Continuation from the previous 24 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
I decided to take a simple OLTP table, make it bigger and to tear it apart with Clustered Columnstore & so this blog post is about this experiment.
I picked up the always lovely AdventureWorks in its 2012 version and to decided to apply the awesome MakeBigAdventure script, created by Adam Machanic.
I kicked off by executing the following script which will create 31 Million, 62 Million & 125 million rows respectively. Why? Because I have seen enough cases when OLTP tables would grow beyond anything reasonable, even while using Enterprise Edition of SQL Server and not knowing what Partitioning or Compression is.
Notice that varying the part “AND a.number BETWEEN 1 AND 50” by changing the last number to 100 and to 200 I have achieved the respectful growth for the 2nd & 3rd test cases.
/* * Taken from http://sqlblog.com/blogs/adam_machanic/archive/2011/10/17/thinking-big-adventure.aspx, written by Adam Machanic */ USE AdventureWorks2012 GO SELECT p.ProductID + (a.number * 1000) AS ProductID, p.Name + CONVERT(VARCHAR, (a.number * 1000)) AS Name, p.ProductNumber + '-' + CONVERT(VARCHAR, (a.number * 1000)) AS ProductNumber, p.MakeFlag, p.FinishedGoodsFlag, p.Color, p.SafetyStockLevel, p.ReorderPoint, p.StandardCost, p.ListPrice, p.Size, p.SizeUnitMeasureCode, p.WeightUnitMeasureCode, p.Weight, p.DaysToManufacture, p.ProductLine, p.Class, p.Style, p.ProductSubcategoryID, p.ProductModelID, p.SellStartDate, p.SellEndDate, p.DiscontinuedDate INTO bigProduct FROM Production.Product AS p CROSS JOIN master..spt_values AS a WHERE a.type = 'p' AND a.number BETWEEN 1 AND 50 GO
Now create a Clustered Columnstore Index on this bigProduct table, it will help you inserting the bigTransaction table which will generate the 30+ Million Rows:
Create Clustered Columnstore Index PK_bigProduct on dbo.bigProduct;
Warning: the next script will run for some significant amount of time, so make sure you have enough space (I gave it 7GB), and make sure that your Transaction log is big enough to support some serious storage. Even though my test VM has just 2 cores, I have a reasonable SSD which is a kind of important when working with those numbers of rows.
SELECT ROW_NUMBER() OVER ( ORDER BY x.TransactionDate, (SELECT NEWID()) ) AS TransactionID, p1.ProductID, x.TransactionDate, x.Quantity, CONVERT(MONEY, p1.ListPrice * x.Quantity * RAND(CHECKSUM(NEWID())) * 2) AS ActualCost INTO bigTransactionHistory FROM ( SELECT p.ProductID, p.ListPrice, CASE WHEN p.productid % 26 = 0 THEN 26 WHEN p.productid % 25 = 0 THEN 25 WHEN p.productid % 24 = 0 THEN 24 WHEN p.productid % 23 = 0 THEN 23 WHEN p.productid % 22 = 0 THEN 22 WHEN p.productid % 21 = 0 THEN 21 WHEN p.productid % 20 = 0 THEN 20 WHEN p.productid % 19 = 0 THEN 19 WHEN p.productid % 18 = 0 THEN 18 WHEN p.productid % 17 = 0 THEN 17 WHEN p.productid % 16 = 0 THEN 16 WHEN p.productid % 15 = 0 THEN 15 WHEN p.productid % 14 = 0 THEN 14 WHEN p.productid % 13 = 0 THEN 13 WHEN p.productid % 12 = 0 THEN 12 WHEN p.productid % 11 = 0 THEN 11 WHEN p.productid % 10 = 0 THEN 10 WHEN p.productid % 9 = 0 THEN 9 WHEN p.productid % 8 = 0 THEN 8 WHEN p.productid % 7 = 0 THEN 7 WHEN p.productid % 6 = 0 THEN 6 WHEN p.productid % 5 = 0 THEN 5 WHEN p.productid % 4 = 0 THEN 4 WHEN p.productid % 3 = 0 THEN 3 WHEN p.productid % 2 = 0 THEN 2 ELSE 1 END AS ProductGroup FROM bigproduct p ) AS p1 CROSS APPLY ( SELECT transactionDate, CONVERT(INT, (RAND(CHECKSUM(NEWID())) * 100) + 1) AS Quantity FROM ( SELECT DATEADD(dd, number, '20050101') AS transactionDate, NTILE(p1.ProductGroup) OVER ( ORDER BY number ) AS groupRange FROM master..spt_values WHERE type = 'p' ) AS z WHERE z.groupRange % 2 = 1 ) AS x;
And now let’s create a Clustered Columnstore Index on our table:
Create Clustered Columnstore Index pk_bigTransactionHistory on dbo.bigTransactionHistory
What I love about this table is that it does have a structure and the type of data that is typical to found in a lot of applications.
