Welcome to the 2nd blog post in the Azure Columnstore series, as previously mentioned in the Azure Columnstore, part 1 – The initial preview offering.
If you are interested in all the articles, feel free to visit my whole Columnstore Series
Snapshot Isolation & Read Committed Snapshot Isolation
One of the most important missing pieces of the Columnstore Indexes on SQL Server 2012 & SQL Server 2014 was the lack of support for the Readable Secondaries on the Availability Groups.
This was in fact due to the lack of support for 2 of the principal transaction isolation levels – Snapshot & Read Committed Snapshot.
I have shown the lack of Snapshot isolation level support in Clustered Columnstore Indexes – part 7 (“Transaction Isolation”).
Now as a matter of a fact, both these isolation levels are enabled by default in Azure SQLDatabase – Both the READ_COMMITTED_SNAPSHOT and ALLOW_SNAPSHOT_ISOLATION database options are set to ON in Microsoft Azure SQL Database (Take from Azure SQL Database General Guidelines and Limitations).
To verify this fact it is enough to check the status information on my database at the sys.databases:
select name, snapshot_isolation_state, is_read_committed_snapshot_on from sys.databases
![]() As you can see on the picture, my SQL15 database has Snapshot Isolation level and Read Committed Snapshot both activated. Since the ALTER DATABASE syntax is not supported for Azure SQLDatabase at the moment, this means that those options cannot be deactivated and having functional Columnstore Indexes there means that support for both Isolation Levels is already implemented in the core SQL engine.
As you can see on the picture, my SQL15 database has Snapshot Isolation level and Read Committed Snapshot both activated. Since the ALTER DATABASE syntax is not supported for Azure SQLDatabase at the moment, this means that those options cannot be deactivated and having functional Columnstore Indexes there means that support for both Isolation Levels is already implemented in the core SQL engine.
This might sound logical, but you want some better proof than just simple logic of sys.databases DMV.
In order to test it I will run the following script to create a simple table with just 1 column with Identity values, filling out 2 full Row Groups and inserting an extra row into the Delta-Store:
create table dbo.MaxDataTable(
c1 bigint identity(1,1));
-- Create a Clustered Columnstore Index:
create clustered columnstore index PK_MaxDataTable
on dbo.MaxDataTable;
-- Insert 2 Sequential segments full of default values
declare @i as int;
declare @max as int;
select @max = isnull(max(C1),0) from dbo.MaxDataTable;
set @i = 1;
begin tran
while @i <= 1048576*2
begin
insert into dbo.MaxDataTable
default values
set @i = @i + 1;
end;
commit;
-- One value to force the closure of the 2nd Row Group
insert into dbo.MaxDataTable
default values;
-- Invoke Tuple Mover and compress delta-stores
alter index PK_MaxDataTable on dbo.MaxDataTable
Reorganize;
Now let's run a simple query, forcing Snapshot Isolation level:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT
select count(C1)
from dbo.MaxDataTable
where C1 = 10;
This query runs without any problems and to see the difference with currently available versions, feel free to execute the same script on the SQL Server 2014 version, you will definitely get a similar error message:
Msg 35371, Level 16, State 1, Line X
SNAPSHOT isolation level is not supported on a table which has a clustered columnstore index.
The fact that we have a working support for Columnstore Indexes combined with Snapshot & Read Committed Snapshot isolation levels, makes me very optimistic regarding Readable Secondaries support for the next version of SQL Server. :)
The Batch Mode
There has been a long time request to Microsoft for implementing support and functionality of the Batch Mode to operate under 1 core. Right now at the end of 2014 the requirement for Batch Mode is for the query to be executed with DOP >= 2.
I have started my investigation by executing the following query and analysing its execution plan (XML) in details:
select c1%10, avg(C1) from dbo.MaxDataTable where C1 < 1024500 group by c1%10;
![]() You can see that there are no parallel iterators in it, and if you consult the Actual Execution Mode for any of the relevant 4 iterators, you will find that all of them are being executed in the Batch Mode.
You can see that there are no parallel iterators in it, and if you consult the Actual Execution Mode for any of the relevant 4 iterators, you will find that all of them are being executed in the Batch Mode.
