Continuation from the previous 22 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
Like for any technology, for Clustered Columnstore Indexes it is important to understand what are the best ways to run data loading processes.
I have decided to test different ways of loading data to analyze the pros and cons of each of the available methods:
We should try to load 3 Million Rows
1. Load data into a HEAP and then create Clustered Columnstore Index on that table
2. Load data into a table with Clustered Columnstore Index
3. Load data into a table with Clustered Columnstore Index using Bulk process
4. Load data into a HEAP using Bulk process and then create Clustered Columnstore Index
5. Load data into a HEAP using parallel insert and then create Clustered Columnstore Index on that table
I have used the following setup:
A VM with 4 GB of RAM, 2 Intel Core i7-3667U CPU Cores @ 2GHz, 256 GB SSD based on Samsung S4LNo53X01-8030 controller.
As in a lot of previous posts, I will keep on working with Contoso BI database which represents a great starting point.
To prepare everything and to make our original table FactOnlineSales work fast, I have dropped all the constraints and created a clustered Columnstore on it, by executing the following scripts:
alter table dbo.[FactOnlineSales] DROP CONSTRAINT PK_FactOnlineSales_SalesKey
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT PK_FactStrategyPlan_StrategyPlanKey
alter table dbo.[FactSales] DROP CONSTRAINT PK_FactSales_SalesKey
alter table dbo.[FactInventory] DROP CONSTRAINT PK_FactInventory_InventoryKey
alter table dbo.[FactSalesQuota] DROP CONSTRAINT PK_FactSalesQuota_SalesQuotaKey
alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCurrency
alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCustomer
alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimDate
alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimProduct
alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimPromotion
alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimStore
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimAccount
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimCurrency
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimDate
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimEntity
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimProductCategory
alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimScenario
alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimChannel
alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimCurrency
alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimDate
alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimProduct
alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimPromotion
alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimStore
alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimCurrency
alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimDate
alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimProduct
alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimStore
alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimChannel
alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimCurrency
alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimDate
alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimProduct
alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimScenario
alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimStore;
GO
Create Clustered Columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
I have also expanded and prepared TempDB as well as ContosoRetailDW database in order not to make my Computer spending any time on autogrowing data files or log files.
So, that is enough for the preparations, let’s kick off by creating our staging table:
CREATE TABLE [dbo].[FactOnlineSales_Staged]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL );
Now lets load 3 Million rows into our HEAP:
set statistics io on set statistics time on insert into dbo.FactOnlineSales_Staged select top 3000000 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate from dbo.FactOnlineSales;
This process took around 14 seconds time, while at the same time spending 11.5 seconds of CPU.
Now we shall need to build our Clustered Columnstore Index:
create Clustered Columnstore Index PK_FactOnlineSales_Staged on dbo.FactOnlineSales_Staged
This process took 18 seconds of execution time and around 24 seconds of CPU time. All in all, those 2 phases took us 32 seconds = 14 + 18, which seems to be reasonable, but it is still to early to arrive to any conclusions, so let us carry on.
Lets create a table with a Clustered Columnstore Index and lets load 3 million row into it:
CREATE TABLE [dbo].[FactOnlineSales_CCI]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ); create Clustered Columnstore Index PK_FactOnlineSales_CCI on dbo.FactOnlineSales_CCI insert into dbo.FactOnlineSales_CCI select top 3000000 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate from dbo.FactOnlineSales;
This time it took us around 19.5 seconds of total spent time and almost 19 seconds of CPUT time.
Now I will export the same 3 million rows into a file and will load it through the BULK process:
-- Enable XP_CMDSHELL
-- DO NOT TRY THIS AT ANY OTHER COMPUTER/SERVER then a Test Environment!
EXEC master.dbo.sp_configure 'show advanced options', 1
RECONFIGURE
EXEC master.dbo.sp_configure 'xp_cmdshell', 1
RECONFIGURE
-- *****************************************************************
-- Export into a file 3 Million rows of the FactOnlineSales table into a CSV
EXEC xp_cmdshell 'bcp "SELECT top 3000000 * FROM [ContosoRetailDW].dbo.FactOnlineSales" queryout "C:\Install\FactOnlineSales.rpt" -T -c -t,';
CREATE TABLE [dbo].[FactOnlineSales_Bulk_CCI](
[OnlineSalesKey] [int] NOT NULL,
[DateKey] [datetime] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [int] NULL,
[SalesQuantity] [int] NOT NULL,
[SalesAmount] [money] NOT NULL,
[ReturnQuantity] [int] NOT NULL,
[ReturnAmount] [money] NULL,
[DiscountQuantity] [int] NULL,
[DiscountAmount] [money] NULL,
[TotalCost] [money] NOT NULL,
[UnitCost] [money] NULL,
[UnitPrice] [money] NULL,
[ETLLoadID] [int] NULL,
[LoadDate] [datetime] NULL,
[UpdateDate] [datetime] NULL
);
create Clustered Columnstore Index PK_FactOnlineSales_Bulk_CCI
on dbo.FactOnlineSales_Bulk_CCI
-- Import Bulk Data
BULK INSERT dbo.FactOnlineSales_Bulk_CCI
FROM 'C:\Install\FactOnlineSales.rpt'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR ='\n'
);
This time it took us 27 seconds of time with 26.5 seconds of CPU time to load all the data into our Database. (I understand this test is quite biased since I am loading data on the same drive).
