Continuation from the previous 71 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
I have previously written on the Rowstore Operational Analytics, and now it is the time to dive into the InMemory Operational Analytics in SQL Server 2016 CTP 3.0, especially since it is looking much more stable and well-performing in this latest release.
In my opinion in the vast majority, the future belongs to this technology instead of the Rowstore Operational Analytics, because the whole market is moving into the InMemory direction.
InMemory Operational Analytics
InMemory Operational Analytics takes advantage of the In-Memory OLTP (aka Hekaton) combining it with the Columnstore Indexes, merging OLTP workloads with analytical queries allowing to analyse the data in the real time.
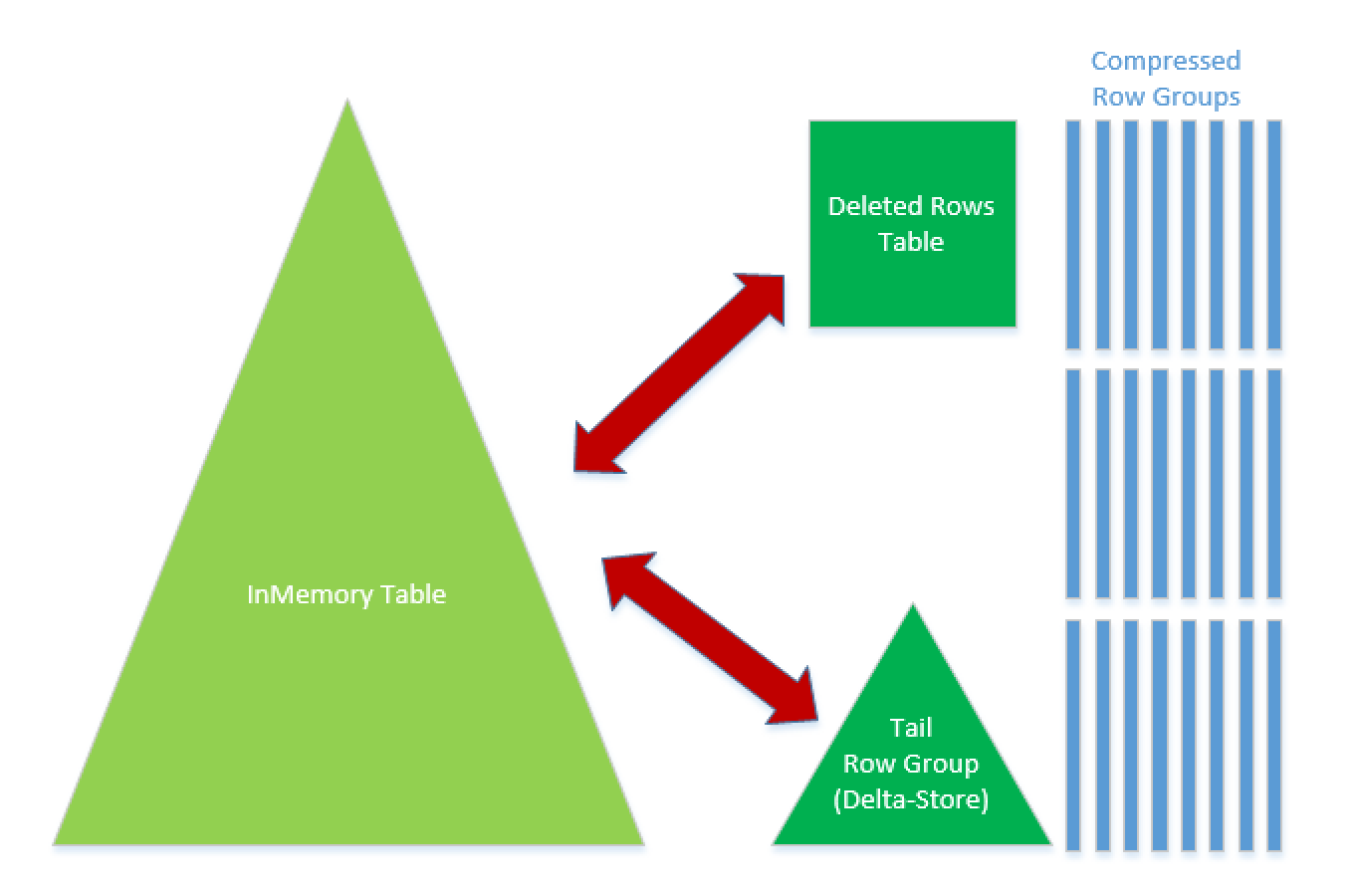 The architecture of the InMemory Operational Analytics can be seen on the right side of this text, where you can identify the usual elements of Columnstore Indexes – such as compressed Segments and Row Groups. You should also notice the different elements, such as Deleted Rows Table and Tail Row Group, while the usual suspect Deleted Bitmap is missing.
