Continuation from the previous 9 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
Now it is time to see the actual compression in action, and so for the beginnings I have downloaded Contoso BI database. This is a good enough database to start playing with Microsoft BI – there are a couple of Fact tables with over 1 million rows. :)
I decided to experiment with the FactOnlineSales table, which has over 12 Million rows. After restoring the database from the download, lets see how big the FactOnlineSales is by executing the following command:
exec sp_spaceused '[dbo].[FactOnlineSales]', true;
In my case the occupied space of this table was 372.360 KB and the index size is 1568 KB, where the table itself has an exact number of 12627608 rows.
Now lets try to create a Clustered Columnstore Index on this table by executing the following command:
create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales] with ( DROP_EXISTING = ON );
which will fail, with the message that we definitely need to take care of all the foreign keys that this table has. Yes, Foreign Keys are not supported and so far it is known, they will not be supported for the v1 (SQL Server 2014). That might be a problem for some OLAP installations, while others can live with this.
Lets not be bothered by this at the moment, and let’s go and drop all the foreign keys (while before generating a script of all the foreign keys, you know, just in case ;)):
ALTER TABLE [dbo].[FactOnlineSales] drop CONSTRAINT [FK_FactOnlineSales_DimCurrency] GO ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer] GO ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate] GO ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct] GO ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion] GO ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore] GO
Lets try again – oh no! Now the SQL Server is saying something about the Constraints, but we do not have any constraints at all!!!
Wait a second, but there is a Primary Key, which is our clustered index … We need to drop it first:
ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey] GO
Now lets try again:
create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales]; GO
Now we have had finally a successful statement execution. Lets see how much space does it occupy – 169.424 KB ! Wow, we just managed to half the size of our table, going from ~372 MB right to 169MB. This is really impressive! If you think that it is not, then just think in GB or TB instead of MB :)
We are still very far from over, since I would love to see how good the new type of compression will work – the COLUMNSTORE_ARCHIVE compression, as I have already explained in the first part of the series is a slightly modified version of the LZ77 compression. Lets rebuild the table using this new compression algorithm and see the results.
alter index all on dbo.[FactOnlineSales] rebuild with ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE );
What is the size that the table occupy ? 78.480 KB ! Impressive, we just halfed the size of the our Columnstore Compression! Well, lets be honest, I do not expect the results to be that high in all the cases (and a much bigger test is coming soon), but for the fist beginning it is not a bad start ;)
Lets see how much space the actual uncompressed table occupies (we know that it has had a PAGE compression after we have restored the backup). I drop the Clustered Columnstore Index by using the following command:
drop index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales]; GO
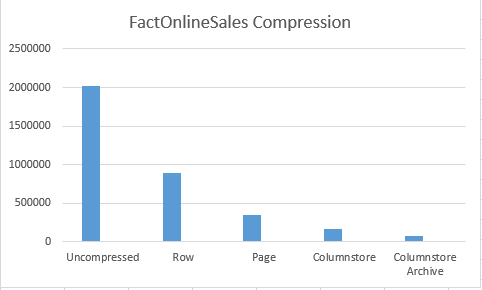
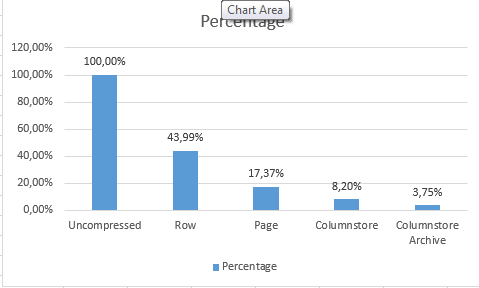
Let’s check the results: 2.023.824 KB – now that is a lot of space!
At this point I would love to understand all available options and understand what can be done with different compression methods, existing in SQL Server.
So now I will recreate my traditional Clustered Index, but this time without Primary Key constraint by executing the following command with ROW compression.
create clustered index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales] ( OnlineSalesKey asc ) with ( DATA_COMPRESSION = ROW ); GO
This time we have got a table with 890.248 KB of space occupied, which is a kind of expectable, since ROW compression is the one which uses CPU resources more lightly and compressing very lightly the content as well.
