Continuation from the previous 26 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
Let us consider a situation when we are using so-called Trickle Loads into Delta-Stores of a Clustered Columnstore Index.
Naturally, this is a not very much desired situation, since the best practice would be loading data using Batch Execution Mode directly into Compressed Segments, using Bulk Insert API – this is very clear.
In the real life though we might not be able to perform this task as it pleases us, because sometimes we need to update(load) new information on hourly or 30-min basis and there is no chance of getting the magical 100.000 rows which would allow us to use Bulk Insert API.
I decided to see exactly what happens if we create an extremely simple table with just 1 column and consequently load over 67 Million rows to create enough Row Groups to be analyzed.
The structure:
create table dbo.BigDataTest( id int not null ); create clustered columnstore index PK_BigDataTest on dbo.BigDatatest;
The data was loaded in 2 batches, executed in sequence:
1. This one loads a full segment
declare @i as int; set @i = 1; begin tran while @i <= 1048576 begin insert into dbo.BigDataTest values (@i); set @i = @i + 1; end; commit;
2. In this batch we are going over the existing data and recursively inserting it by adding max value. The cycle is repeated 6 times in order to reach 67 Million Rows.
declare @i as int; declare @max as int; set @i = 1; while @i <= 6 begin select @max = isnull(max(id),0) from dbo.BigDataTest; insert into dbo.BigDataTest select id + @max from dbo.BigDataTest; set @i = @i + 1; end;
While the process is running I was measuring the process progress by executing the following script which would give me back the number of different Row Groups grouped by their status:
select state, state_description, count(*) as 'RowGroup Count'
from sys.column_store_row_groups
where object_id = object_id('BiGDataTest')
group by state, state_description
order by state;
While the first batch takes around 1 minute on my VM to execute (2 cores), the second batch which inserts over 66 Million rows takes a good 5:54 minutes.
Are we done ? Are we ready to rock and roll with the amazing performance of the Columnstore Indexes ?
Not really.
Check out my results right near the finish of the second batch:
select state, state_description, count(*) as 'RowGroup Count'
from sys.column_store_row_groups
where object_id = object_id('BiGDataTest')
group by state, state_description
order by state;
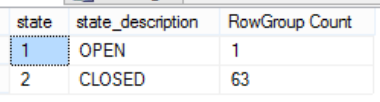 Yes, indeed I single compressed Row Group, with all the others being the others being still Delta-Stores.
Yes, indeed I single compressed Row Group, with all the others being the others being still Delta-Stores.
This means that almost all data that we just have loaded resides in our Heap B-Tree structures and even though our queries can still run in Batch Mode, there will be no significant IO performance improvements (excluding the Segment Elimination process).
Tuple Mover
Tuple Mover is a process which runs automatically every 5 min and it looks for the closed Delta-Stores in order to convert them into Segments.
As it was written by Remus Rusanu in his amazing article "SQL Server Clustered Columnstore Tuple Mover" the default running process is described as 1 serial execution, than sleeping for around 15 seconds and then repeating until there are closed Delta-Stores existing.
I decided to measure the performance of the default Tuple Mover on my simple table, and so I invoke the following script, which simply measured the amount of Row Groups and their status 2 times in a matter of a minute:
select state, state_description, count(*) as 'RowGroup Count'
from sys.column_store_row_groups
where object_id = object_id('BiGDataTest')
group by state, state_description
order by state;
waitfor delay '00:01:00';
select state, state_description, count(*) as 'RowGroup Count'
from sys.column_store_row_groups
where object_id = object_id('BiGDataTest')
group by state, state_description
order by state;
Here are my results:
 You can clearly see that only 4 closed Delta-Stores were compressed, as expected. Our table is very narrow and so the compression should be almost instant and so 15 seconds waiting period is running as expected.
You can clearly see that only 4 closed Delta-Stores were compressed, as expected. Our table is very narrow and so the compression should be almost instant and so 15 seconds waiting period is running as expected.
A simple math tells us that if we let Tuple Mover run on its own, than it will take a good 15 minutes in order to compress our table. Remember, this is a not a real world table, this is a primitive table which just have gotten 67 Million Rows.
A real table might take much more time, which does not look to be anywhere near reasonable numbers.
Solution
Our solution for this case would be to invoke Tuple Mover manually, by executing the Reorganize operation on our Clustered Columnstore Index:
alter index PK_BigDataTest on dbo.BigDataTest reorganize;
or as an alternative we can always run a rebuild
alter index PK_BigDataTest on dbo.BigDataTest Rebuild;
plus it can be done on the partition level, which permit us s better control of the impact on the server. For an increased control we can & in a number of cases must use Resource Governor in order to control the impact of our operations, which are definitely going to impact CPU & IO of the Server quite heavily.
From the other side we are naturally assuring that our Tuple Mover won't take too much time compressing all those Delta-Stores.
Did you know, that you can have 2 executing Tuple Movers at the same time - automatic and manual ones, but should you try to invoke Tuple Mover again from a different transaction, you will get the following error message:

I would extremely recommend to analyse the way you are loading data into your Clustered Columnstore Table and check if you might be needing to invoke Tuple Mover manually.
to be continued with Clustered Columnstore Indexes – part 28 ("Update vs Delete + Insert")