Continuation from the previous 43 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is dedicated to the monitoring aspects of the Columnstore Indexes, which should help you understanding what is going on with your production system.
Columnstore Monitoring Options
First of all we have all normally useful DMV’s that are useful for RowStore as well, such as sys.object, sys.partitions, etc.
For SQL Server 2014 specifically we have 3 DMV’s which can provide informations on the Columnstore Indexes: sys.column_store_dictionaries, sys.column_store_row_groups & sys.column_store_segments – they have been described in the part 5 (“New Meta-Information and System Stored Procedure”).
But most of all we have a number of Extended Events that will allows us to see a lot of events that are untraceable from any other sources to my knowledge.
Extended Events
If you open Extended Events and try to search for anything related to Columnstore Indexes, you will find just a couple of items, no matter if you are using “Columnstore” or “Column_Store” search words inside the Extended Events GUI.
That is a very poor number, considered how important the feature is and how much it delivers.
But let’s do not give up and use a couple of basic tricks:
 – Enable Debug Channel for the searched Extended Events. It is disabled by default (no comments) and some of the most interesting events happening with Columnstore Indexes are located inside this Channel.
– Enable Debug Channel for the searched Extended Events. It is disabled by default (no comments) and some of the most interesting events happening with Columnstore Indexes are located inside this Channel.
Once you enable it, the number of easily found events jumps to 17, which is more than double from the default number.
I confess that usually I do not search directly inside the GUI, but use Extended Events views to search for whatever I need at the moment. Here is the query that I have used for this blog (notice that I manually filtered out some of the results that are not connected to the Columnstore Indexes):
select p.name AS package_name,
o.name AS source_name,
o.description
from sys.dm_xe_packages AS p
inner join sys.dm_xe_objects AS o
on p.guid = o.package_guid
where (p.capabilities IS NULL OR p.capabilities & 1 = 0)
and (o.capabilities IS NULL OR o.capabilities & 1 = 0)
and o.object_type = 'event'
and
(
p.description like '%column_store%' or p.description like '%columnstore%' or
o.description like '%column_store%' or o.description like '%columnstore%' or
o.name like '%column_store%' or o.name like '%columnstore%'
or o.name like '%batch%' or o.description like '%batch%' or p.description like '%batch%'
or o.name like '%dictionary%' or o.description like '%dictionary%' or p.description like '%dictionary%'
)
and o.name not in ('sql_batch_completed','sql_batch_starting','sql_statement_recompile','plan_guide_successful','plan_guide_unsuccessful','uncached_sql_batch_statistics','expression_compile_stop_batch_processing');
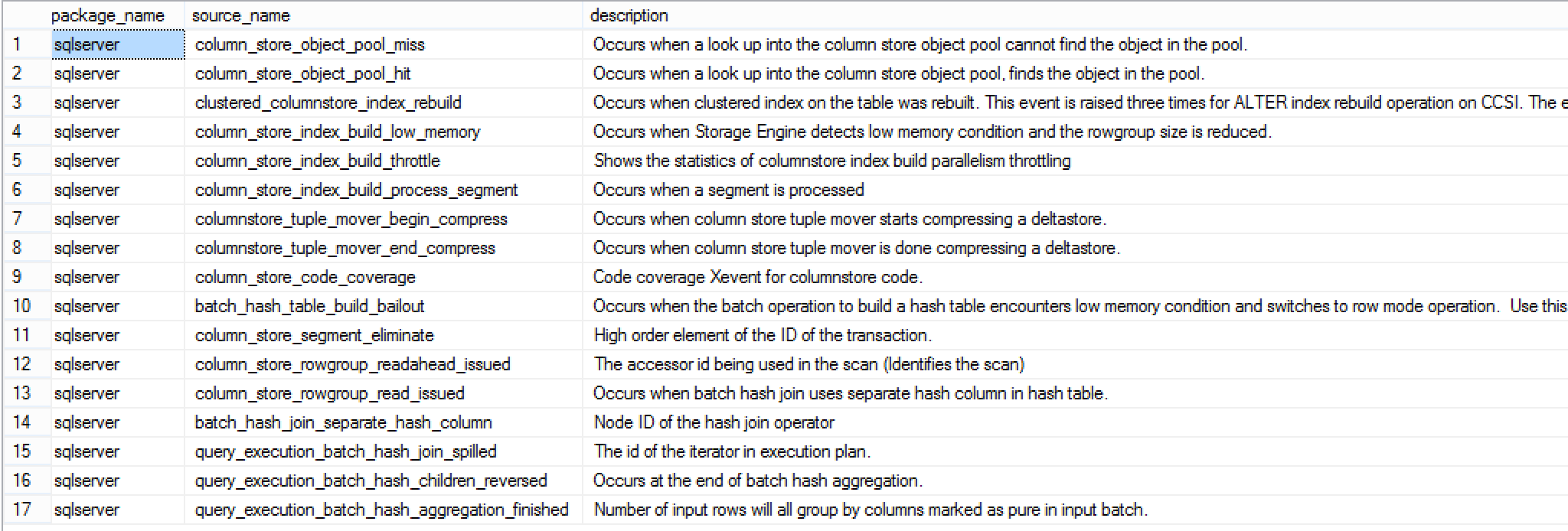
At this point I have grouped above listed extended events into the following groups:
1. Columnstore Index Creation (clustered_columnstore_index_rebuild, column_store_index_build_low_memory, column_store_index_build_throttle, column_store_index_build_process_segment, column_store_code_coverage)
2. Tuple Mover (columnstore_tuple_mover_begin_compress, columnstore_tuple_mover_end_compress)
3. Columnstore Processing (column_store_segment_eliminate, column_store_rowgroup_readahead_issued, column_store_rowgroup_read_issued)
4. Batch Mode (batch_hash_join_separate_hash_column,
query_execution_batch_hash_join_spilled,
query_execution_batch_hash_children_reversed,
query_execution_batch_hash_aggregation_finished,
batch_hash_table_build_bailout)
5. Columnstore Object Pool – Memory Structures (column_store_object_pool_miss, column_store_object_pool_hit)
In this blogpost I will list and describe every Extended Event that is known to me, related to Columnstore Indexes, available in SQL Server 2014 CU3 (notice that there are a couple of bugs in the descriptions, I am submitting Connect Items on those issues):
column_store_object_pool_miss – Occurs when a look up into the column store object pool, misses finding the object in the pool.
