Continuation from the previous 65 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Continuing writing about the improvements added to Clustered Columnstore Indexes (DataWarehousing & Business Intelligence) in SQL Server 2016, this blog post is a direct continuation from my previous post on the Nonclustered B-Tree Indexes added to Clustered Columnstore Index in SQL Server 2016.
This blog is focused on the improvements for the Clustered Columnstore Indexes and especially the support of the unique constraints and referential integrity between the tables in SQL Server 2016.
In SQL Server 2014 and before we were always told to verify the referral integrity between the tables by setting up a correct ETL process. This is a very correct recommendation, and indeed the verification of data integrity should be executing during the loading process – there is nothing new to add or to object at.
But … :)
The existence of the referential constraints and integrity constraints is something that any data solution will greatly appreciate. Take a look at NoSQL or Hadoop people – they started negating the need of constraints, but once going for the performance optimisations, one of the first thing to implement are the referential constraints.
As for me, I love Unique Constraints, Primary & Foreign Keys – they allow to describe the state of the database on the meta level, by describing the relationship between sets of data. They allow us to enforce those relations with just few lines of code. They help Query Optimiser to take more precise decisions on how to process our queries as fast as possible, and for DataWarehouse/BI Solutions the speed with with the information is being returned is one of the keys to success.
In SQL Server 2016, Microsoft has added a couple of very important improvements, regarding the unique Constraints, Primary Keys & Foreign Keys, and so let’s dive into them without any further delay.
For the start, let’s consider some clean & shiny new tables, that will contain a unique constrain, clustered columnstore index and a second table will contain a foreign key on the primary one:
create table dbo.T1( c1 int identity(1,1), c2 varchar(20), constraint UQ_T1_C1 unique nonclustered (c1), index CCI_T1 clustered columnstore ); create table dbo.T2( id int, c1_t1 int not null, constraint FK_T2_T1_c1 foreign key (c1_t1) references dbo.T1(c1) );
Notice that right from the beginning, I am including a unique constraint for the table T1. This is impossible in SQL Server 2014 and earlier versions. Observe that I have defined my unique constraint UQ_T1_C1 as a nonclustered – this is because I need to define a Nonclustered Index on it.
My table T2 has a foreign key FK_T2_T1_c1 that references the
T1 table! This is really amazing, but let’s test if the data insertion, to verify if everything works correctly whenever users are inserting and reading the data:
insert into dbo.T1 (c2)
values ('Alex'), ('Brown'), ('Cat');
insert into dbo.T2 (id, c1_t1)
values (1, 1 );
Worked like magic, but what about reading data from the tables:
select * from dbo.T1 inner join dbo.T2 on T1.c1 = T2.c1_t1;
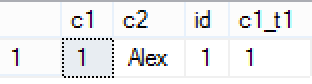 Works very well, with no problems that I have seen so far. You can reference the table itself (from one column to another unique column by using a foreign key), you can naturally make cross references between any desired number of tables – you will face the consequences, but yes you can! ;)
Works very well, with no problems that I have seen so far. You can reference the table itself (from one column to another unique column by using a foreign key), you can naturally make cross references between any desired number of tables – you will face the consequences, but yes you can! ;)
Let’s try some disruptive changes – let’s add a clustered columnstore index to the T2 table, so that we can test that a table containing columnstore together with a foreign key:
alter table dbo.T2 add index CCI_T2 clustered columnstore;
Ha! Interesting …
Msg 10785, Level 16, State 1, Line 27 The operation 'ALTER TABLE ADD INDEX' is supported only with memory optimized tables. Msg 1750, Level 16, State 0, Line 27 Could not create constraint or index. See previous errors.
It looks like using this specific syntax to add a clustered columnstore index does not work in SQL Server 2016 CTP 2.3 yet. Let’s try to add a clustered columnstore index with a good old syntax:
create clustered columnstore index CCI_T2 on dbo.T2;
This time it functioned without any problem.
To continue with a more complete example, I am restarting with a fresh copy of the free ContosoRetailDW database, that I am using for most of my tests.
Let’s start the engines with the a fresh restore, upgrading the database compatibility level to 130, and making a bit more space for the Data File & the Log File:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Now, its time to play with my favourite test table: FactOnlineSales.
Notice, that not like before, I am not dropping any of the 6 foreign keys, that are defined on it, but I will simply try to replace the existing Clustered Index on it, by creating a Clustered Columnstore Index with a hint (DROP_EXISTING = ON):
create clustered columnstore Index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales with( drop_existing = on);
This did not work the way I have expected, I have to say:
Msg 1907, Level 16, State 1, Line 35
Cannot recreate index ‘PK_FactOnlineSales_SalesKey’. The new index definition does not match the constraint being enforced by the existing index.
