Continuation from the previous 69 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post is the continuation from the previous one, where I have described the Operational Analytics for Rowstore.
I have tried to create a filtered index, but the performance results that I was getting overall were very far from what I have expected from them.
After great comments from Vassals Papadimos (MS), I have decided to dedicate this blogpost to the investigation of making the Filtered Indexes work.
For that purpose I shall use the free AdvenuterWorks database that was expanded with a script from Adam Machanic – Make Big Adventure to have a 250 Million rows Columnstore table.
As the previous blog post, I will be running all the tests on the Azure SQLDatabase P6 instance.
Like the best practices recommend, we need to make sure that we have a Clustered B-Tree Index on our table:
ALTER TABLE [dbo].[bigTransactionHistory] ADD CONSTRAINT [pk_bigTransactionHistory] PRIMARY KEY CLUSTERED ([TransactionID]) with (DATA_COMPRESSION = PAGE);
Let’s create a filtered nonclustered Columnstore Index on our test table dbo.bigTransactionHistory:
create nonclustered columnstore index [NCCI_bigTransactionHistory]
on [dbo].[bigTransactionHistory] (
[TransactionDate]
,[ProductID]
,[Quantity]
,[ActualCost] )
where TransactionDate < '2011-01-01';
Now its the time to execute our test query, that includes a search predicate that is different to the predicate that I have used for the filtered Columnstore index. In the query I am using 1st of January of 2012 as the start date for the search, while my Index is set to filter the Transactions with the date before 1st of January of 2011.
set statistics io, time on
SELECT Year([TransactionDate]) as Year
,Sum([Quantity]) as TotalQuantity
,Sum([ActualCost]) as TotalCost
FROM [dbo].[bigTransactionHistory] tr --with(index([ncci_bigTransactionHistory]))
inner join dbo.bigProduct prod
on tr.ProductID = prod.ProductID
where TransactionDate <= '2012-01-01'
group by Year(TransactionDate)
having Sum([Quantity]) > 10000
order by Year(TransactionDate)
option (recompile);
This query takes some time to execute (well, processing 250 million rows is not a very small table) - with almost 39 seconds of the total execution time, we are also counting with spending over 145 seconds of the so precious CPU time.
Its good that we have 6 cores on the P6 Azure SQLDatabase instance, on smaller instances this query should take much more time, proportionally . This happens because we are not using the Batch Execution Mode - there are no Columnstore Indexes in the execution time:

All you can see is the B-Tree scan, which is definitely what is killing the query performance.
We urgently need to find solutions for this problem. As Vassilis Papadimos pointed out in the comments to my previous blog post, there are a couple of ways to address this problem. Let's consider all of them.
Forcing the Columnstore Index Usage
First of all, we can force the usage of the the Columnstore Index by simply specifying it with an INDEX hint:
SELECT Year([TransactionDate]) as Year
,Sum([Quantity]) as TotalQuantity
,Sum([ActualCost]) as TotalCost
FROM [dbo].[bigTransactionHistory] tr with(index([ncci_bigTransactionHistory]))
inner join dbo.bigProduct prod
on tr.ProductID = prod.ProductID
where TransactionDate <= '2012-01-01'
group by Year(TransactionDate)
having Sum([Quantity]) > 10000
order by Year(TransactionDate)
option (recompile);
In the terms of the raw performance, my query took over 75 seconds of CPU time and overall duration was a little bit over 21 seconds.
