Continuation from the previous 42 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is dedicated to the Transaction Log behaviour, which might explain some of the behaviours of the Columnstore Indexes, observed in the earlier posts in the series.
I decided to see what’s going on with Transaction Log whenever we load data and compare it with the same structures based on Row Storage.
Important Note: Please make sure that your Transaction log is big enough for these experiments, by setting it appropriately high – in order to avoid regrowth I have set mine to 2 GB
First of all let’s set up a source table (HEAP) with some data in it. I load 100.000 rows into the sample table.
create table dbo.TestSource( id int not null, name char (200), lastname char(200), logDate datetime ); declare @i as int; set @i = 1; begin tran while @i <= 100000 begin insert into dbo.TestSource values (@i, 'First Name', 'LastName', GetDate()); set @i = @i + 1; end; commit;
Rowstore Heap
Let's kick of with a traditional Heap based on the row storage:
create table dbo.BigDataTestHeap( id int not null, name char (200), lastname char(200), logDate datetime );
Let's create a transaction where we simply load 10 rows from the dbo.TestSource table, but before executing the transaction I will checkpoint the T-log, and notice that my database is in Simple Recovery Model:
checkpoint -- Load 10 rows of data from the Source table declare @i as int; set @i = 1; begin tran while @i <= 10 begin insert into dbo.BigDataTestHeap --with (TABLOCK) select id, Name, LastName, logDate from dbo.TestSource where id = @i; set @i = @i + 1; end; commit;
For the transaction log analysis, I will use the following query:
select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTestHeap' order by [Log Record Length] Desc
 AS you see the log record length is 512 bytes and we are writing directly into the HEAP without Minimal Logging.
AS you see the log record length is 512 bytes and we are writing directly into the HEAP without Minimal Logging.
For analysing the total size of the t-log generated, I have used the following query before the start and after the commit of my transaction:
select sum([log record length]) as LogSize from fn_dblog (NULL, NULL);
The result is 7100 bytes, which is a nice number, but let's see what happens if we do the same with a Clustered Columnstore Table.
Clustered Columnstore
Now we shall basically repeat the same proceedings, but this time creating a table containing a Clustered Columnstore Index:
-- Crete our test table create table dbo.BigDataTest( id int not null, name char (200), lastname char(200), logDate datetime ); -- Create Columnstore Index create clustered columnstore index PK_BigDataTest on dbo.BigDatatest;
Let's load 10 rows from the TestSource into our test table:
checkpoint declare @i as int; set @i = 1; begin tran while @i <= 10 begin insert into dbo.BigDataTest --with (TABLOCK) select id, Name, LastName, logDate from dbo.TestSource where id = @i; set @i = @i + 1; end; commit;
Let's check our transaction log to see if the transactions are being logged differently:
-- This will not work, since the allocation unit name is not being recognized select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTest' order by [Log Record Length] Desc
Oh !!! There is nothing in the results!!! :(
It seems that for the Clustered Columnstore Indexes the table as itself is not being recognised as an allocation unit.
I will spare you time - it will work, if we indicate the full name of the table + Clustered Columnstore Index as a allocation unit, as shown on the query below (that is the first signal for me that there are some major changes underneath):
select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTest.PK_BigDataTest' order by [Log Record Length] Desc
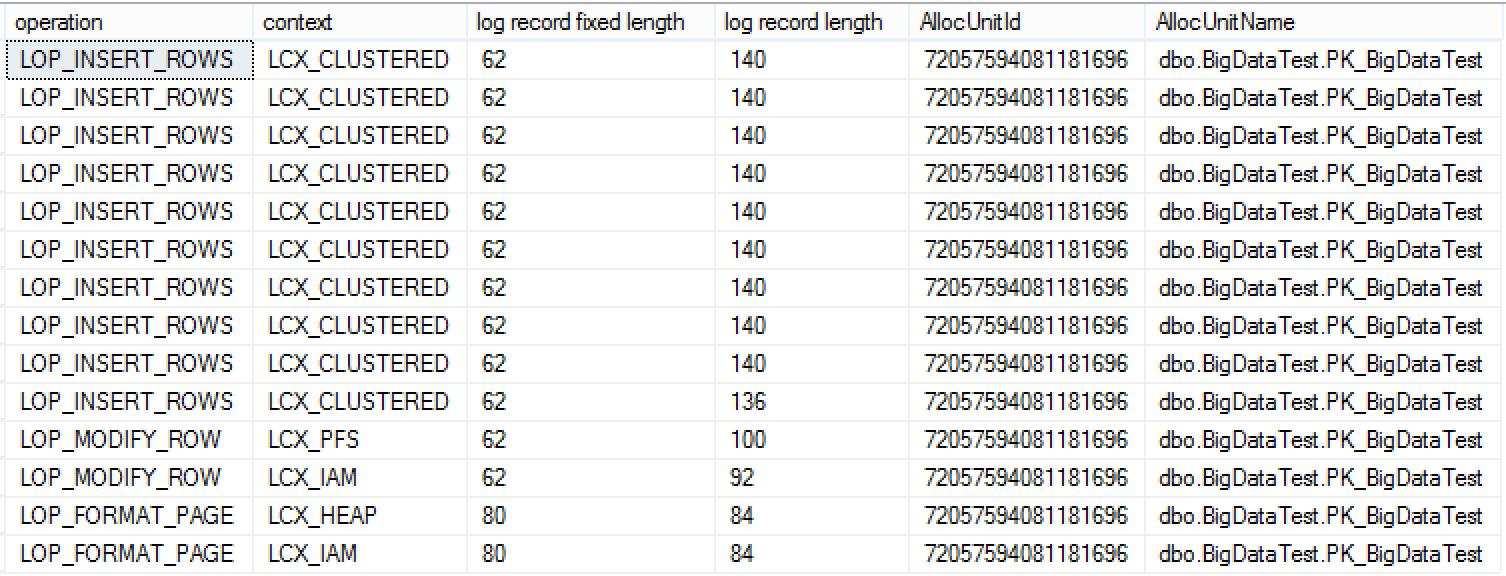 Take a look at this picture, we have just 140 bytes per inserted row as compared to 512 bytes when inserting into HEAP based on Row Storage.
Take a look at this picture, we have just 140 bytes per inserted row as compared to 512 bytes when inserting into HEAP based on Row Storage.
What about the total size of the transaction log size:
select sum([log record length]) as LogSize from fn_dblog (NULL, NULL);
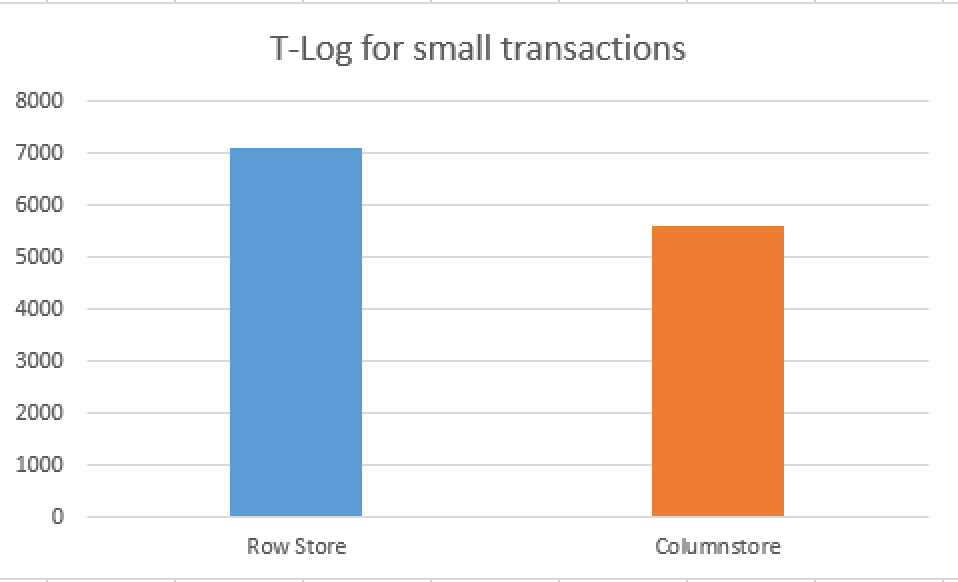 The final result in this case is 5622 bytes, which quite lower as the HEAP's 7100 bytes, and it is not surprising given what we have seen in the transaction log before. Given the difference on 10 rows, I ask myself what happens if we load not 10, but 10.000 rows:
The final result in this case is 5622 bytes, which quite lower as the HEAP's 7100 bytes, and it is not surprising given what we have seen in the transaction log before. Given the difference on 10 rows, I ask myself what happens if we load not 10, but 10.000 rows:
On my VM it took 1 minute and 43 seconds to load this data, and the size for the T-log was 1.863.688 bytes for the Clustered Columnstore Indexes, while for the Row Storage HEAP it took 1 minute and 48 seconds (slower!!!) and 5.552.872 bytes which good 3 times more than in the Clustered Columnstore Case.
