Continuation from the previous 80 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Microsoft is doing an amazing job with the every single point release towards SQL Server 2016 RTM. For almost a year, every single month they have released CTPs (Community Technology Previews), improving the current capabilities of the SQL Server and allowing the clients to accompany the product growth and perfecting the upcoming release.
I am writing these praising words, because I have accompanied the path of evolution of the InMemory solution and because finally I am really happy about it.
I have not written a lot about InMemory Operational Analytics previously, mostly because I have been waiting for the RC & RTM versions, since the previous CTP releases have had a number of serious limitations – but hey, what would you expect from the work-in-progress releases.
For the tests of the newest improvements, I have taken the RC 1 (Release Candidate 1) of SQL Server 2016 and the free ContosoRetailDW database.
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
One of the key features that were added in the first Release Candidate of SQL Server 2016 is the capability to add and remove the columnstore index after creating the InMemory table.
Quite normal feature by itself, which would anyone expect from a solid release – that’s for sure, but for anyone working & experimenting with previous release for sure was anxious to see the previous limits of the test version removed.
As we have learned in SQL Server 2012 with the Nonclustered Columnstore Indexes, the capability of adding and dropping the columnstore indexes can be very important and I am confident that there will be enough applications going through the upgrade that will still use the old technique described in Columnstore Indexes – part 79 (“Loading Data into Non-Updatable Nonclustered Columnstore”).
Modifying InMemory table comes with a big costs – we have to have at least the same amount of free memory available, as the space, which is occupied by the original table plus all its modifications. This means that under the hood the InMemory table data is being copied over to a new structure. What would that mean for adding a Columnstore Index ? How fast would it be?
Let’s start the test by adding the Memory Optimised File Group to our test database:
ALTER DATABASE [ContosoRetailDW] ADD FILEGROUP [ContosoRetailDW_Hekaton] CONTAINS MEMORY_OPTIMIZED_DATA GO ALTER DATABASE [ContosoRetailDW] ADD FILE(NAME = ContosoRetailDW_HekatonDir, FILENAME = 'C:\Data\xtp') TO FILEGROUP [ContosoRetailDW_Hekaton];
For the further tests, I will use 2, 4 & 6 Million Rows from the dbo.FactOnlineSales table into the test InMemory tables, measuring then the time for adding other Hash & Columnstore indexes. Notice that in the sample below I have prepared the buckets for the Primary Key Nonclustered Index for 2 million rows, but the structure I have used for the tests, has always accompanied the executed scenario:
CREATE TABLE [dbo].[FactOnlineSales_Hekaton]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, Constraint PK_FactOnlineSales_Hekaton PRIMARY KEY NONCLUSTERED HASH ([OnlineSalesKey]) WITH (BUCKET_COUNT = 2000000) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Now, let’s load 2 million rows into this table:
insert into dbo.FactOnlineSales_Hekaton select top 2000000 * from dbo.FactOnlineSales;
Before any advances with adding a new index to the table, I have executed checkpoint operation, forcing the the clearance of the transaction log:
Checkpoint;
I have rebuilt the table completely after each of the tests, adding a Clustered Columnstore in measuring the time for the operation.
set statistics time, io on alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE;
Now, after rebuilding the whole table right from the beginning, I have added a Nonclustered Hash index, instead of the columnstore one:
set statistics time, io on alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton NONCLUSTERED HASH (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (BUCKET_COUNT = 2000000);
I have started by measuring the impact of log writes in each of the scenarios with the following command:
select count(*), sum([log record length]) from fn_dblog(null, null)
The results for the Columnstore Indexes are presented below:
 One can clearly notice that the scaling goes up in a very much linear way – every 2 million rows we add to our source table will reflect in around 380 MB of information in the transaction log. If you are adding a Columnstore Index to your table where you already have a lot of data – be prepared for a lot of activities in your transaction log and you better have a fast drive ready.
