Continuation from the previous 60 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
A lot of financial calculations in the SQL world involves a number of analytical & statistical functions, such as CUME_DIST, LEAD, FIRST_VALUE, PERCENTILE_CONT, LAG, PERCENTILE_DISC, LAST_VALUE, PERCENT_RANK (Their description and functionality can be found at the MSDN page for Analytic Functions) & VAR, VARP, STDEV, STDEVP and others (check out the Aggregate Functions page at the MSDN) plus window aggregate functions: COUNT, COUNT_BIG, SUM, AVG, MIN, MAX & CLR implementations.
Their support and implementation in SQL Server has been a part of the mission that some well-known specialists, such as Itzik Ben-Gan, have been fighting for years.
Microsoft has greatly improved support for window functions in SQL Server 2012 by implementing a number of features, and now, the support for the Batch Execution Mode for Window functions has been introduced in SQL Server 2016.
To all my surprise officially the most commonly used ranking functions (RANK,NTILE,DENSE_RANK,ROW_NUMBER) are not listed at the moment between those functions that support Batch Execution Mode, though my tests clearly have shown that it already exists.
 Ladies and gentlemen, let me introduce you to the newest member of the execution plan iterators – Window Aggregate. In all my tests during last weeks, I have only managed to see it performing in Batch Execution Mode, but I do not exclude the possibility that it might have an implementation in old traditional Row Execution Mode as a backup plan. It would make few sense to me now that there is a Batch Execution Mode support for a single core execution plan, but you know, just in case ;)
Ladies and gentlemen, let me introduce you to the newest member of the execution plan iterators – Window Aggregate. In all my tests during last weeks, I have only managed to see it performing in Batch Execution Mode, but I do not exclude the possibility that it might have an implementation in old traditional Row Execution Mode as a backup plan. It would make few sense to me now that there is a Batch Execution Mode support for a single core execution plan, but you know, just in case ;)
Important Note:
My tests have been executed on SQL Server 2016 CTP 2.1, where the first bits of the support have been implemented. The commitment to support much bigger range of different functions is made by Microsoft for the final release of SQL Server 2016, and so I am definitely expecting the supported operation list to grow over the next month before the final release.
For testing this new iterator I decide to use the very same VM with SQL Serve 2016 CTP 2.1 simply changing the compatibility level of my tested database to 120 whenever emulating results of SQL Server 2014. The importance of the compatibility level in SQL Server 2016 is described in a lot of precious details on the MSDN documentation page, and notice that the new features related to the batch mode are only available for the 130 compatibility level.
Once again, the usual suspect – the free database ContosoRetailDW have been restored and a Clustered Columnstore Index was created on the FactOnlineSales table:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Let’s kick off tests with a simple window aggregate, based on the MAX function:
declare @res as Decimal(9,3); select @res = Max(SalesAmount) over ( order by DateKey ) from dbo.FactOnlineSales where DateKey < '2009-01-01';
For testing in SQL Server 2014 compatibility level, you will need to add the following statement, but do not forget to reset it back to 130 once you want to get back to the SQL Server 2016 CTP 2.1 compatibility level.
alter database ContosoRetailDW set compatibility_level = 120; GO
 On the top of this text, you will see a very simple and clear execution plan which runs in the Batch Execution Mode for SQL Server 2016 CTP 2.1.
On the top of this text, you will see a very simple and clear execution plan which runs in the Batch Execution Mode for SQL Server 2016 CTP 2.1.
Now compare it to the execution plan below, which runs in SQL Server 2014 compatibility level.
 There is one important detail over the execution plan differences - the SORT iterator runs in the Batch Execution Mode for SQL Server 2016 while for SQL Server 2014 it is only capable of running in a Row Execution Mode, and hence we can only estimate the true difference between having Window Aggregate iterator and not having it in our execution plan.
There is one important detail over the execution plan differences - the SORT iterator runs in the Batch Execution Mode for SQL Server 2016 while for SQL Server 2014 it is only capable of running in a Row Execution Mode, and hence we can only estimate the true difference between having Window Aggregate iterator and not having it in our execution plan.
Anyway, comparing 2 plans I can see that Window Aggregate iterator is serving as a substitution for the following combination: Segment + Segment + Windows Spool + Aggregate.
I really hope that someone way smarter than I am, such as Paul White will dive deeply into this iterator in the following months, explaining its functionalities and limitaitons.