Next step for us would be to create a traditional Clustered Index using a PAGE compression:
create clustered index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales] ( OnlineSalesKey asc ) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE); GO
and this time we have a different result – 351.560 KB, I assume that the difference existing with the initial information was based on the fact that the table was not rebuild completely by default.
I would like to know how the existence of the traditional Clustered Index and the actual rebuild processes will affect the Clustered Columnstore Index. As you should already know, the Clustered Columnstore Index is not reordering the data, and as it is very logical, the ordered data gets better compression in a lot of cases. Lets execute the following script recreating Clustered Columnstore Index with default and with a Archive compressions and consulting the respective sizes of the tables:
/* ReCreate Clustered Columnstore */ create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales] with (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE); GO exec sp_spaceused '[dbo].[FactOnlineSales]', true; /* ReCreate Clustered Columnstore Archive */ create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.[FactOnlineSales] with (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE); GO exec sp_spaceused '[dbo].[FactOnlineSales]', true;
The results for my case were : 165.968 KB and 75.856 KB for default Columnstore and for Columnstore Archive compressions respectively. Now that is just a couple of percent, but if we think in GB and TB, then those numbers might start making much more sense. Scanning a table with 1 or 2 TB less might be a very different performance for a lot of queries, and so it is definitely worth trying to maintain information inside the tables with Clustered Columnstore Indexes ordered.
There is one more compression method that I would love to test before going into comparison and analysis – Nonclustered Columnstore. It would be extremely interesting in comparing it to the new Clustered Columnstore and see if they perform comparably. Lets execute the following script to drop the Clustered Columnstore Index and to create a Nonclustered Columnstore one:
— ReCreate Clustered Columnstore
create clustered columnstore index [PK_FactOnlineSales_SalesKey]
on dbo.[FactOnlineSales] with (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE);
GO
— ReCreate Clustered Columnstore Archive
create clustered columnstore index [PK_FactOnlineSales_SalesKey]
on dbo.[FactOnlineSales] with (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);
GO
Msg 1904, Level 16, State 1, Line 74I will be looking into some of the comparisons between Nonclustered and Clustered Columnstore in the very next part of the series.
The index ‘PK_FactOnlineSales_SalesKey’ on table ‘dbo.FactOnlineSales’ has 19 columns in the key list. The maximum limit for index key column list is 16. Oops, that does not went the way we wanted. So we are facing a limitation of the Nonclustered Columnstore Index of the maximum number of columns. It is nice to think that we have Clustered Columnstore that does not have any such type of limitations. :)
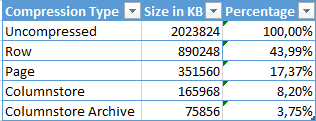 Let take a good look at the current results: it is quite visible that in this specific case we have managed to at least double the compression with each consecutive level of the compression. As it was expected the default Columnstore compression was much more effective then the Page compression, and the Columnstore Archive compression is definitively the sort of compression to be used when the IO is the biggest bottleneck and the CPU resources are available.
Let take a good look at the current results: it is quite visible that in this specific case we have managed to at least double the compression with each consecutive level of the compression. As it was expected the default Columnstore compression was much more effective then the Page compression, and the Columnstore Archive compression is definitively the sort of compression to be used when the IO is the biggest bottleneck and the CPU resources are available.
to be continued with Clustered Columnstore Indexes – part 11 (“Clustered vs Nonclustered compression basics”)
Can the clustered column store index queries remotely? I am getting the below error when i tried?
Msg 35377, Level 16, State 1, Line 1
When MARS is on, accessing clustered columnstore indexes is not allowed.
Murali,
as far as I know & remember – MARS was never supported for Columnstore Indexes, SQL Server 2012 included.
If you mean Linked Servers functionality under “remotely”, then since MARS is being used there – there should be no support for them as well.
Remote queries are quite a problematic area (statistics and decision where to join data – on local or remote host, etc), and since it potentially means moving billions of rows over a network, which will be always extremely slow compared to any other processing – I guess Microsoft decided not to spend time implementing its support.
Also, an upcoming Hekaton in SQL Server 2014 will not be supporting MARS.