One can clearly notice that the scaling goes up in a very much linear way – every 2 million rows we add to our source table will reflect in around 380 MB of information in the transaction log. If you are adding a Columnstore Index to your table where you already have a lot of data – be prepared for a lot of activities in your transaction log and you better have a fast drive ready.
But how do these results compare to adding a nonclustered hash index to an InMemorty table? Here is something to compare with:
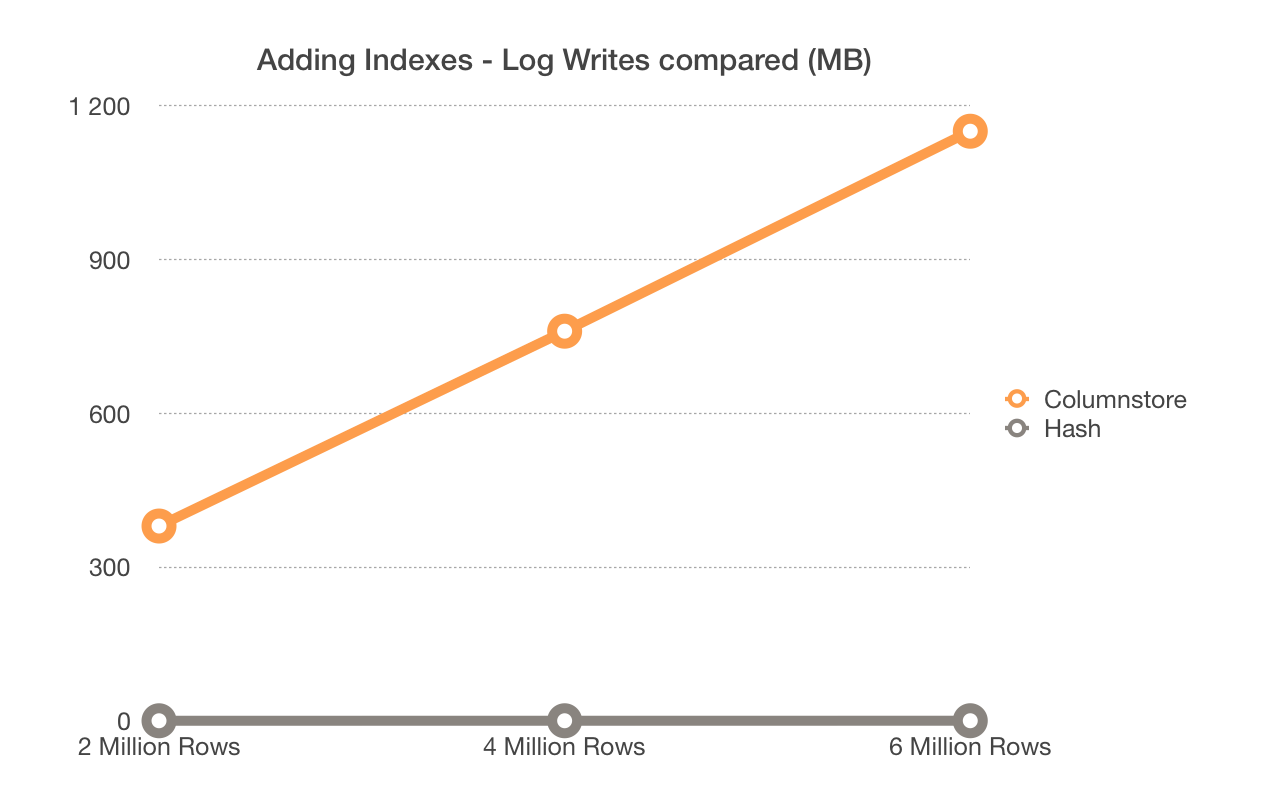
Yes, you can see the correct results – the writes for the adding a nonclustered hash index do not go beyond 300 KB. Basically this is a meta-data operation, a highly optimised write procedures, which are extremely effective, since they do not bring impact on a linear basis (230-280KB of writes for varying 2 Million to 6 Million rows).
