Continuation from the previous 134 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Not since SQL Server 2008 that Microsoft has added a new base data type to SQL Server, but in SQL Server 2025 they have added not 1 but whole 2 new data types – Vector and JSON. The first one (Vector) and the corresponding index (Vector Index) are described in details in the Columnstore Indexes – part 134 (“Vectors and Columnstore Indexes”) and this post is dedicated to the new JSON data type and the new JSON Index and their compatibility with the Columnstore Indexes and the Batch Execution mode.
One common trait for the Vector & JSON Indexes is that both come with a big number of limitations and they are all enabled under a “Preview” option, making them unsuitable for the most production environments.
TLDR: the outcome of the SQL Server 2025 RTM for JSON & Columnstore & Batch Mode looks the following way:
| Feature | Clustered Columnstore | Nonclustered Columnstore | In-Memory Columnstore | Ordered (CCI & NCCI) | Batch Mode on Columnstore | Batch on Rowstore |
|---|---|---|---|---|---|---|
| JSON_datatype | – | – | – | – | – | – |
| JSON_Index | – | – | – | – | – | – |
Intro
I have met JSON format for the first time around 20 years ago, in my Web times – somewhere around 2006/2007, at the times when the most people around me were largely concerned with XML. Since then, it has evolved into the widely accepted format, substituting XML as a default RPC/API/Data Exchange(but below CSV) and now, in SQL Server 2025 it has arrived in the form of the new data type and the new type of index. Better now then never. :)
The usage of the JSON format is so widely spread by now that one can not point only towards OLTP scenarios for it. Not just API invocations need JSON, but a lot of data exchange for ELT processes are taking advantages of the hierarchical possibilities, provided by JSON format. Hierarchies form relations, just like Relational databases are not substituted by the unstructured data, so the need for the hierarchical data needs to be satisfied and by now it looks that JSON is the default format for this purpose.
HTAP scenarios have never disappeared from the horizon, and this is where the need for Nonclustered Columnstore Indexes and In-Memory Columnstore Indexes comes from.
Once data lands in OLTP system, it eventually needs to be extracted, transformed and loaded into the Data Warehouse. And that’s where the need for Clustered Columnstore Indexes comes for. While in some cases, the extraction process might normalize/denormalize the data into separate columns/tables, but I am confident that there will be always enough cases where such work is nearly impossible (for example, if one has to create way too many tables/columns or the schema shifting is simply unsustainable).
Executing within the scope of the database, the following statement will enable the preview features on our SQL Server database:
ALTER DATABASE SCOPED CONFIGURATION SET PREVIEW_FEATURES = ON;
JSON data type
Just like in the case of testing the combination of the Vector data type with Columnstore Indexes, the idea is to test the very basics of the JSON data type and its possible combination with different types of Columnstore Indexes, based on SQL Server 2025 RTM. As Microsoft mentions in the documentation, they MIGHT promote features to GA in one of the upcoming CUs (Cumulative Updates), so I am explicitly mentioning the RTM release here.
Let’s create a basic test table with a Nonclustered Primary Key and a JSON column, attempting to add Columnstore Indexes to this structure:
DROP TABLE IF EXISTS dbo.json_columnstore;
CREATE TABLE dbo.json_columnstore
(
id INT PRIMARY KEY NONCLUSTERED,
content JSON
);
CREATE CLUSTERED COLUMNSTORE INDEX CCI_json_columnstore on dbo.json_columnstore;
This execution of the above script results in the following error message:
Msg 13672, Level 16, State 1, Line 11 Table 'json_columnstore' needs to have a clustered primary key with less than 32 columns in it in order to create a JSON index on it.
Wow, so having JSON data type in the current release has a requirement of having a Clustered Primary Key – making the existence on this table of the Clustered Columnstore totally impossible. Insert an incredible sad smile here. :( This simply removes the possibility of using JSON in many Data Warehousing scenarios.