This message and the lacking functionality seems to be an overkill, and while in my thoughts I can imagine that actual development of this feature can be complex and compelling, there is no doubt, that the actual SQL Server users are expecting this to work directly.
Since there is a Primary Key with a clustered Index built as one on this table, I will have to drop the Primary Key thus dropping the clustered Index as well:
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
Now, FactOnlineSales is a HEAP, and this way I can add a Primary Key that is NONCLUSTERED, before creating Clustered Columnstore Index:
alter table dbo.FactOnlineSales add constraint PK_FactOlnineSales primary key Nonclustered (OnlineSalesKey);
create clustered columnstore Index [CCI_FactOnlineSales] on dbo.FactOnlineSales;
This time, it works like magic!
Now we have a table with Clustered Columnstore Index, Primary Key & 6 Foreign Keys!
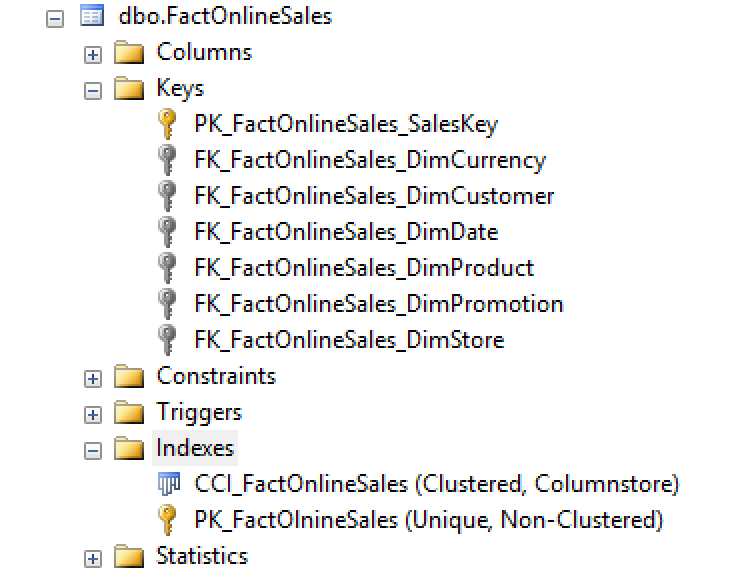 Looking at the picture on the left side you can see a view on a table that you would expect to find in a well configured environment, with a unique constraint, foreign keys and a clustered columnstore index. :)
Looking at the picture on the left side you can see a view on a table that you would expect to find in a well configured environment, with a unique constraint, foreign keys and a clustered columnstore index. :)
Having foreign keys enabled on our table, will allow Query Optimiser to take advantage of the better estimations for memory grants and more precise execution plans, which are some of the most important aspects of the performance, and their absence for Columnstore Indexes for the versions 2012 & 2014 of SQL Server was a very sad miss. Now with SQL Server 2014 and Azure SQLDatabase we can finally take advantage of them.
to be continued with Columnstore Indexes – part 67 (“Clustered Columstore Isolation Levels & Transactional Locking”)
Dear Niko Neugebauer, Did you face any experience while dropping the clustered column store index? Our environment holds 40 million rows in a partitioned table. When dropping clustered column store it took 1 hour, but for non clustered column store it took 25 minutes.
Creation of clustered column store also taking larger time, because of sorting. when dropping the index will it re-align the records in the table causing the delay?
Greetings Kannan,
I will assume that you do understand the difference between Clustered and Nonclustered Indexes (full table) vs (part of the table),
Creation of the Clustered Columnstore Index should take more time, especially if you have secondary indexes, because the connection between them should be updated as well, while when you are creating a Nonclustered Columnstore Index, you just need to hook it up with the Clustered Rowstore Index or with the HEAP.
Some of the same processes will take place once you are dropping the Clustered Index – since the table becomes a HEAP you will need to update all secondary Nonclustered Index, while for the Nonclustered Index, there are no comparable impacts to the other indexes to be executed.
Best regards,
Niko Neugebauer
Dear Niko Neugebauer, Yes you are absolutely right and thanks for providing the hint. I reduced the index creation/dropping duration of clustered column-store index by dropping the existing non clustered row store index before creating/dropping the clustered column-store index. Now the duration drastically reduced and similar to the non clustered column store index creation/dropping duration.
I also noticed there are some meta data changes happened during the creation and dropping of column store index. I got this information after exploring the URL https://www.sqlskills.com/blogs/joe/exploring-column-store index-metadata-segment-distribution-and-elimination-behaviors/.
Even i remembered in your articles you mentioned about segment elimination about both indexes. With this URL we can know about rows count alignment in each segment.
Thanks for all your information. Keep up the good work..
Regards,
Kannan.C
Thank you for the kind words, sir!
Best regards,
Niko