For better understanding of the type of table we are dealing with, execute the following query which will bring the information about counts of distinct values stored in our OLTP-style table:
SELECT count(*) as 'Total rows'
,count(distinct([ProductID])) as 'Distinct ProductId'
,count(distinct([TransactionDate])) as 'Distinct [TransactionDate]'
,count(distinct([Quantity])) as 'Distinct [Quantity]'
,count(distinct([ActualCost])) as 'Distinct ActualCost'
FROM [dbo].[bigTransactionHistory]
![]()
You can clearly see that our [Quantity] and [TransactionDate] are quite sparse, which is perfectly normal, while ActualCost is extremely diverse which is probably means almost no compression can be applied on the top of it.
So Let’s see how good our compression actually was:
select OBJECT_NAME(rg.object_id) as TableName, count(*) as RowGroupsCount, cast(sum(size_in_bytes) / 1024.0 / 1024 as Decimal(9,2)) as SizeInMb
from sys.column_store_row_groups rg
where object_id = object_id('[dbo].[bigTransactionHistory]')
group by OBJECT_NAME(rg.object_id)
![]()
We have 312 MB spent on 32 Million Rows. Interesting number. :) Without looking at the data I would expect a little bit more, but let us carry on.
The number of Row Groups is perfectly fine, as far as I am concerned.
I decided to make a reality check and created a page-compressed copy of the table. I copied all the data into it and here is the result of the space occupied by it:
![]()
Yes indeed – 462 MB (the value on the screenshot divided by 1024), it is a good 1/3 bigger than the Columnstore compressed table.
This means that from the storage point of view even if you compare by the occupied size, Columnstore compression wins easily, but if you start thinking about Columnstore Locking & Blocking – I guess that you will not want to use it on a regular transaction modifying system. :)
Next step would be to check the situation with dictionaries, by using the following query:
SELECT count(csd.column_id) as DictionariesCount,
cast( SUM(csd.on_disk_size)/(1024.0*1024.0) as Decimal(9,3)) as on_disk_size_MB
FROM sys.indexes AS i
JOIN sys.partitions AS p
ON i.object_id = p.object_id
JOIN sys.column_store_dictionaries AS csd
ON csd.hobt_id = p.hobt_id
where i.object_id = object_id('[dbo].[bigTransactionHistory32]')
AND i.type_desc = 'CLUSTERED COLUMNSTORE'
AND csd.dictionary_id = 0
group by OBJECT_NAME(i.object_id);
We have got here just 3 dictionaries which are extremely small – 0.111 MB:
![]()
So lets take a more detailed look at those dictionaries:
select object_name(object_id), dict.* from sys.column_store_dictionaries dict join sys.partitions part on dict.hobt_id = part.hobt_id

Very clear picture here: the columns 2 to 4 are turned into dictionaries, while 1 is identity and is not compatible with dictionaries at the current version, and the last 5th column [ActualCost] is having way too many distinct values.
