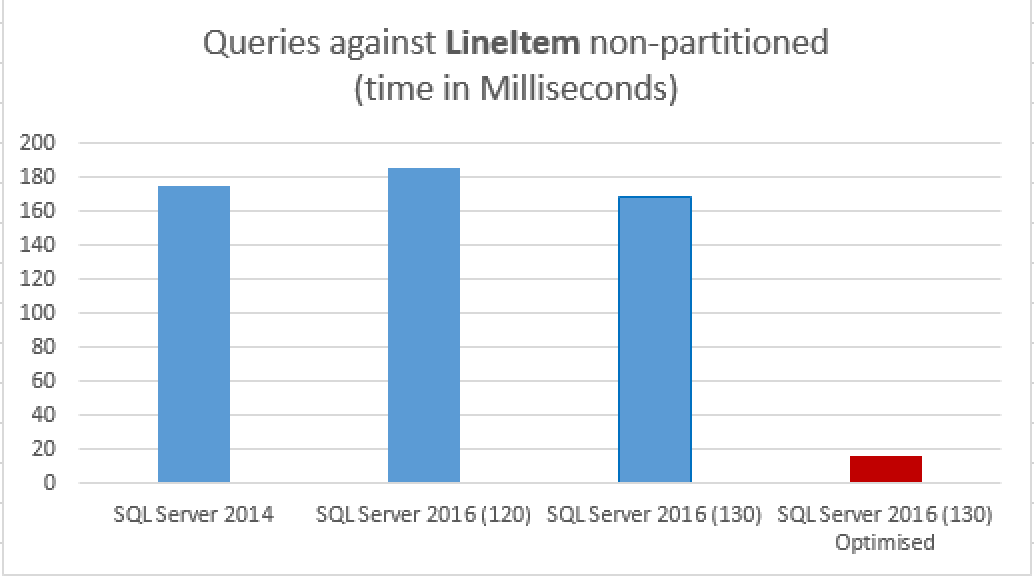
Oh, but there is one more thing: let's change a bit the query (that was written in the way to prevent some of the more advanced features of SQL Server 2016) and run it again:
set statistics time, io on set nocount on select TOP 10 l_discount, SUM(l_discount) * 1.123 as TotalDiscount from dbo.lineitem_cci_part where l_shipdate <= '1998-01-01' group by l_discount --having SUM(l_discount) > 2500. order by TotalDiscount desc select TOP 10 l_discount, SUM(l_discount) * 1.123 as TotalDiscount from dbo.lineitem_cci where l_shipdate <= '1998-01-01' group by l_discount order by TotalDiscount desc
The actual execution plan is presented below:

and the total elapsed time are:
126 ms for the partitioned table
16 ms for the non-partitioned table.
Yes, the difference is that big and that is a common thing if you take advantage of the Aggregate Predicate Pushdown in SQL Server 2016!
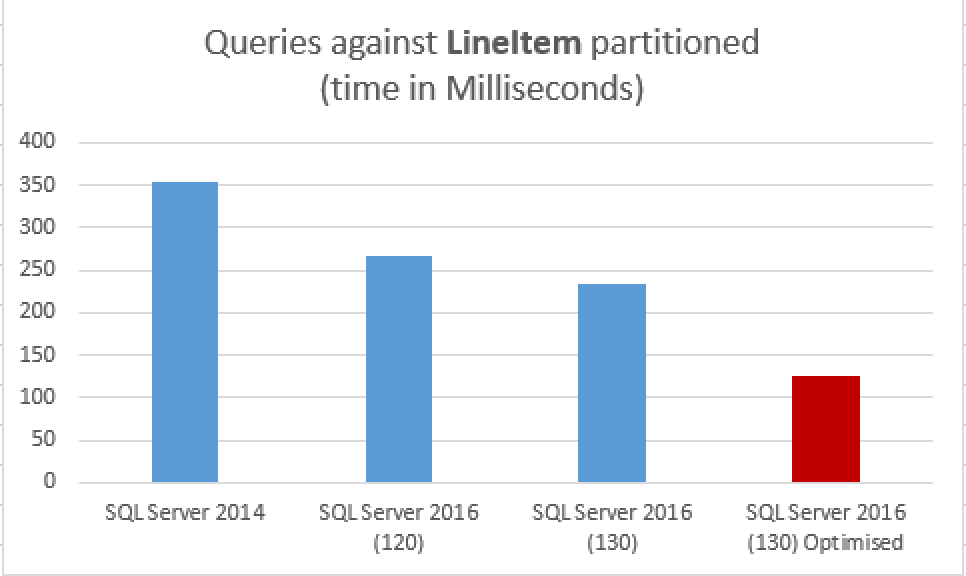
Just runs faster
There have been some smaller but important improvements in the way the Columnstore Indexes partition access is being processed in SQL Server 2016 and if you migrate from SQL Server 2014 to SQL Server 2016, and you are using partitioning very heavily, you should be able to notice the positive difference. I can't estimate if it will be 5% or 25% or 55%, but if you are working with Partitioning (and you SHOULD) - and there are a lot of them, then you might see some measurable improvements.
According to Sunil Agarwal who was the Program Manager responsible for the SQL Server 2016,
the switching to eliminated partitions during scan has been removed, because in SQL Server 2014 the switch to every partition took place, regardless if it would be scanned or not.