This event occurs whenever we are trying to reach for a Segment that is not currently present inside Columnstore Object Pool and the data needs to be read from the Disk Drive.
column_store_object_pool_hit – Occurs when a look up into the column store object pool, finds the object in the pool.
This event is the opposite of the previous one. This is the type of event you would love to see on your instance while reaching for the data from your Columnstore (Clustered & Nonclustered) Indexes.
clustered_columnstore_index_rebuild – Occurs when clustered index on the table was rebuilt. This event is raised three times for ALTER index rebuild operation on CCSI. The event is raised when the operation takes lock on index rebuild resource, when lock is taken on the table and when S lock on the table is upgraded to SCH_M lock to switch indexes in metadata.
This is an Index Rebuild control event.
column_store_index_build_low_memory – Occurs when Storage Engine detects low memory condition and the rowgroup size is reduced.
Storage Engine event that helps you to find situations with Memory or Dictionary pressures on your Columnstore structures. You will definitely want to avoid this type of events, unless you really know what you are doing and you are decreasing the number of rows inside your Row Group on purpose.
column_store_index_build_throttle – Shows the statistics of columnstore index build parallelism throttling You will be able to sample some information whenever your Columnstore Index is suffering pressures during the build process.
column_store_index_build_process_segment – Occurs when a segment is processed.
This event is happening every time a Row Group compression is finished while building/rebuilding a Columnstore Index. The name is not 100% correct since it is actually a Row Group creation and not just a segment – the information contained in this event is truly spread over all Segments of the Rowgroup.
The awesome part of this event is the ability to see live how many rows are being populated inside each of the specific Row Groups and if there is any reasons for trimming it’s maximum number (pressure).
columnstore_tuple_mover_begin_compress – Occurs when column store tuple mover starts compressing a deltastore.
This event marks the start of the Tuple Mover work, which includes automated as well as the manual invocations for the Tuple Mover. It includes the undocumented hint (COMPRESS_ALL_ROW_GROUPS = ON).
columnstore_tuple_mover_end_compress – Occurs when column store tuple mover is done compressing a deltastore.
The event that marks the end of Delta Store compression. Happens only after columnstore_tuple_mover_begin_compress and it marks the end of the conversion process from Delta Store into a compressed Row Group.
column_store_code_coverage – Code coverage Xevent for columnstore code.
Behind this description you will find the most useful event for monitoring Columnstore Index build process – it basically represents advanced logging for the Dictionaries creation.
column_store_segment_eliminate – High order element of the ID of the transaction.
One of the best ways to monitor the Segment elimination process in production or QA environments. Not intrusive and does not involve error log. :)
column_store_rowgroup_read_issued – Occurs when batch hash join uses separate hash column in hash table.
This event will help you to determine if a particular Row Group is being accessed or not.
column_store_rowgroup_readahead_issued – The accessor id being used in the scan (Identifies the scan)
This event is used to identify Read-Aheads issued for reading the RowStore data from Columnstore Indexes.
batch_hash_table_build_bailout – Occurs when the batch operation to build a hash table encounters low memory condition and switches to row mode operation. Use this event to identify performance issues due to low memory condition.
This event is a good way to determine memory pressure inside of the execution plan, whenever we are building a hash table (hash match or hash aggregate) which does not receive enough memory to complete it’s operation without spilling to disk.
batch_hash_join_separate_hash_column – Occurs when batch hash join uses separate hash column in hash table.
Functionality Unknown. Currently Investigating. :)
query_execution_batch_hash_join_spilled – Occurs each time when hash join spills some data to disk in batch processing.
One more event focused on the memory aspect of the Batch Mode processing.
query_execution_batch_hash_children_reversed – Occurs each time when hash join reverses build and probe side while processing data spilled to disk.
This event allows you to catch difficult situations when hash sides are reversed and build table becomes a pr. Though at this point I do not know for sure all possible reasons for this, I suspect that wrong estimates should be the primary reason for this event to kick-in, and the fact of build table not fitting the available memory should be the key indicator for this functionality to kick-in.
query_execution_batch_hash_aggregation_finished – Occurs at the end of batch hash aggregation.
This event is a good way to determine Hash Aggregation iterators occurrence and the moment they finish processing Columnstore Index in your execution plans.
to be continued with Clustered Columnstore Indexes – part 45 (“Multi-Dimensional Clustering”)
Hi, both column_store_object_pool_miss and column_store_object_pool_hit have the same description. Probably a copy-paste error.
Hi Tom,
thank you for noticing – I have updated the article.
Best regards,
Niko Neugebauer