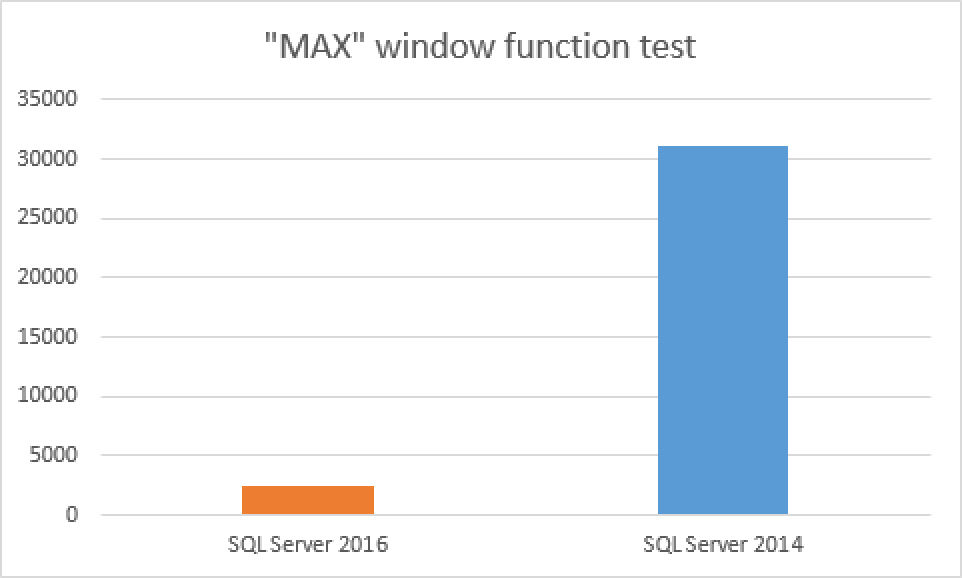 Regarding the execution time, there is not much to say except that SQL Server 2016 Window Aggregate function runs around 13 times faster than the SQL Server 2014 version, which is incredibly impressive for a functionality that demands a whole lot of CPU.
Regarding the execution time, there is not much to say except that SQL Server 2016 Window Aggregate function runs around 13 times faster than the SQL Server 2014 version, which is incredibly impressive for a functionality that demands a whole lot of CPU.
From another side, the memory grant for the SQL Server 2016 execution plan is 722 MB vs 974MB of the SQL Server 2014 execution plan, which again gives a significant (25%) improvement for the resource usage and with Columnstore Indexes we all know how hungry they are for all available resources.
Let's advance and run a query, doing 3 different calculations inside the same query, where all of the used window functions support the Batch Execution Mode within Window Aggregate iterator:
declare @res as Decimal(9,3); select @res = var( all SalesAmount ) over (order by year(DateKey) ), @res = STDEVP(SalesQuantity) over (order by year(DateKey) ), @res = MAX(SalesQuantity) over (order by year(DateKey) ) from dbo.FactOnlineSales where DateKey < '2009-01-01';
This time it took a significant amount of resources to process the requested information - 1 Minute and 28 seconds for the SQL Server 2016 CTP 2.1. For SQL Server 2014 compatibility level, I have managed to receive 116 seconds, which corresponds to almost 2 Minutes, a good difference to the original but somehow it does not get to the same scale of improvement as the single window function... Where is the problem ?
 The thing is that the first part of the query (the first window aggregate) is the same as for the single window function, but then for both of the queries we are falling back to the original SQL Server 2014 execution strategy: Segment + Segment + Window Spool + Stream Aggregate + Compute Scalar, which is exactly explains that the difference between the execution plans is based on the difference between the first window functions - around 30 seconds, since the 2nd and the 3rd window functions are running in exactly the same way.
The thing is that the first part of the query (the first window aggregate) is the same as for the single window function, but then for both of the queries we are falling back to the original SQL Server 2014 execution strategy: Segment + Segment + Window Spool + Stream Aggregate + Compute Scalar, which is exactly explains that the difference between the execution plans is based on the difference between the first window functions - around 30 seconds, since the 2nd and the 3rd window functions are running in exactly the same way.
I could add here that running 2 window aggregate functions works just fine and that in the execution plan I see 2 Window Aggregate operators and in the terms of the performance the execution time increases quite linearly, but I do not consider the limitation of using 2 window functions at maximum as a reasonable limitation and so this is definitely an area where I expect Microsoft to improve before the final release.
As I have mentioned in the begin of this article, there is whole category of functions - ranking functions (RANK,NTILE,DENSE_RANK,ROW_NUMBER) that are not listed as supporting Batch Execution Mode, but I decided to take them for a couple of tests if there are any improvements.
Between those ranking functions, ROW_NUMBER is by far the most popular one, being used for many different goals and can be found very frequently in OLTP systems as well.
Let's run a simple test query to find it's performance and compare with SQL Server 2014:
declare @resBigInt as BigInt; select @resBigInt = ROW_NUMBER() over ( order by DateKey ) from dbo.FactOnlineSales where DateKey < '2009-01-01';

This execution plan is very similar to the one, that can be found for the first query in this article, with the difference of Compute Scalar iterator being absent. The Window Aggregate iterator is well present and running in the Batch Execution mode, delivering great performance, but overall I suspect that having SORT iterator running in the Batch Mode is what truly delivers great performance for this execution plan.
 Comparing with SQL Server 2014 execution plan shows us the difference that lies in the presence of the Segment + Sequence Project (Compute Scalar) iterators vs Window Aggregate iterator in SQL Server 2016 execution plan. Once again do not forget about the Batch Mode for the Sort iterator that should make the huge part of the performance difference.