Now let’s move on to the elapsed time for the operations:
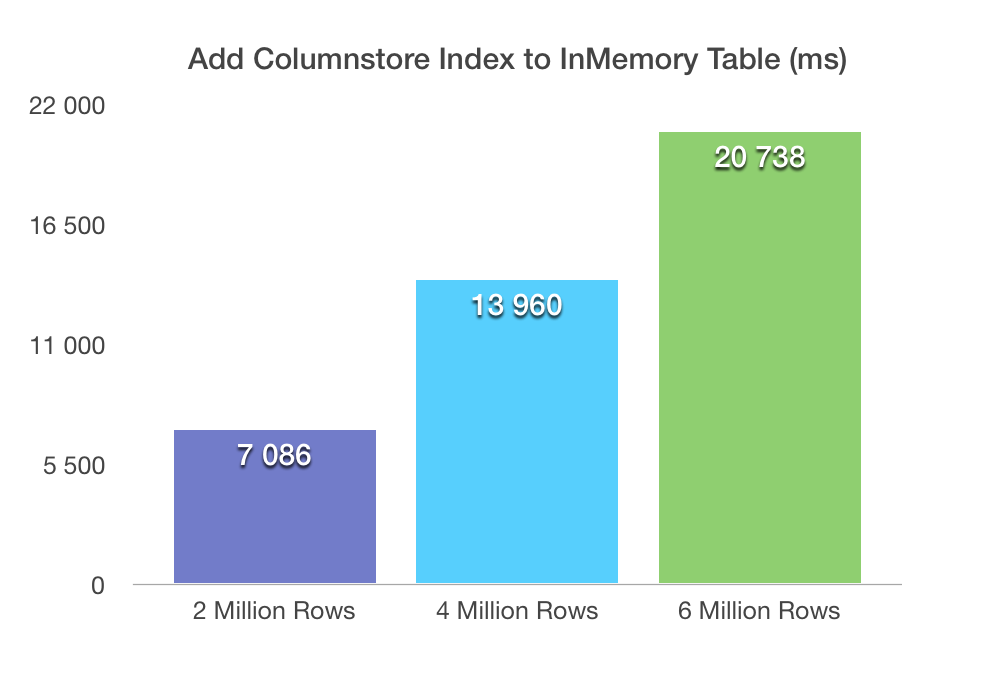
The times are pretty linear, and they do not look very bad – we pay with 7 seconds for every 2 million rows. Of course, might have to do with the amount of the CPU power I have had in my test VM. Let’s take a look on the elapsed times spent on the addition of the Nonclustered Hash Indexes:
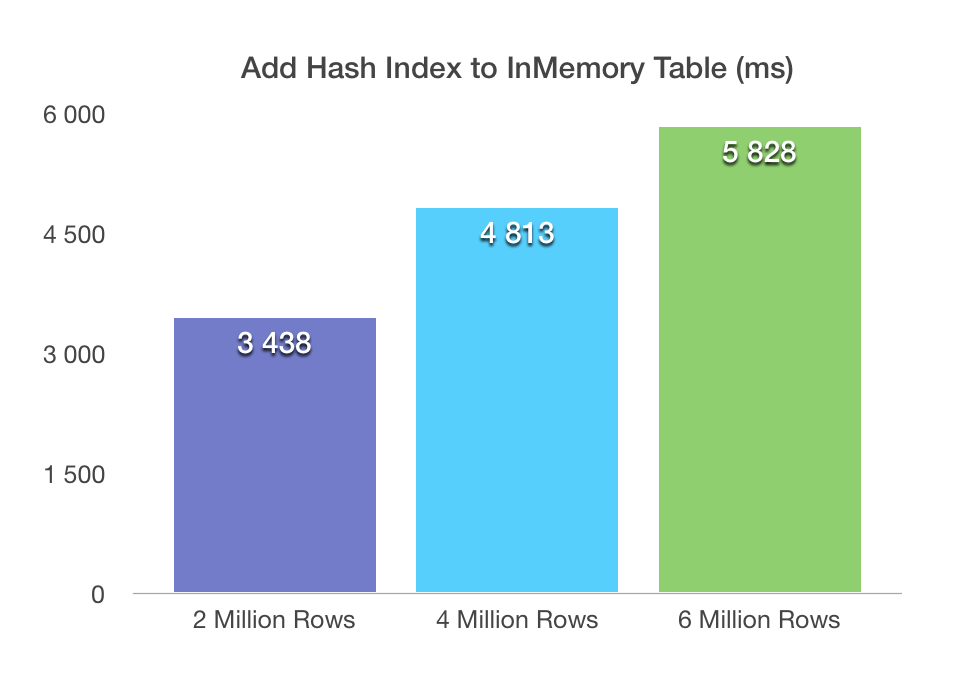
The situation here is obviously different, with the lowest time for 2 million rows table going as low as 3.4 seconds, while scaling very well with 5.8 seconds for the 6 million rows table. This scaling is definitely not the same as in the case of the Columnstore Index: even 6 million rows table modification with an addition of the Nonclustered Hash index takes less time then an addition of a Columnstore Index for a 2 million rows table.