The architecture of the InMemory Operational Analytics can be seen on the right side of this text, where you can identify the usual elements of Columnstore Indexes – such as compressed Segments and Row Groups. You should also notice the different elements, such as Deleted Rows Table and Tail Row Group, while the usual suspect Deleted Bitmap is missing.
This happens because the new data comes into a Tail Row Group, which itself essentially is a Delta-Store but without any limitations on the size (meaning it can grow over the 1045678 rows).
The Deleted Rows Table will stores the information on all the rows that were deleted from the primary (Hekaton) table related to the Compressed Row Groups,
Notice that the Deleted Rows Table itself is a Hekaton table (meaning Hash-based In-Memory one).
Also an important architectural element here is that every Row Group is stored on a separate data file, guaranteeing in that way an easy and effective garbage collection, should the whole Row Group be removed.
Given that the Hot Data in the InMemory table is getting constantly updated, a very important principle here is to avoid moving this type of data into a compressed Row Group. For this purpose, the process that is compressing the rows from the Tail Row Group, will scan it for the rows that have been modified in the past 1 hour. Those rows will not be moved into the compressed Row Groups, in order to avoid putting a data that most probably will be modified (deleted) right away. This means that every row in the Tail Row Group will contain a Timestamp information on when it was modified for the last time.
It is important to notice that the Hekaton table itself will be also modified under the cover, so that every row will contain the row location inside the compressed Row Groups. This Row location (aka Row Id) identifies the id of the Row Group where this row is stored and then the position within it.
Should the row for the Columnstore Index be only in the Row Tail Group, then it this special Row Id will contain an invalid value, indicating that the row is still not compressed.
Data Migration Task
The Data Migration Task is the process that takes the data from the Tail Row Group and compresses it into the Compressed Row Groups.
The execution process of it takes place in the following order:
1. The Tail Row Group will be scanned for the Rows that were not modified in the past 1 hour.
2. If there is enough data to become a compressed Row Group (1048576 rows), then the data will be moved into the Columnstore storage space using Hekaton technology, where it will be compressed.
Should there be less then 1.048.576 rows, then no data will be moved into the Row Groups, in order not to create trimmed and less effective Row Groups.
3. The RowIds of the rows that were migrated into the Row Groups, will be copied over into the Deleted Table in order to hide the newest Row Group from the current queries scanning Columnstore Index.
In order to make optimisations of performance the RowIds will be stored as the ranges inside the Deleted Rows Table. Basically we shall store the Minimum and the Maximum RowID value of the range.
4. The Row Group created in the step 2 will be added to the Columnstore Index.
5. The Rows in the Deleted Rows Table that were moved into the compressed Row Groups (step 3) will be removed.
6. The original rows from the Tail Row Group will be removed
7. The Hekaton table will be updated with the location (RowIds) of the rows that were moved from the Tail Row Group. This way the data will become visible for the current transactions.
After that the migration process will be declared as complete.
Row Group Cleanup
Once the Row Group receives a big number of Rows that are marked as deleted (over 90%) in the Deleted Rows Table, the Row Group Cleanup task will kick in.
This process is basically a reverse action of taking the data out of the compressed segment, and moving it into the Tail Row Group. This will mean that the rows from the Deleted Rows Table will simply be removed from the system and all active rows will be merged with the existing rows in the Tail Row Group.
I wish there would be a process, similar to Clustered Columnstore Indexes Merge policy, so we would not have to move our rows into the Tail Row Group, but we would simply merge some of the existing Row Groups.
to be continued with Columnstore Indexes – part 73 (“Big Delta-Stores with Nonclustered Columnstore”)
Is it possible to have hybrid columnstore partitions with say older partitions in disk-based columnstore and the latest ones in memory?
Greetings Graham,
no, this is impossible and looking at the internal architecture – it would make a solution a huge mess.
Best regards,
Niko