Results
Now let us compare this all data with even bigger tables – I executed the same queries for the 65 Million & 121 Million Rows respectively as I described the beginning of the post, and so here are my results:
Time
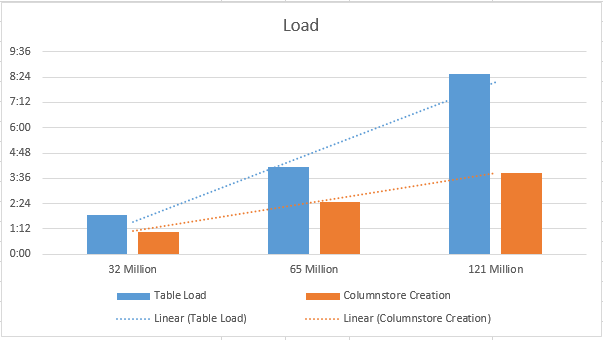
I have measured the time to load the data into a HEAP plus creating a Clustered Columnstore Index on it, and for me it looked like if using this tactic, one should be aware that the Columnstore Indexes creation seems to be less of a problem than the data load itself. You can clearly see from the trend line that the times spent on creation are growing quite proportionally, while loading more data directly into HEAP only my test VM means putting more stress on the system.
Row Groups & Sizes

Very balanced picture here, with the only exception of 65 Million rows case, where I was lucky to get just 61 Row Groups and the coefficient of an average size per row group was 10.07, 9.67, 10.47 for 32/65/121 Million rows respectively.
Dictionaries
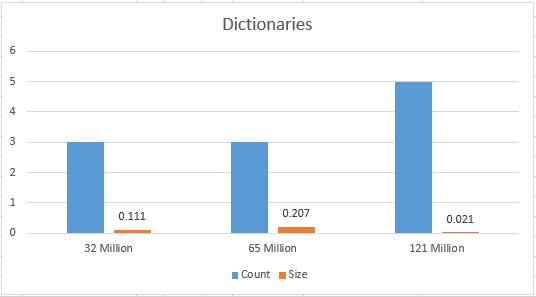
The only exciting thing about the dictionaries is that for the bigger table, there are more dictionaries (local), but the total size seems to be unaffected by the number of rows, which makes sense -> the content of the tables is not that distinct.
Heap & Clustered Columnstore vs Clustered Columnstore Load
At this point I decided to compare those times with loading data into a table with a Clustered Columnstore Index, but I will spare you all the t-sql statements and so here are the results:
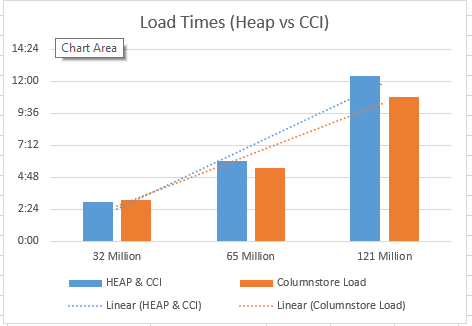
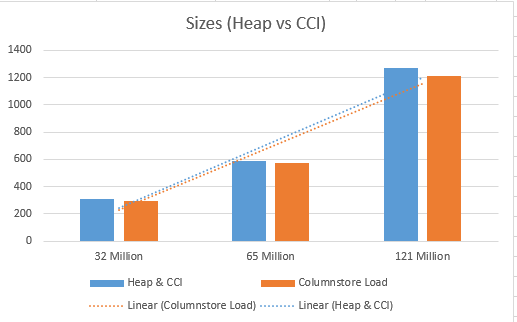
Loading into Clustered Columnstore tables directly is definitely Faster, and it makes the tables look Smaller (also 1 Row Group less compared to the HEAP & CCI loading method), so the whole situation is much Better and the database performance is much Stronger. :)
to be continued with Clustered Columnstore Indexes – Part 26: Backup & Restore
Hi Niko –
I greatly enjoy your very in-depth series on columnstore indexes.
For this particular article, my testing mostly produced opposite results – I am getting much faster performance by 1)Inserting into a heap and 2) creating the CCI.
Now, our SQL Server has 20 cores and we are bulk loading in parallel threads using SSIS. I am wondering if the way you are loading the table is happening in parallel? What are the specs of your Sql Server?
Hi Xian,
I probably need to expand this article with more details and explanations.
It was a simple test VM with an SSD and just 4 or 8 cores, I am not sure about it right now.
The performance of each test has a lot to do with with a transaction log – for Clustered Columnstore the log records are smaller than for the traditional RowStore, but should you be able to do a minimally logged transaction, this is where a RowStore definitely wins against Columnstore at the moment, since Columnstore does not support minimal logging. (http://www.nikoport.com/2014/11/19/clustered-columnstore-indexes-part-43-transaction-log-basics/).