I decided to advance and load data into a Heap using the same bulk process just for comparison:
CREATE TABLE [dbo].[FactOnlineSales_Bulk_HEAP](
[OnlineSalesKey] [int] NOT NULL,
[DateKey] [datetime] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [int] NULL,
[SalesQuantity] [int] NOT NULL,
[SalesAmount] [money] NOT NULL,
[ReturnQuantity] [int] NOT NULL,
[ReturnAmount] [money] NULL,
[DiscountQuantity] [int] NULL,
[DiscountAmount] [money] NULL,
[TotalCost] [money] NOT NULL,
[UnitCost] [money] NULL,
[UnitPrice] [money] NULL,
[ETLLoadID] [int] NULL,
[LoadDate] [datetime] NULL,
[UpdateDate] [datetime] NULL
);
-- Import Bulk Data
BULK INSERT dbo.FactOnlineSales_Bulk_HEAP
FROM 'C:\Install\FactOnlineSales.rpt'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR ='\n'
);
create Clustered Columnstore Index PK_FactOnlineSales_Bulk_HEAP
on dbo.FactOnlineSales_Bulk_HEAP
It took 26 seconds to Bulk Load the data while spending 21 seconds of the CPU time, after that spending additional 23 seconds to build Clustered Columnstore Index while spending 20.5 seconds of the CPU time.
And so here we are in front of the last option for this test – to load data into a HEAP using parallel insert and then create Clustered Columnstore Index on that table:
set statistics io on set statistics time on set statistics io on set statistics time on select top 3000000 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate into dbo.FactOnlineSales_Parallel_HEAP from dbo.FactOnlineSales;
This time the process took amazing 9.5 seconds with almost 11 seconds of CPU time. You might be wondering what is going on here, but it is actually quite simple – SQL Server development team has developed a very important upgrade to the execution plans – Table Insert operator which is being executed in parallel mode.
This is quite remarkable, but now it’s time to create our Clustered Columnstore Index:
create Clustered Columnstore Index PK_FactOnlineSales_PARALLEL_HEAP on dbo.FactOnlineSales_PARALLEL_HEAP;
And so we have additional 18 seconds of time spent on the Clustered Columnstore Index creation with 24 seconds of CPU time being spent.
Now, lets take a look at what we have got here:
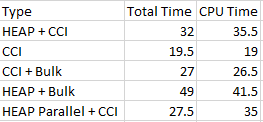
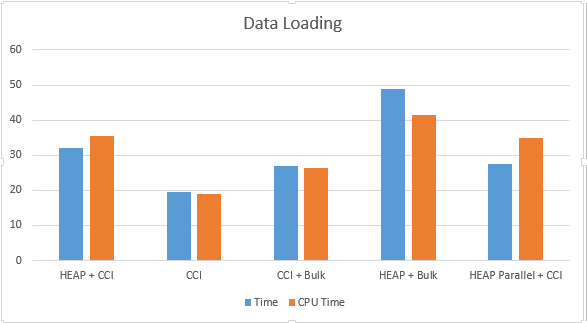
These results are quite sound in my opinion – it is very clear that should our priority be loading data as fast as possible (based on the requirements such as a small data loading window, a lot of data, etc), we should advance and choose building Clustered Columnstore Indexes on the table where we loading our data to.
From the other side, don’t forget those amazing 9.5 seconds spent on the parallel insert operation into a HEAP table – this might be a very important change should you be able to load data under such specific conditions.
I will be honest, since I was a bit shocked by seeing these results a couple of weeks ago and so I thought – maybe I should try running those queries on different system just to make a reality check. And so I went to Azure and created a reasonable VM. :) Here are my results (note that I have not even tried to run HEAP + Bulk there.)
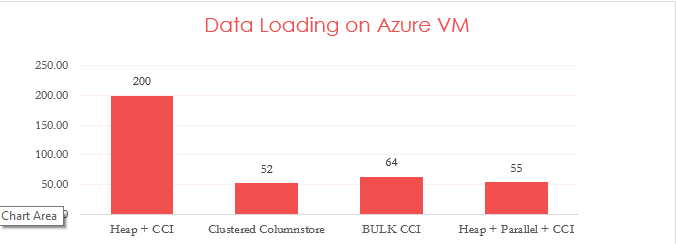
I guess that one of the “secret sauces” of the Clustered Columnstore is in its compression – we simply greatly optimize storage and spending less time on IO operation would simply mean spending less time in total, especially because storage are still the slowest elements in computers by far.
Stay tuned for the second part of this data loading article, since there are some other interesting aspects that we still need to look into – Compression results & created Dictionaries for example.
to be continued with Clustered Columnstore Indexes – part 24 (“Data Loading continued”)
It would be interesting to see the tests with many segments (>>3) so that the parallel speedup is more pronounced.
Hi Tobi, thank you for the comment. I will be getting there soon – hopefully before the new year publishing some materials regarding bigger amounts of data. :)