But what about the Nonclustered Columnstore Index? Let’s create the table with the requirements to be able to create NCCI:
DROP TABLE IF EXISTS dbo.json_columnstore;
CREATE TABLE dbo.json_columnstore
(
id INT PRIMARY KEY CLUSTERED,
content JSON
);
Now, let’s create a Nonclustered Columnstore Index on the table by including only non-JSON columns
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_json_columnstore on dbo.json_columnstore (id);
This worked fine, so let’s delete the NCCI and recreate it by including the JSON data type column:
DROP INDEX NCCI_json_columnstore on dbo.json_columnstore; CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_json_columnstore on dbo.json_columnstore (id, content);
Now, this results in the following error message:
Msg 35343, Level 16, State 1, Line 11 The statement failed. Column 'content' has a data type that cannot participate in a columnstore index.
Nonclustered Columnstore Indexes are compatible with the new data type on SQL Server. I am not having the biggest shock because remembering the fact that XML data type is not compatible with the Nonclustered Indexes, but this makes JSON data type literally incompatible with Columnstore Indexes.
The only last possibility are the In-Memory tables, which I do not expect to be supporting any new data types:
CREATE TABLE dbo.json_columnstore
(
id INT PRIMARY KEY CLUSTERED,
content JSON,
) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA);
The execution of the above script results in the following error message, as one would expect from the experience of working with the Hekaton:
Msg 12317, Level 16, State 68, Line 22 Clustered indexes, which are the default for primary keys, are not supported with memory optimized tables. Specify a NONCLUSTERED index instead.
Disappointing. I have expected that JSON data type at very least would be compatible with the Clustered Columnstore Indexes, just like XML data type, but I guess that it was not considered a priority for the rushed “Preview” release.
JSON index
I guess that after the fact that the underlying JSON data type is not compatible with the Columnstore Indexes, it makes not much sense of testing JSON Index compatibility with the Columnstore Indexes, but to make sure I have run the test anyway, trying to have Nonclustered Columnstore Indexes anyway:
DROP TABLE IF EXISTS dbo.json_columnstore;
CREATE TABLE dbo.json_columnstore
(
id INT PRIMARY KEY CLUSTERED,
content JSON
);
CREATE JSON INDEX JSIX_json_columnstore
ON json_columnstore (content);
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_json_columnstore on dbo.json_columnstore (id, content);
The result is the same as with the JSON data type – the error message is very much the same:
Msg 35343, Level 16, State 1, Line 13 The statement failed. Column 'content' has a data type that cannot participate in a columnstore index.
The good thing is that the creation of the Nonclustered Columnstore Indexes that do not include the JSON column is supported on the SQL Server 2025 RTM:
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_json_columnstore on dbo.json_columnstore (id);
This gives me that hope that once the initial requirements are eventually relaxed (given of course that JSON is made into GA and that it becomes a success), the amount of work needed to support Columnstore Indexes together with the JSON indexes is not “Mission Impossible”. Hopefully.
Batch Mode
I won’t be testing Batch Execution Mode on Columnstore Indexes with the JSON data type or JSON Index because they are not compatible, but what can be tested is the capability of getting Batch Mode on the Rowstore (assuming that we are treating JSON data type as a Rowstore). For that Purpose I have recreated the test table and added 500 thousands rows with JSON data into it:
DROP TABLE IF EXISTS dbo.json_columnstore;
CREATE TABLE dbo.json_columnstore
(
id INT PRIMARY KEY CLUSTERED,
content JSON,
);
INSERT INTO dbo.json_columnstore WITH(TABLOCK) (id, content)
SELECT TOP (5000000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)),
'{"Price":2024.9940,"Quantity":1}'
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
For the test, let’s run a simple aggregation query against the loaded data:
SELECT sum(cast (id as BIGINT)) as MaxId,
SUM(CAST(JSON_VALUE(content, '$.Quantity') as INT)) AS TotalQuantity
FROM dbo.json_columnstore;
The query execution results in the following execution plan:
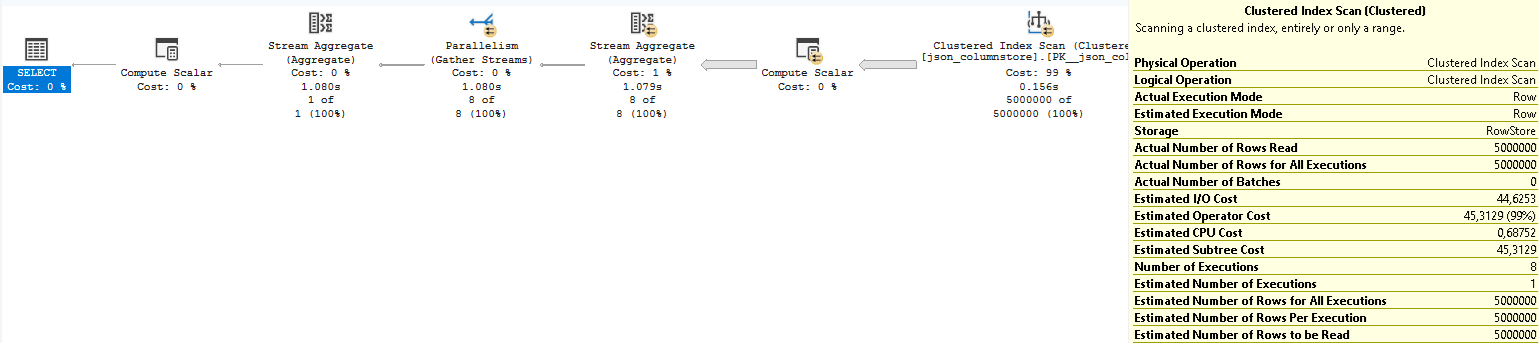
The above plan contains no references to the Batch Execution Mode, which is again, disappointing.
To prove a point, if you run a simpler aggregation query which does not contain references to the JSON data type, it will easily get processed with the Batch Execution Mode:
SELECT sum(cast (id as BIGINT)) as MaxId FROM dbo.json_columnstore;
I think the lack of the Batch Execution Mode itself is not a killer for the JSON data type feature, but I believe it will need to be added in the future releases.
Now, let’s create a JSON Index on our test table, and rerun our aggregation query for the test query:
CREATE JSON INDEX JSIX_json_columnstore
ON json_columnstore (content)
FOR ('$.PRICE', '$.Quantity')
WITH (DATA_COMPRESSION = PAGE);
Because Query Optimizer seems to be ignoring the JSON Index for aggregation operations, after several failed attempts I had to force the index usage by the means of the hint:
SELECT SUM(CAST(JSON_VALUE(content, '$.Quantity') as INT)) AS TotalQuantity
FROM dbo.json_columnstore WITH(INDEX(JSIX_json_columnstore))
WHERE JSON_VALUE(content, '$.Quantity') = 1;

After seeing no support for Batch Mode when aggregating JSON data type content, I am not surprised by seeing no support for Batch Execution Mode on JSON Indexes in SQL Server 2025 RTM. Again, this is by no measure a feature killer for the JSON Indexes themselves, but it is quite disappointing for those who are going to acquire the product right away.
Final Thoughts
The JSON data type itself is of course not the most suitable one for the analytics and for the Columnstore Indexes, but the lack of its compatibility with Columnstore Indexes or compatibility with the Batch Execution Mode in SQL Server 2025 is quite disappointing.
| Feature | Clustered Columnstore | Nonclustered Columnstore | In-Memory Columnstore | Ordered (CCI & NCCI) | Batch Mode on Columnstore | Batch on Rowstore |
|---|---|---|---|---|---|---|
| JSON_datatype | – | – | – | – | – | – |
| JSON_Index | – | – | – | – | – | – |
This is one of the cases where we are very much back to square 1 – do we need first to see JSON data type and index successes or do they need to have a full feature support. A kind of Chicken or the Egg problem. Since the MVP (Minimal Viable Product) delivery so far has been below disappointing (“Preview”-level of unfished code checked into the RTM product) and because the first impression will stay online in the form of the posts/videos and human impressions for a long time, I am not entirely sure if the strategy chosen for the JSON is going to work. I do hope it will. And I am skeptical of the future, based on the current state.
As of today, I am recommending NOT to use Columnstore Indexes with JSON in SQL Server 2025 release – especially because right now it is not possible, and IF it will be possible, then consider yourself, your company and your customers to be a non-paid testers :)
to be continued …