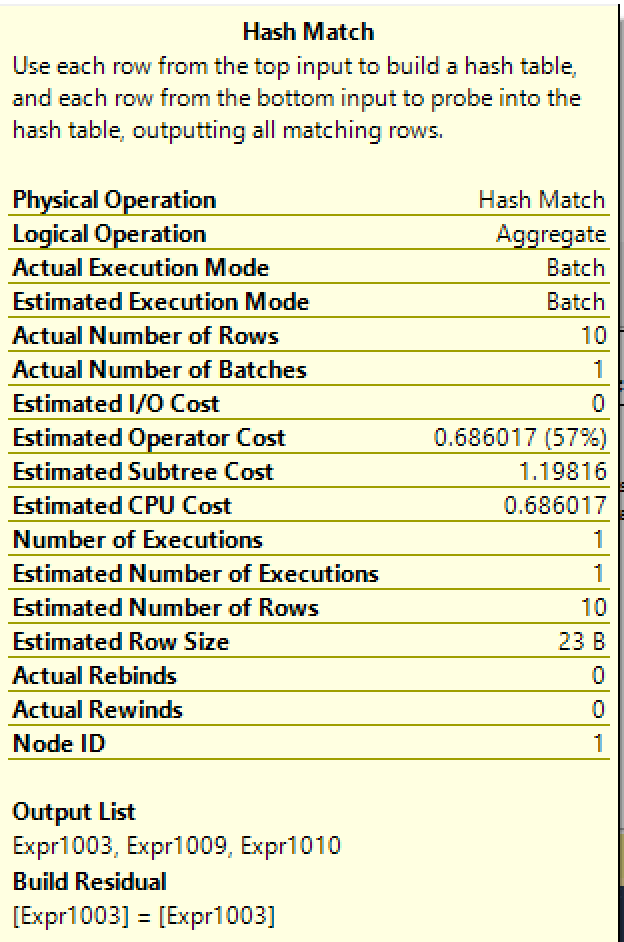 On the picture on the right side, you will see the example of Hash Match (Aggregate) iterator being executed in the Batch Mode.
On the picture on the right side, you will see the example of Hash Match (Aggregate) iterator being executed in the Batch Mode.
One very interesting thing striked me as I was looking at the execution plan - the Estimated Operator Cost for this iterator was 0.686017, which was extremely low to trigger the parallelism on SQL Server default settings (The default threshold equals to 5.0), and when I checked on the SELECT iterator the Estimated Subtree Cost it was equal to 1.19816. This means that the whole query query has a very low estimated cost, which by all standards should avoid any parallelism.
I do not know of any ways to change the threshold for parallelism on Azure SQLDatabase, and thinking logically about it - there should not be a way to do so on the instance level, but maybe one day we can have it control on the level of a database.
I decided to see what I can find in the execution plan which might enlighten me on the subject of the execution mode, and so I have opened the SELECT iterator properties to find the following:
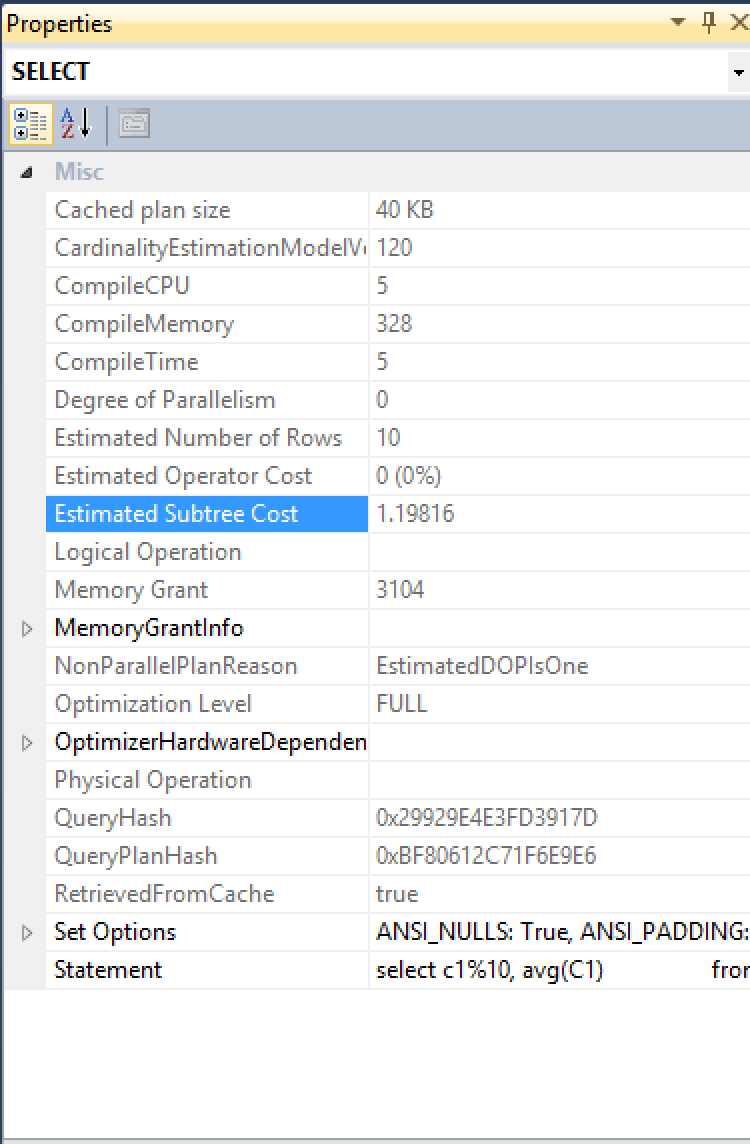 NonParallelPlanReason = EstimatedDOPIsOne, Nice :)
NonParallelPlanReason = EstimatedDOPIsOne, Nice :)
Memory Grant = 3104
Expanding the MemoryGrantInfo allowed me to discover that the SerialDesiredMemory was equal to RequestedMemory and was in fact equal to 3104 KB.
