Continuation from the previous 113 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blogpost is focusing on the unsung (and at the moment undocumented) improvement that is connected to the Columnstore Indexes, the communication between SQL Server relational engine and the Machine Learning Services in SQL Server 2017. MACHINE … LEARNING … SERVICES ? Niko, are you OK ? Does the air of Portland (wonderful, wonderful) is doing good to you ? Yes, it does! :)
Indeed, I am taking about the Machine Learning Services in SQL Server 2017 – with currently R & Python languages being the weapons of choice for the data scientists, doing their work with SQL Server 2017.
But what about the Columnstore Indexes ? How do they relate/influence the Machine Learning Services? – It is all about the communication and the way the data is being delivered to and from the Machine Learning Services.
If you have been trying to follow the recent developments in the SQL Server space (especially since 2016 version, where R language made its premier), you should surely have heard mentions about the function sys.sp_execute_external_script in the SQL Server 2016+.
If this is the first time for you, then I urge you to take a look at the official documentation, the basic examples at Microsoft Documentation as well as at the article that my old friend Vitor Montalvão has written at MSSQLTips.
But let us not loose the focus on this very tiny blog post – how does SQL Server 2017 and the Columnstore Indexes make things better/faster for the Machine Learning Services ?
The answer is very simple, and it is all about how the data is being delivered to the Machine Learning Services – I am talking here about the Row Execution Mode and the our favourite Batch Execution Mode. :)
Let us set up a simple table with a Clustered Columnstore Index and load there the perfect number of rows into it – 1048576 rows:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
TRUNCATE TABLE SampleDataTable;
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (1 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) t
OPTION (MAXDOP 1);
Now, we can pump the content of the SimpleDataTable into the Machine Learning Services (R language in this case) and then without doing anything with this data, return it back to SQL Server. I have chosen this example without any involvement of the R language, so that I can focus on the IO communication capabilities of the SQL Server with Machine Learning Services.
While testing the improvement on the SQL Server 2017, please bear in mind that the improvement is like so many other Query Optimiser improvements is dependent on the Compatibility Level, and so in order to see how approximately (because there are other optimisations) it looked on the SQL Server 2016, we need to set the compatibility level on our database [Test] to 130, which corresponds to SQL Server 2016. To see the improvement functioning at its best, we need to set the compatibility level of our database to 140 (corresponding to SQL Server 2017).
So let us run the test query, which is reading and returning data from the dbo.SampleDataTable table, and let’s run the query first in SQL Server 2016 compatibility mode, while the second execution will be running in SQL Server 2017 mode
SET STATISTICS TIME, IO ON
ALTER DATABASE [Test] SET COMPATIBILITY_LEVEL = 130
GO
EXECUTE sp_execute_external_script
@language = N'R'
,@script=N'OutputDataSet<-InputDataSet;'
,@input_data_1 = N'SELECT C1 FROM dbo.SampleDataTable'
WITH RESULT SETS ( (c1 INT) );
ALTER DATABASE [Test] SET COMPATIBILITY_LEVEL = 140
GO
EXECUTE sp_execute_external_script
@language = N'R'
,@script=N'OutputDataSet<-InputDataSet;'
,@input_data_1 = N'SELECT C1 FROM dbo.SampleDataTable'
WITH RESULT SETS ( (c1 INT) );
Take a look at the execution plans:
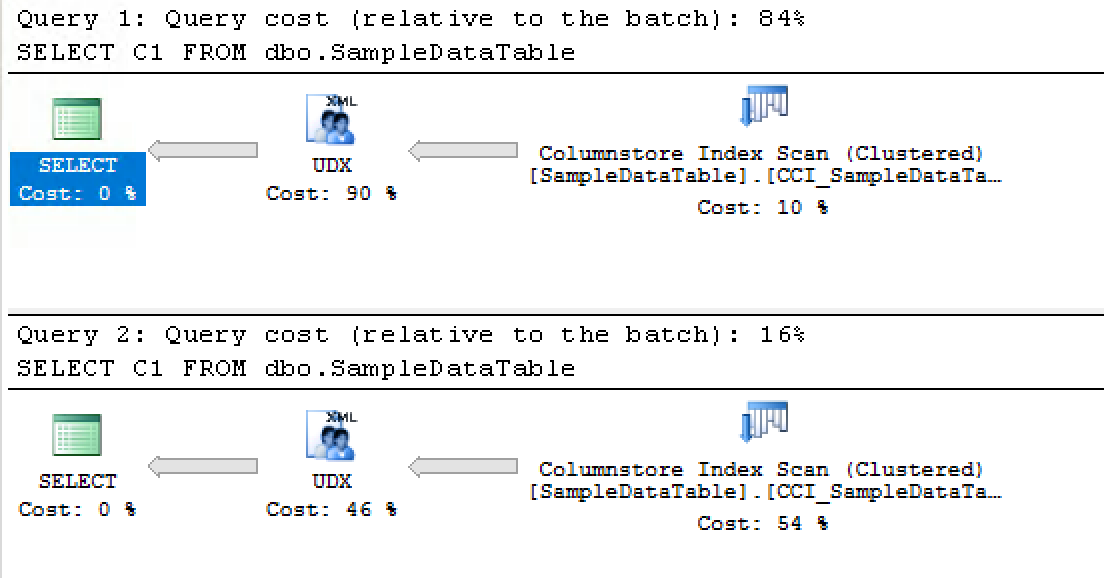
You can see that the estimated execution is already quite different, having the first one (2016) being significantly slower than the second one (2017).