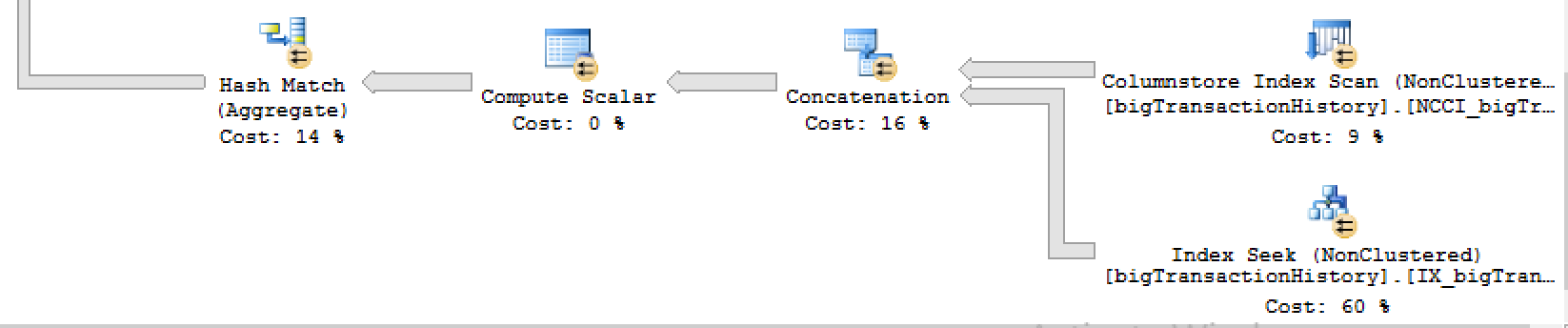
The relevant part of the execution plan is shown below:

You can clearly see that the data from the filtered Nonclustered Columnstore Index is being concatenated with the data from the B-Tree Clustered Index Scan, which is making this operation extremely expensive.
The practical improvement is huge - we are talking around 50% of the overall spent time and cpu resources.
Create a RowStore B-Tree Filtered Index covering opposite side
This idea is all about covering the part of the table structure that is not being covered
that will take over the HOT (actively updated) data.
Let's go ahead and create this nonclustered b-tree index:
create nonclustered index IX_bigTransactionHistory_TranasctionDate_Filtered
on dbo.bigTransactionHistory (
[TransactionDate]
,[ProductID]
,[Quantity]
,[ActualCost] )
where TransactionDate >= '2011-01-01'
with (data_compression = page);
Let's re-execute our test query:
SELECT Year([TransactionDate]) as Year ,Sum([Quantity]) as TotalQuantity ,Sum([ActualCost]) as TotalCost FROM [dbo].[bigTransactionHistory] tr with(index([ncci_bigTransactionHistory])) inner join dbo.bigProduct prod on tr.ProductID = prod.ProductID where TransactionDate <= '2012-01-01' group by Year(TransactionDate) having Sum([Quantity]) > 10000 order by Year(TransactionDate) option (recompile);This time the query was executed even faster with just 37 seconds of CPU time and just a bit over 10 seconds of overall execution time.
CPU time = 37595 ms, elapsed time = 10305 ms.
Partitioning
Another way that was suggested is to use partitioning on the Clustered B-Tree Index, that would help the overall performance.
Since Azure SQLDatabase does not support traditional SQL Server partitioning, I will test this methodology on the SQL Server 2016 CTP 2.4.In my [dbo].[bigTransactionHistory] table on this VM, I have just a bit over 31 Million rows, but its not the exact performance that I am looking forward to measure, but the execution plan behaviour is what really matters to me in this case.