I am quite confident that the difference in performance was small due to the storage speed - SSD has definitely helped Rowstore Heap to loose just 3 seconds to Clustered Columnstore, because for any other bigger cases we might be having a different waiting time, which could be measured in minutes.
Minimal Logging
For the small transactions it looks quite clear to me, but what about the typical situations for the DataWarehousing solutions when we load once at a time big amounts of data, taking use of minimal logging whenever possible – let's try out how big or small can we get our log with those transactions:
Drop and recreate our Heap & Clustered Columnstore tables
drop table dbo.BigDataTestHeap; drop table dbo.BigDataTest; create table dbo.BigDataTestHeap( id int not null, name char (200), lastname char(200), logDate datetime ); create table dbo.BigDataTest( id int not null, name char (200), lastname char(200), logDate datetime ); create clustered columnstore index PK_BigDataTest on dbo.BigDatatest;
Measure the Heap Load:
checkpoint insert into dbo.BigDataTestHeap with (TABLOCK) select id, Name, lastname, logDate from dbo.TestSource order by id;
 Great result, we have lowered our transaction log record size to 88 bytes right from the 512 bytes that we have had for sing simple transactions.
Great result, we have lowered our transaction log record size to 88 bytes right from the 512 bytes that we have had for sing simple transactions.
Now, let's measure the CCI Load:
checkpoint insert into dbo.BigDataTest with (TABLOCK) select id, Name, lastname, logDate from dbo.TestSource order by id;
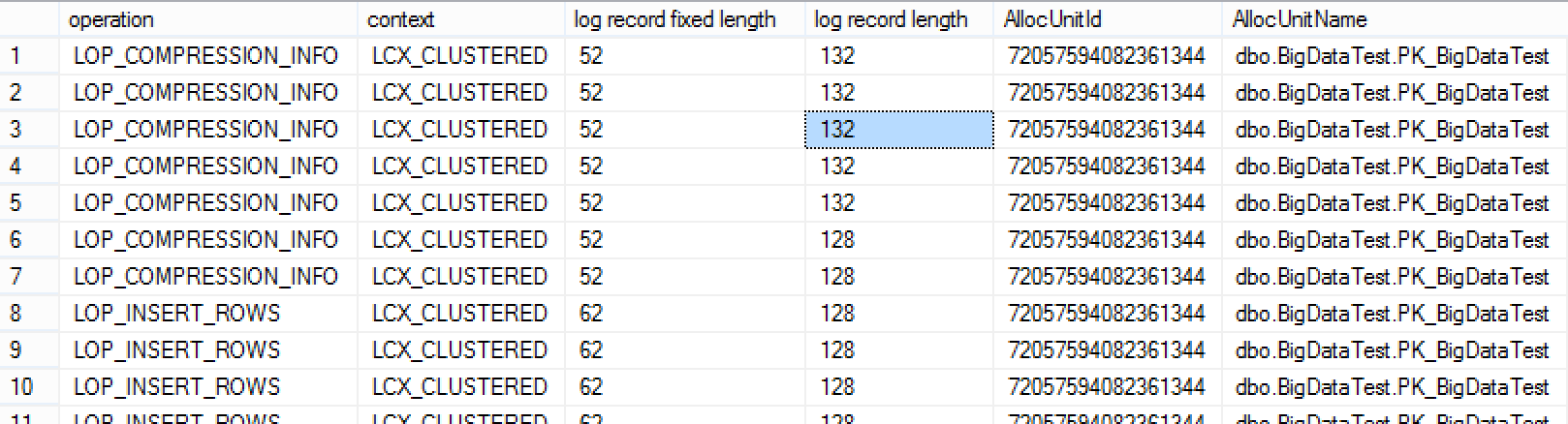 Wow, we have managed to lower just 12 bytes to 128 bytes, that is nothing special to say at least, especially since in this case we are clearly loosing in the terms of the transaction log performance to HEAP.
Wow, we have managed to lower just 12 bytes to 128 bytes, that is nothing special to say at least, especially since in this case we are clearly loosing in the terms of the transaction log performance to HEAP.