The secret is all hidden behind the UDX iterator, which is doing exactly the IO operations between the relational engine of SQL Server and the Machine Learning Services.
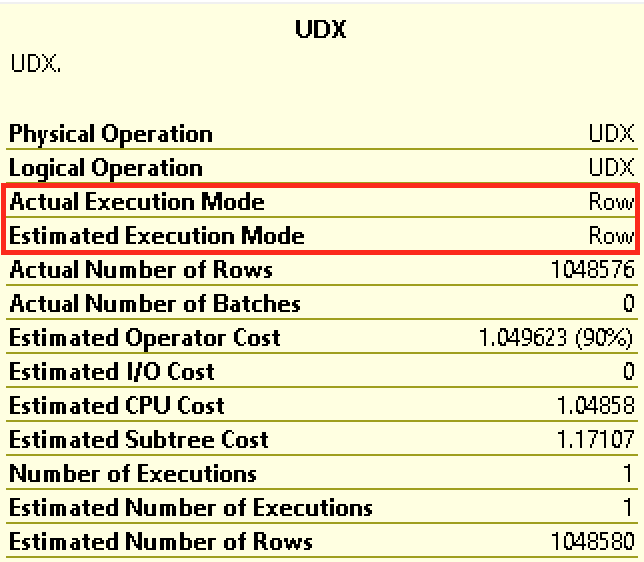
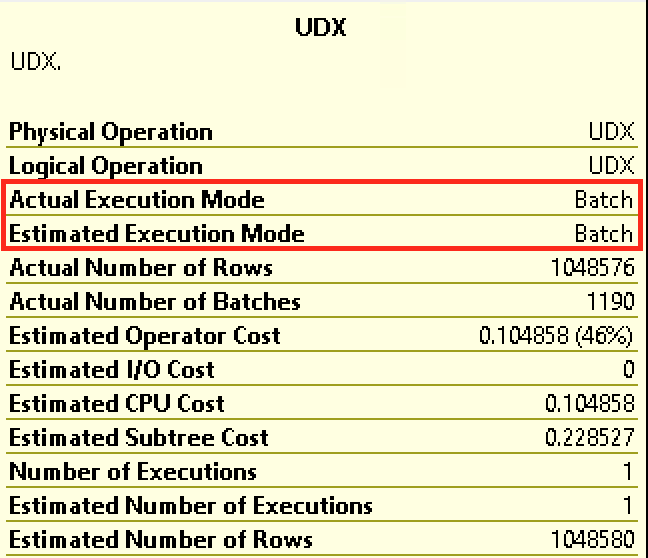
Take a look at the details of each of the iterators, where the UDX in SQL Server 2016 is running in Row Execution Mode, and the UDX in SQL Server 2017 is running in Batch Execution Mode:
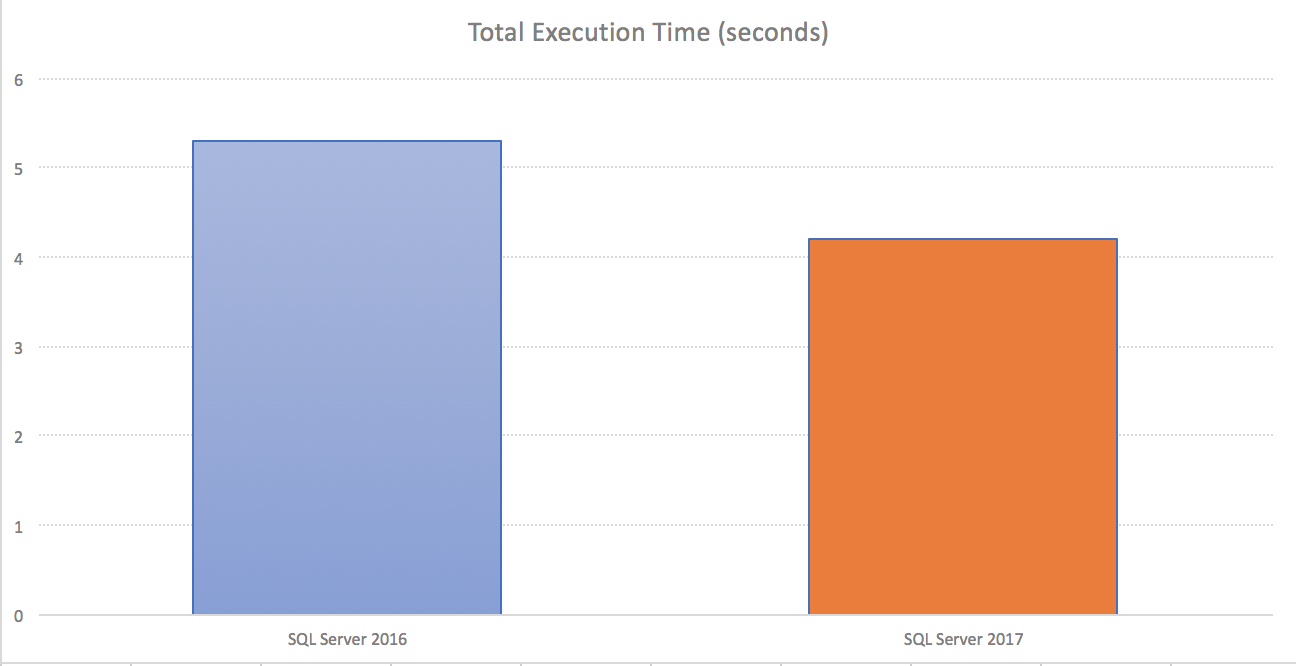
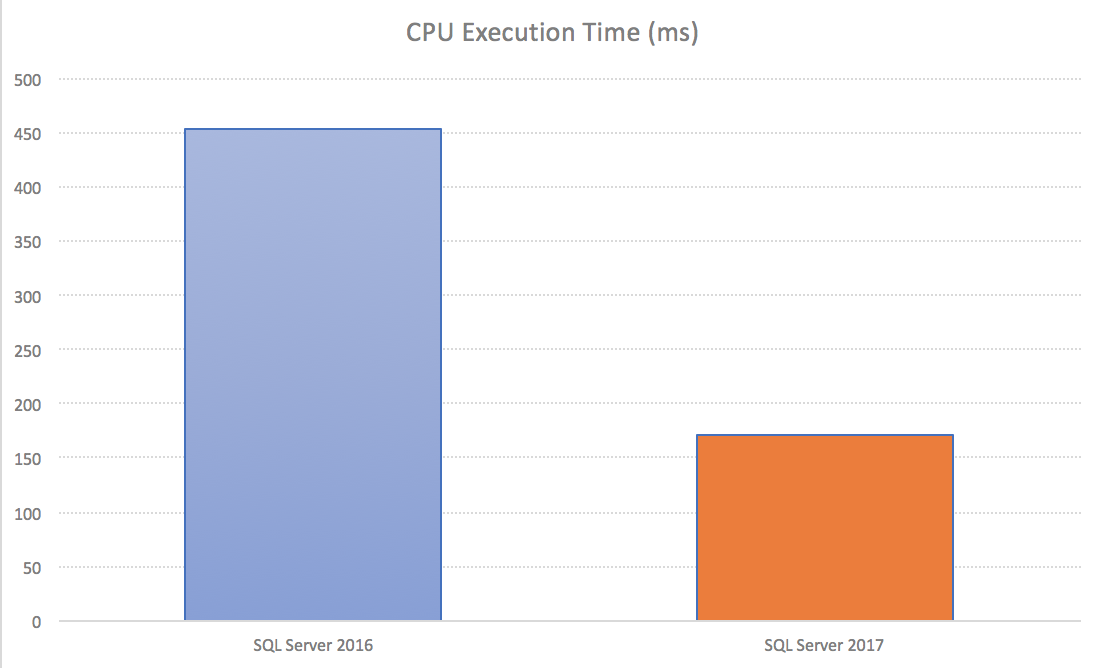
Take a look at the impact that the different execution modes brought on my test VM on Azure, with the Total Execution Time and the CPU time spent on the operation:
Final Thoughts
I expect not just a couple of rows to be sent over for the Machine Learning Services, but huge tables with million of rows, that also contain hundreds of columns, because this kind of tables are the basis for the Data Science and Machine Learning processes.
While of course we are focusing here on rather small part of the total process (just the IO between SQL Server relational Engine and the Machine Learning Services), where the analytical process itself can take hours, but the IO can still make a good difference in some cases.
I love this improvement, which is very under-the-hood, but it will help a couple of people to make a decision of migrating to the freshly released SQL Server 2017 instead of the SQL Server 2016.
to be continued with Columnstore Indexes – part 115 ("Bulk Load API and Pressure")