Let’s take a look in a perspective joining the information into a single graph:

This graphic has the same directions as the one on the transaction log writes, though of course not so much different, where the optimised log writes are definitely the biggest advantage of the nonclustered hash indexes.
What about the CPU time? Here is the graph with the detailed information:
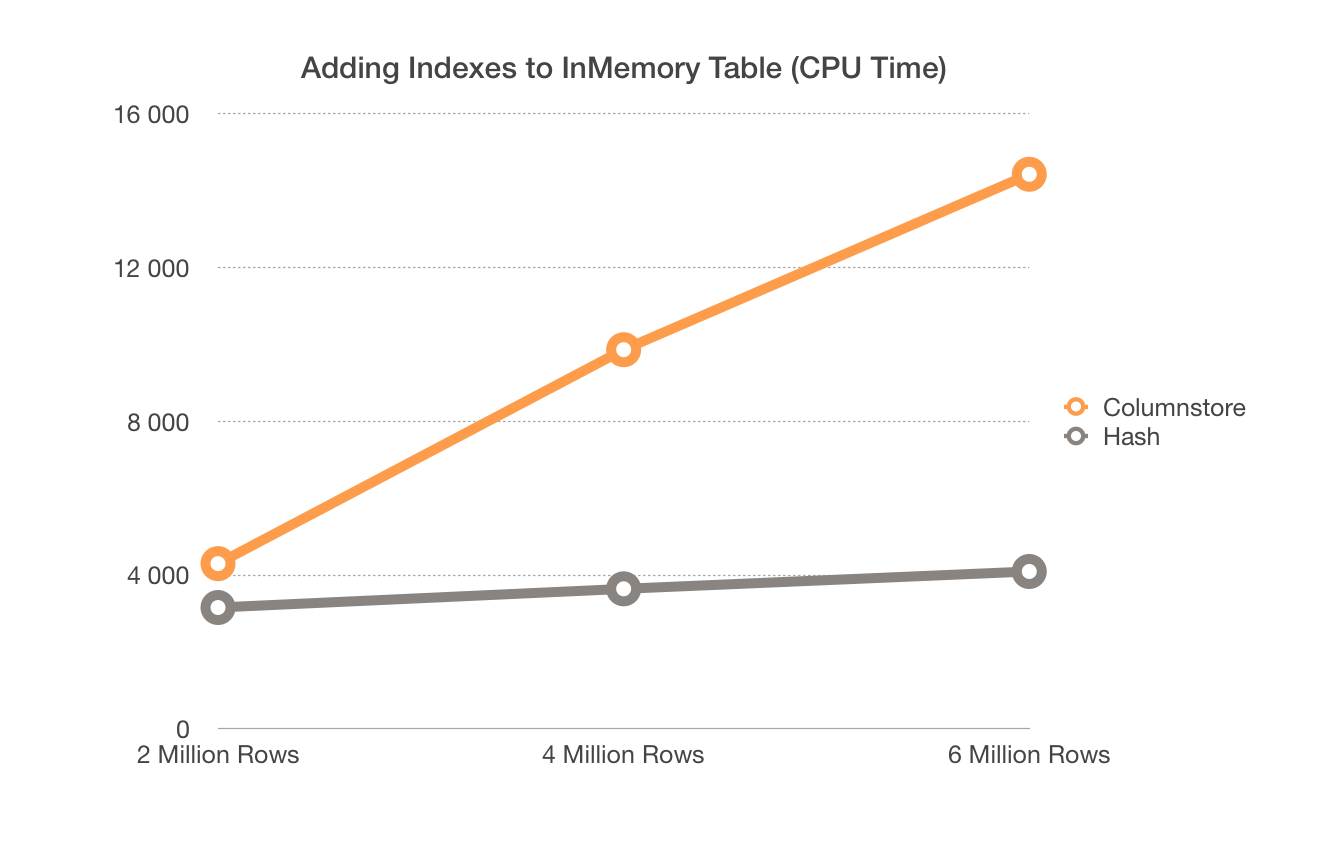
The graphic with the CPU times shows the same tendency of Nonclustered Hash Indexes and the transactional log writes.
I am really impressed with the optimised log writes of the Nonclustered Hash Indexes addition, and I hope that Microsoft will implement something similar for the Columnstore Indexes as well.
The down time (the table goes offline during the ALTER TABLE command) is something that on the large scale installation will be suffering, but the overall progress is good, it is really great!
to be continued with Columnstore Indexes – part 82 (“Extended Events in SQL Server 2016”)
I wonder why the time taken in “hash index added to Hekaton table” is not proportional to the number of rows. At zero rows this should still cost ~2sec when extrapolating the chart.
Hi tobi,
indeed, that’s because hash index addition to Hekaton table in the case where I have been showing it is largely meta-information based operation running in parallel, while Columnstore index addition to Hekaton table is a single-threaded fully logged operation.
I will try to find time to expand this blog post with more details in the future.
Best regards,
Niko
But why does the operation take 2sec on a zero row table if we extrapolate the chart? There seems to be a 2 second fixed cost.
Referring to http://www.nikoport.com/wp-content/uploads/2016/03/Elpased-Time-Adding-Hash-Index.png