This is one little, but an important improvement for the SQL Server 2016 that was not hailed before to my knowledge, and I thought that showing it might help someone to make the right decision about SQL Server 2016 migration.
to be continued with Columnstore Indexes – part 104 (“Batch Mode Adaptive Joins”)
Please here I have 1 query: If partitioning enabled, will deltastore be in each partition for partitioned columnstore Index
Hi BhavyaArora,
yes, you will have one Delta-Store in each of your partitions, where you load or modify data.
Best regards,
Niko
Hi Niko, I read your blogs constantly as they are excellent and this one is a great start to a good subject. I’ve utilized your tips with temp tables heavily and I appreciate the knowledge you’ve given us. Per the this article from Microsoft, https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-partition, “When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed.” With this being said, I’m not sure the test that you’ve done above really represents columnstore properly as they were created for much larger environments. Also, the execution plans tend to vary as the quantities and sizes increase. In case it happens to hit a merge join, then we have the following related bug in at least SQL Server 2014 and 2016. This bug in my opinion renders SQL Server 2014 and 2016 both still beta version in the year 2018. It involves merge joins that exist in conjunction with parallel plans. This was discovered in SS 2016 and exists in at least 2014 also, although they don’t admit to 2014. It is a terrible bug that can bring the execution to its knees… dropping a simple query to hours or days, while the DBAs scratch their heads trying to figure what the problem is. They originally repaired it, which caused another bug and then to repair that bug, they disabled it in their latest CU (7). Now we are stuck putting hash joins everywhere which totally messes up optimization. I have no doubt this also exists in 2017 but I haven’t tested it yet. They are not taking this bug seriously enough. Warning to all, if you are having serious performance problems, check to see if you have merge joins in your execution plan that involves parallelism in any way, and either change your query to remove it or force hash and loop joins. This issue may go all the way back to 2008. They also have data corruption bugs with cs indexes.
The fact is we’ve been sadly let down by Microsoft’s implementation of columnstore indexes (and in memory tables) in SQL Server (and some outrageous bugs) for quite some time (six years now). Their marketing department has pushed the product to a high plateau, however CIs should have never been released in 2012 and I still consider the whole concept beta-ish in 2016 as they are hardly usable considering the heavy costs of using them in a data warehouse (which is where they are supposed to be advantageous). I myself, am tired of telling employers how much they will benefit by the next version of SQL Server, only to be mostly let down. Partitioning and parallelism are perhaps the best things they’ve done for the warehouse. I deal with tables that have billions of rows in them and the fact is that columnstore indexes have no place in these environments unless you have several days to wait for the indexes to be built. If you try to insert or update a table this large, the time to update the cs indexes is ridiculous. Once they repair this issue and the bugs mentioned above, SQL Server should be a great product. I can tell you our organization will not even consider 2017 or further until these bugs are repaired. I really don’t like to be this negative, but its many years of being disappointed by this product. Here’s an example why. Our department gets dinged on bonuses if a warehouse load goes over a specific time. Microsoft bugs have caused the entire department to lose bonus money. This is not a very popular thing with these people and they look to remove causes of these types of things, including product replacement, such as with Oracle or freeware versions. Our paid support from Microsoft has yielded nothing better than acknowledgement that we are experiencing the bugs and unacceptable options to do workarounds.
Keep up the great work and warmest regards Niko
Hi Paul,
Did you tried to speak with Product Managers from Microsoft ?
I am sure they will be interested to fix some of the stuff you mentioned. Some of the problems you are mentioning are definitely known, but do you have some Support Tickets, Connect Items (or now User Voice Items) that you can share.
I would like to help out by bridging out contacts to the people I know within Product Group. I believe that they are interested making product work for you.
Best regards,
Niko
Apparently they solved your issue…
https://support.microsoft.com/en-us/help/4046858/fix-parallel-query-execution-plan-with-a-merge-join-slow-to-execute-in
Hi Olivier,
I guess that it is a different thing – the bug fix you are referring is a MERGE skewing problem.
Best regards,
Niko
Paul,
I would like to know more about the issue that you are referring to. Could you please share the details using the contact form at http://aka.ms/sqlserverteam. I would like to work directly to understand the issue and see how best we can address them
Regards,
Amit
Hello,
From my experience with partitions, when you use : where l_shipdate <= '1998-01-01', Sql server will not use partition elimination and still continue to scan the table. This for a "simple" reason. For optimisation, sql server use parameter sniffing and so will generate a generic plan that cannot contain the elimination. This is the reason why the queries are not performing well. Of course with a good server and a good ssd drive, you don't see the effect until you have some billions rows. It took me 6 months to see that the server was scanning the whole table…
The only "trick" I found to get partition elimination is to cast the parameter in the where clause…
So here, where l.shipdate <= cast('1998-01-01' as date). In that case sql will generate a trivial plan that will use partition elimination and your query will be fast.
As soon as you are using partition, if you don't use the partition column in your where clause with the "anti-sniffing trick", you will end up with scaning of all partition…
Unfortunately, I saw recently that sqlserver 2017 still behaves the same way. We can disable parameter sniffing, but in that case it will be for every queries in your database and it doesn't avoid the partition elimination problem…
I don't see yet the real interest of a columnar index partitionned as we always need the partition column in the query and cannot use other indexes efficiently. The only way would be to switch the data we want to work with and then use the other index. As we have in that case only few partitions, the work would be fast.
The other problem with columnar indexes is that they are not unique and so we exposes the table to duplicates…
A trick to work on that should have a partitoned IN table that contains a unique row index and then to switch data into the main table…
Hi Olivier,
Thank you for sharing!
Best regards,
Niko
you are welcome