One of the more interesting things hear to find is the operation LOP_COMPRESSION_INFO, why is it happening here ? I have seen it a number of times in the transaction log even in the middle of the inserted data that makes a part of a transaction. Is this some kind of information that helps the compression algorithm to choose the right compression algorithm ? Very interesting what is going on here! :)
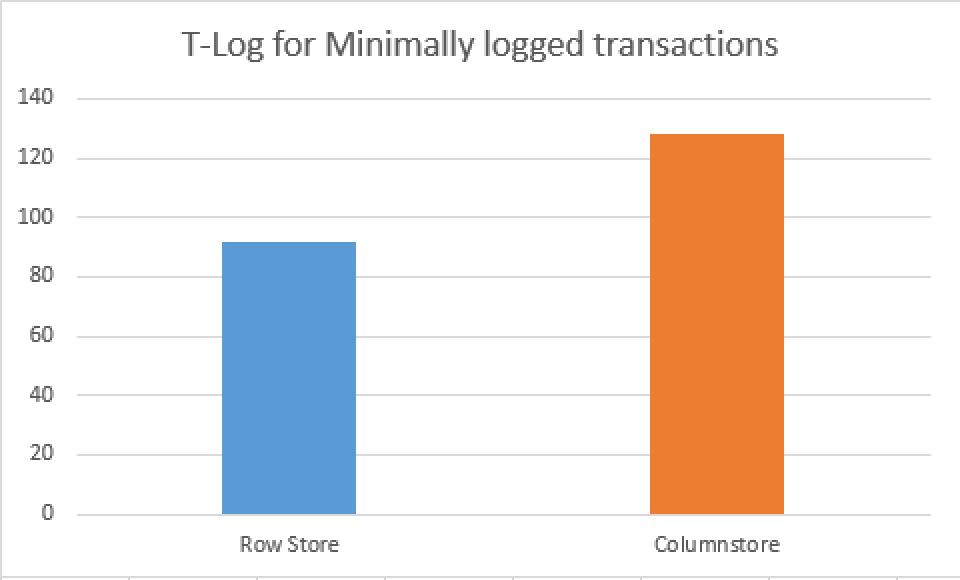 Now you can see the comparison between Minimal Logging for both Rowstore HEAPs and Columnstore Indexes.
Now you can see the comparison between Minimal Logging for both Rowstore HEAPs and Columnstore Indexes.
The difference in the transaction log size was enormous - 532.092 bytes for HEAP vs 12.876.632 bytes for Clustered Columnstore Table, which is 24 times more and which could result in quite a difference in the overall performance.
The performance bottleneck will determine largely the performance of the whole system, and if in your case - the bottleneck is in the transaction log that is getting hammered - then by all means consider loading data by the minimally logged transactions, but if you can't sort data and can't get a table lock on the destination - than a different situation shall rise.
Also, do not forget that if you are loading data into a HEAP that will be joined to a Columnstore Table as a partition, you will need to create Clustered Columnstore Index on it before switching it in, and if you are under the pressure of the total time for the data load, you might need to measure your system a couple of times before selecting what's right for your case.
I highly recommend Data Loading Performance Guide written by some of the most respected people in the SQL Server world.
Now, I wish that Microsoft would deliver a new White Paper on the matter of Clustered Columnstore... :)
Oh, and also I wish Microsoft could improve Data Loading into Columnstore in the next release – crossing my fingers ;)
to be continued with Clustered Columnstore Indexes – part 44 (“Monitoring with Extended Events”)
Niko:
First, thanks for your labor of love in writing all these posts about ColumnStore.
In this Post #43, I think there is a typo in last code snippet. I believe you meant it to be
“insert into dbo.BigDataTest” and not “insert into dbo.BigDataTestHeap”
Hi Gary!
Thank you for noticing and for reporting – I have corrected it now.
Really appreciate your kind words & support.
Best regards,
Niko Neugebauer
Please here you have used tablock which in case of HEAP will be minimally logged but is it really helpful in case of CCI?
Here batch size is < 100k in case of CCI so it will be loaded into delta store. which will be fully logged as here deltastore is clustered index on rowgrpid:tupleid with page compression
Hi Manish,
Yes, WITH (TABLOCK) will help you with minimal logging if the table is empty.
Loading into a Delta-Store indeed will be a painfully slow operation.
Best regards,
Niko Neugebauer
100k should have been threshold to check minimally logging on these 2 different beasts. Please suggest.
In first trickle insert case we got benefit in CCI case as data loaded into delta store is page compressed. So heap also should have been row compressed.
Hi Manish,
the compression on the heap was removed in SQL Server 2016, since it would not allow to have Columnstore Indexes with 700 integer columns for example (page compression limitations).
Best regards,
Niko Neugebauer