Let's set up our database with the new file groups for each of the years containing the data, and even some extra file groups for the future data:
alter database AdventureWorks2014 add filegroup oldAdWorks; GO alter database AdventureWorks2014 add filegroup AdWorks2005; GO alter database AdventureWorks2014 add filegroup AdWorks2006; GO alter database AdventureWorks2014 add filegroup AdWorks2007; GO alter database AdventureWorks2014 add filegroup AdWorks2008; GO alter database AdventureWorks2014 add filegroup AdWorks2009; GO alter database AdventureWorks2014 add filegroup AdWorks2010; GO alter database AdventureWorks2014 add filegroup ModernAdWorks; GOIt's time to add a data file to each of the new File Groups:
alter database AdventureWorks2014 add file ( NAME = 'old_data', FILENAME = 'C:\Data\old_data.ndf', SIZE = 10MB, FILEGROWTH = 125MB ) to Filegroup oldAdWorks; GO alter database AdventureWorks2014 add file ( NAME = '2005_data', FILENAME = 'C:\Data\2005_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup AdWorks2005; GO alter database AdventureWorks2014 add file ( NAME = '2006_data', FILENAME = 'C:\Data\2006_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup AdWorks2006; GO alter database AdventureWorks2014 add file ( NAME = '2007_data', FILENAME = 'C:\Data\2007_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup AdWorks2007; GO alter database AdventureWorks2014 add file ( NAME = '2008_data', FILENAME = 'C:\Data\2008_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup AdWorks2008; GO alter database AdventureWorks2014 add file ( NAME = '2009_data', FILENAME = 'C:\Data\2009_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup AdWorks2009; GO alter database AdventureWorks2014 add file ( NAME = '2010_data', FILENAME = 'C:\Data\2010_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup AdWorks2010; GO alter database AdventureWorks2014 add file ( NAME = 'Modern_data', FILENAME = 'C:\Data\Modern_data.ndf', SIZE = 500MB, FILEGROWTH = 125MB ) TO Filegroup ModernAdWorks; GOLet's create the partitioning scheme & function:
create partition function pfTransactionDate (datetime) AS RANGE RIGHT FOR VALUES ('2005-01-01', '2006-01-01', '2007-01-01', '2008-01-01', '2009-01-01','2010-01-01', '2011-01-01'); create partition scheme ColumstorePartitioning AS PARTITION pfTransactionDate TO ( oldAdWorks, AdWorks2005, AdWorks2006, AdWorks2007, AdWorks2008, AdWorks2009, AdWorks2010, ModernAdWorks );Now, let's drop the primary key and create the Clustered Rowstore Index for ensuring that the data is partitioned:
alter table dbo.bigTransactionHistory drop CONSTRAINT [pk_bigTransactionHistory] create clustered index [pk_bigTransactionHistory] on dbo.bigTransactionHistory (TransactionDate) on [ColumstorePartitioning] (TransactionDate);We are still missing our Filtered Nonclustered Columnstore Index, notice that since this is a on-premises test (SQL Server 2016 CTP 2.4):
create nonclustered columnstore index [NCCI_bigTransactionHistory] on [dbo].[bigTransactionHistory] ( [TransactionDate] ,[ProductID] ,[Quantity] ,[ActualCost] ) where TransactionDate < '2009-01-01';Now, let's run a test query - notice I have modified the predicate to include 1 extra month from the 2009, making sure that we are reading data outside of the scope of our Nonclustered Columnstore Index:
set statistics io, time on SELECT Year([TransactionDate]) as Year ,Sum([Quantity]) as TotalQuantity ,Sum([ActualCost]) as TotalCost FROM [dbo].[bigTransactionHistory] tr --with(index([ncci_bigTransactionHistory])) inner join dbo.bigProduct prod on tr.ProductID = prod.ProductID where TransactionDate <= '2009-02-01' group by Year(TransactionDate) having Sum([Quantity]) > 10000 order by Year(TransactionDate) option (recompile);The execution time for the query was 3.3 seconds, while the CPU time spent was about 4.5 seconds. Note: do not compare this execution times with the times on Azure SQLDatabase, since the original tables are absolutely different - 250 Million Rows on my Azure SQLDatabase example, while only 32 Millions at the local VM on my computer.