Thanks Niko.
I think in SQL Server 2012 we can able to query remotely (via linked server) on a non clustered column store index.
Hey Niko,
I realise you wrote this a long time ago, but I was hoping you can still answer this.
In the post, you try to create a nonclustered columnstore index, and then get an error on too many columns. This surprises me. I have a table on my SQL Server 2012 instance that has a nonclustered columnstore index that includes 27 columns. And I just tried on my SQL 2014 instance to create a simple table with 20 columns and add a nonclustered columnstore index, and it works fine,.
I was hoping to review the code you used to compare it with mine and find the differences, to explain this different behaviour. But the code in your article appears to be a copy/paste error; it is code to create a clustered columnstore index.
So, my question is: do you still have this code, and could you share it?
Thanks!
Hugo
Hi Hugo,
thanks for catching it up – I was trying to recreate this and I believe now that I tried to create a traditional rowstore clustered index indicating all columns, which provoked the error. I have updated the article to remove the wrong parts.
Writing after Midnight leads to a lot of mistakes, but that’s the time I have for writing.
Hi, any thoughts on columnstore clustered indexes with say 40-50 columns? Is that effective and efficient and how it can affect queries? I am reluctant to amend existing clustered indexes and make them columnstore as the negative performance impact can be substantial. Any thoughts? At the moment I am only looking to replace nonclustered with columnstore nonclustered. In fact 4-5 non clustered with a combined columnstore. Any thoughts? Thank you!
Panos: One of the key differences between columnstore indexes and traditional (rowstore) indexes, is that for columnstore indexes adding extra columns does NOT impact their effectiveness.
You also need to understand that rowstore and columnstore indexes serve very different purposes. You write that you write traditional nonclustered indexes with a nonclustered columnstore index; depending on the types of queries that might be great … or it might be disaster. If the indexes are now used to select single rows or small subsets out of a large tables, then there is no way that a columnstore index will ever be able to give you comparable performance. However, for queries that handle large amounts of data a columnstore index (either clustered or nonclustered) is almost guaranteed to outperform traditional indexes by a huge factor.
So the choices you are facing are more complex than you appear to realize. Perhaps it makes sense to add a nonclustered columnstore as an additional index rather than as a replacement (and in that case I recommend adding all columns except those with unsupported data types). Perhaps it then also makes sense to drop or change the existing nonclustered indexes, if they now need to support less queries, to indexes more suitable for the queries that do still need rowstore indexes.
And on the other hand, perhaps you will gain performance benefit from replacing the existing rowstore clustered index with a columnstore clustered index – that depends on a lot of factors and you will really need to do an elaborate test of the alternatives. A space saving is almost 100% guaranteed if you move to a clustered columnstore, but performance is impossible to predict without knowing exactly all that is going on in your database.
Good luck with making these decisions, and I hope that you’ll find that columnstore indexes (when used appropriately) work out just as well for you as they do for me!
My experience has been that replacing a clustered index with a columnstore doesn’t always work very well for performance. Maybe if I was designing the database from scratch it could be different. My approach is to get unused (statistics wise) indexes and create a substitute with a colummstore and see how the database responds in terms of index usage. Then I can drop these indexes and take it from there.
Except for size is anything else I need to worry about the nonclustered columnstore. For example will the optimiser get confused by the 30columns columnstore as it may have too many options to choose from? I have some tables with around 10 indexes at the moment + the columnstore that I will add so having too many optimiser options plus more time to update a 30 column columnstore instead of 10 column columnstore. Thank you for any answers.
Hi Panos,
if you are on SQL 2014 or earlier, than any short-range scan or point-lookup will suffer significant penalties on the Clustered Columnstore, for that purpose Nonclustered Columnstore with secondary Rowstore Indexes is more efficient. On SQL 2016 you can mix CCI and secondary Rowstore Indexes.
Regarding the information that you have published about your current problem – is it 2016 or any other version ?
Generally NCCI coexists very fine with all other indexes, sometimes you will need to hint it with (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) if your statistics are not-expressive enough to convince Query Optimiser not to use NCCI.
Best regards,
Niko Neugebauer