If you are running a query in the Single-Threaded Mode on SQL Server 2014, you will notice that the Degree Of Parallelism will equal to 0, like you can see in the case of the Azure SQLDatabase execution plan properties.
This all looks like the query was truly executed in a single threaded mode - there are no signs or reasons to believe in parallelism so far.
At this point I decided to open the XML and see what I can find there.
I extracted both execution plans from the Azure SQLDatabase and SQL Server 2014 CU4, saved them on the disk and opened with a great free comparison tool WinMerge:
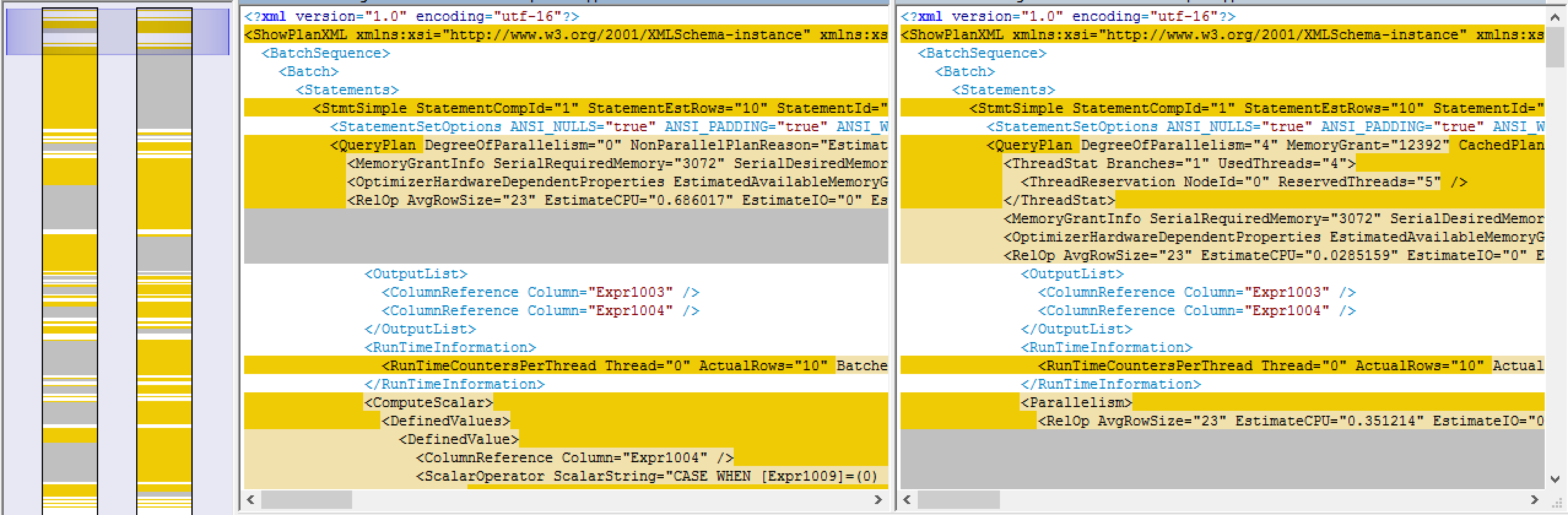
It is quite visible the number of differences between those 2 execution plans, that are being executed on the same data.
Looking inside the execution plans, I could clearly see the absence of the Parallelism tag for the Azure SQLDatabase, but one difference was even more interesting to me - The Reason For Early Termination Of Statement Optimisation aka StatementOptmEarlyAbortReason was not present at the Execution plan for Azure SQLDatabase.
And while some of the numeric differences make total sense, such as estimated costs, compilation times and resources - because the Hardware that I run my VM is different to the commodity Hardware being used for Azure SQLDatabase, there are some things that do not have explanation for the moment - the whole structure of the execution plan is quite different.
Further proof that we are truly single-threading the execution of the query in Azure SQLDatabse appears in a number of iterators with the attribute Parallel="false".
Another key element was the RuntimeInformation related to the iterators, where for SQL Server 2014 I could find a similar information (showing 4 execution threads + a control thread)
for Azure SQLDatabase I could clearly see just one thread being executed:
Naturally I did not give up easily and decided I forced DOP = 1 on the query:
select c1%10, avg(C1) from dbo.MaxDataTable where C1 < 1024500 group by c1%10 option (MAXDOP 1); go
This has not brought any changes to the execution plan besides the NonParallelPlanReason="MaxDOPSetToOne", Query hash values, and the query text itself, and so with all this I am really assuming that in Azure SQLDatabase we have the Batch Mode functioning with DOP = 1.
If its true, then I am naturally excited to see it implemented in the next version of SQL Serve
Unless somebody from Microsoft :) will explain me that I am wrong.
To make sure things are correct I have executed a number of quite expensive queries, such as:
select top 2000 row_number() over (order by id ) from dbo.BigDataTest order by id
which besides executing for 6 seconds (Sort iterator still runs in Row Execution Mode), had a StatementSubTreeCost="1005.46" making it truly a query to be run with multiple cores in a parallel execution plan.
to be continued ...