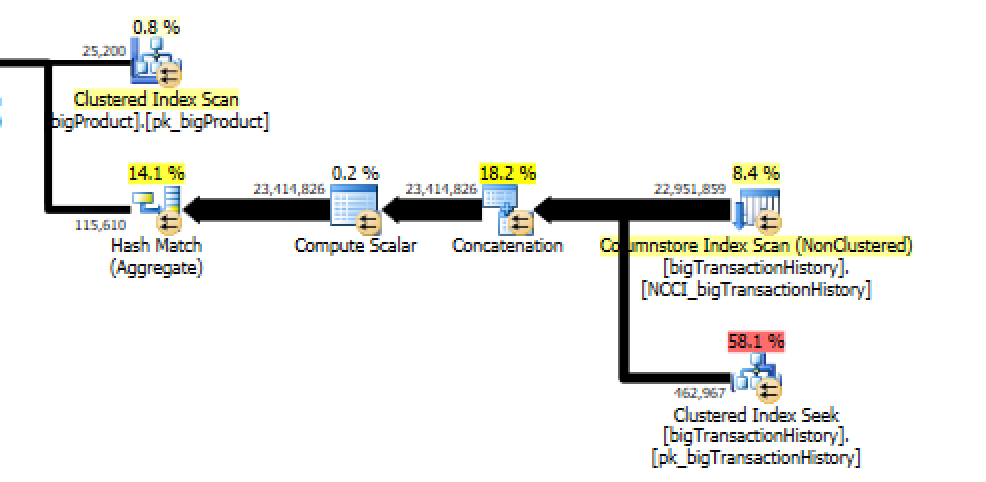
Let's take a look at the execution plan:
Once again we have a concatenation between the Nonclustered Columnstore Index and our partitioned Clustered Rowstore B-Tree Index.
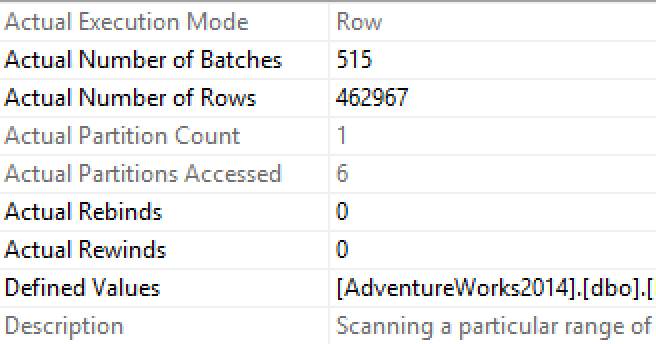
Let's check how many partitions were actually accessed while we were reading the data from the Clustered Index - as you can see on the picture showing the properties we are accessing only 1 partition, which will allow to us to gain some of the performance, if we partition our data well and place different data files on the different drives or LUNs.
Of course we can and should consider adding the Filtered Nonclustered Index that is covering the HOT data area that is not being covered by the Filtered Columnstore Index.Final Thoughts
Very nice improvements for the Filtered Columnstore Index - I really love them. Let's hope that there will be enough documentation explaining the usage with the examples, otherwise people like me might think that the functionality is not really complete.
Note that you will need to be extremely careful of where you are setting your filter for Columnstore Index, for example in the last solution should we run the following query with a predicate that is further away from the Nonclustered Columnstore predicate, then the performance will suffer greatly - changing from 3.3 seconds to over 13 seconds.
set statistics io, time on SELECT Year([TransactionDate]) as Year ,Sum([Quantity]) as TotalQuantity ,Sum([ActualCost]) as TotalCost FROM [dbo].[bigTransactionHistory] tr inner join dbo.bigProduct prod on tr.ProductID = prod.ProductID where TransactionDate <= '2010-02-01' group by Year(TransactionDate) having Sum([Quantity]) > 10000 order by Year(TransactionDate) option (recompile);SQL Server Execution Times: CPU time = 10328 ms, elapsed time = 13084 ms.Take a look at the execution plan:
That is definitely something that you will want to avoid seeing in the production environments.I still wish to see the moving predicate, a kind of that would be set on some certain date, for example, but now, understanding better how things work - it would be übercool that it would be set dynamically on Columnstore and Rowstore Indexes in parallel ...
Well, just dreaming ... :)to be continued with Columnstore Indexes – part 71 (“Change Data Capture, Change Tracking & Temporal”)