Hi tobi,
I have not forgotten you – just have not had a chance to try it out. I will experiment and reply here on the weekend.
Best regards,
Niko
Hi tobi,
finally managed to run some tests – on my VM adding to the just 200 rows to the Memory Optimized table means that adding a Columnstore Index takes at least 2.2 seconds, while adding a Hash Index takes just 1.4 seconds.
My understanding is that it definitely has to do with the amount of data stored in the log, plus the fact that Columnstore Indexes are added in a single-thread, while Hash-Indexes are added in multi-threaded environment.
There is a great reference to that capabilities in the In-Memory OLTP features added between CTP3 and RC0 blog post by Jos de Bruijn: https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/03/25/whats-new-for-in-memory-oltp-in-sql-server-2016-since-ctp3/
Specifically in the ALTER TABLE Optimizations section.
Hi Niko,
I am seeing something strange when I run the following query, joining sys.dm_db_xtp_hash_index_stats with sys.indexes.
The index_id values for the clustered columnstore index, NCCI_FactOnlineSales_Hekaton, do not match between the 2 catalog views.
index_id = 3 (sys.dm_db_xtp_hash_index_stats)
index_id = 1 (sys.indexes)
Run the following:
USE [ContosoRetailDW];
GO
SELECT
OBJECT_NAME([is].[object_id]) AS [Table]
, [i].[name] AS [Index]
, [i].[index_id]
, [is].[index_id]
FROM
sys.dm_db_xtp_hash_index_stats AS [is]
LEFT OUTER JOIN
sys.indexes AS [i]
ON
[is].[object_id] = [i].[object_id]
AND [is].[index_id] = [i].[index_id];
GO
SELECT
OBJECT_NAME([i].[object_id]) AS [Table]
, [i].[name] AS [Index]
, [i].[index_id]
FROM
sys.indexes AS [i]
WHERE
OBJECT_NAME([i].[object_id]) = ‘FactOnlineSales_Hekaton’;
GO
Any idea why that is?