Comparing with SQL Server 2014 execution plan shows us the difference that lies in the presence of the Segment + Sequence Project (Compute Scalar) iterators vs Window Aggregate iterator in SQL Server 2016 execution plan. Once again do not forget about the Batch Mode for the Sort iterator that should make the huge part of the performance difference.
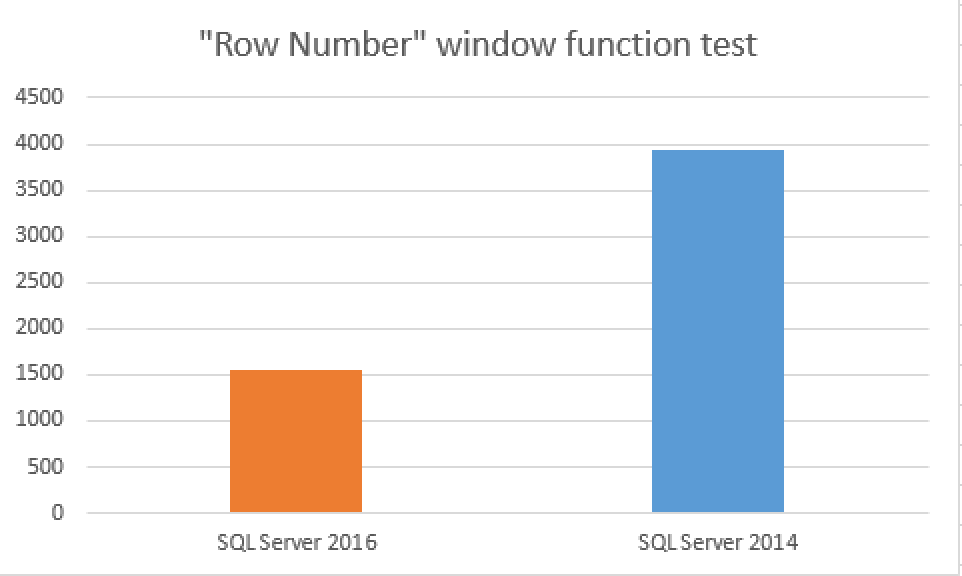 Comparison of the execution times gives a good overview that the in SQL Server 2016 for this function (ROW_NUMBER), we receive 2.5 times improvement on rather small dataset (7.6 Million Rows).
Comparison of the execution times gives a good overview that the in SQL Server 2016 for this function (ROW_NUMBER), we receive 2.5 times improvement on rather small dataset (7.6 Million Rows).
Notice that for different mathematical functions the different might be more or less significant, it will all depend on the executed operations and on the used datatypes. In what I have seen until now - going well over 8 bytes will always bring a performance penalty and sometimes it might be very significant.
Now it's time to take a look at another analytical window function - LEAD, to check how it's performance is getting updated with SQL Server 2016 CTP 2.1:
declare @res as Decimal(9,3); select @Res = Lead (SalesAmount, 1, 0) OVER ( Partition by DateKey order by DateKey ) from dbo.FactOnlineSales where DateKey < '2009-01-01';
![]() Looking at the execution plan from SQL Server 2016 CTP 2.1, you will find no Window Aggregate iterator, apparently because it is not implemented yet.
Looking at the execution plan from SQL Server 2016 CTP 2.1, you will find no Window Aggregate iterator, apparently because it is not implemented yet.
The difference in performance between SQL Server 2014 and SQL Server 2016 for the LEAD function is still noticeable, we are spending much more CPU (~17 seconds vs 11 seconds for SQL Server 2016 CTP 2.1), while overall time performance lies in the domain of SQL Server 2014 : 10 Seconds vs 11.5 Seconds for SQL Server 2016 CTP 2.1. I do not even try to make any judgement at this point, since we are dealing with a very early preview version.
I have done number of tests on the improvements in SQL Server 2016 CTP 2.1 and here is the table that I have compiled after my tests of the window functions:
UPDATED WITH SQL SERVER 2016 CTP 2.4 INFO:
| Function | Support in 2016 CTP 2.4 |
| LAG | yes |
| LEAD | yes |
| CUME_DIST | yes (partial) |
| FIRST_VALUE | no |
| PERCENTILE_CONT | yes |
| PERCENTILE_DISC | yes |
| PERCENT_RANK | yes (partial) |
| CHECKSUM_AGG | no |
| STDEV | yes |
| STDEVP | yes |
| VAR | yes |
| VARP | yes |
| MIN | yes |
| MAX | yes |
| AVG | yes |
| SUM | yes |
| COUNT | yes |
| COUNT_BIG | yes |
| ROW_NUMBER | yes |
| RANK | yes |
| DENSE_RANK | yes |
| NTILE | yes (partial) |
I will update this table in the near future, whenever Microsoft shall release updates for SQL Server 2016 CTPs and definitely there will be a detailed information on RTM.
to be continued with Columnstore Indexes – part 62 (“Row Groups Trimming”)