Thank you,
Marios Philippopoulos
Hi Marios,
Hash Index Stats DMV (sys.dm_db_xtp_hash_index_stats) should not contain any information on the Columnstore Indexes, since Columnstore Index is not a Hash Index.
The more correct DMV in this case would be sys.dm_db_xtp_index_stats. Let me know if this helps.
Best regards,
Niko Neugebauer
Thanks Niko.
Another strange thing I have found with sys.dm_db_xtp_hash_index_stats:
it returns bucket counts of both hash and range indexes (which doesn’t make sense for range).
Running the following query on a database with tables having both hash and range indexes returns info for both types:
SELECT
OBJECT_NAME([is].[object_id]) AS [Table]
, [i].[name] AS [Index]
, [i].[index_id]
, [is].*
FROM
sys.dm_db_xtp_hash_index_stats AS [is]
LEFT OUTER JOIN
sys.indexes AS [i]
ON
[is].[object_id] = [i].[object_id]
AND [is].[index_id] = [i].[index_id];
GO
I don’t know how to interpret these results. And, BTW, I don’t know what object the xtp_object_id is supposed to represent.
Any ideas? :-)
Hi Marios,
sorry, the last 1.5 Months have been quite overwhelming and I simply forgot to answer.
I see this as a bug, and I filed it here:
https://connect.microsoft.com/SQLServer/feedback/details/2979362/inmemory-columnstore-on-nonclustered-index-produces-entries-in-the-sys-dm-db-xtp-hash-index-stats-dmv
Best regards,
Niko Neugebauer
I too am finding results from dm_db_xtp_hash_index_stats that I don’t expect.
object name index name total_bucket_count empty_bucket_count empty_bucket_percent avg_chain_length max_chain_length
SalesOrderDetail_inmem imPK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID 8388608 4635545 55 1 8
SalesOrderDetail_inmemcs imPK_SalesOrderDetailcs_SalesOrderID_SalesOrderDetailID 4194304 4194248 99 1 1
SalesOrderDetail_inmemcs imPK_SalesOrderDetailcs_SalesOrderID_SalesOrderDetailID 4194304 4194232 99 1 1
SalesOrderDetail_inmemcs imPK_SalesOrderDetailcs_SalesOrderID_SalesOrderDetailID 131072 131063 99 1 1
SalesOrderDetail_inmemcs imPK_SalesOrderDetailcs_SalesOrderID_SalesOrderDetailID 8388608 4635545 55 1 8
SalesOrderDetail_inmemcs IX_SalesOrderDetail_inmemcs_ModifiedDate 4194304 4194247 99 1 16
SalesOrderHeader_inmem PK_SalesOrderHeader_SalesOrderID_inmem 2097152 1123871 53 1 7
The SalesOrderDetail_inmem and SalesOrderHeader_inmem tables have PKs of a hash index. The other 5 results are for the same table as SalesOrderDetail_inmem except for the addition of a clustered columnstore index. Why am I getting multiple rwos for the columnstore PrimaryKey and why did I get a one line result for a nonclustered index (on ModifiedDate). Would appreciate any feedback. I’ve done a fair amount of research with very little conclusive results
Hi Mike,
I filed a connect item:
https://connect.microsoft.com/SQLServer/feedback/details/2979362/inmemory-columnstore-on-nonclustered-index-produces-entries-in-the-sys-dm-db-xtp-hash-index-stats-dmv
Let’s see what kind of answer we shall get.
Best regards,
Niko Neugebauer
Thanks Niko for filing this and Mike for adding to this issue.
Marios