This is the the 2nd blog post in the series about Azure Arc enabled Data Services.
The initial post can be found at Azure Arc for Data Services, part 1 – Intro and the whole collection can be found at Azure Arc enabled Data Services.
In the first post I have laid out the idea & the basic principles behind the Azure Arc for Data Services, and in this post we shall get a step closer into looking into the Requirements and available tools for this solution, which is still in preview as of January of 2020.
My experience is based on a Mac OS X & MacBook Pro that I am using as a working machine, and the mileage might vary, especially since Microsoft might just go and change anything in the requirements or tools without any fanfare.
The Requirements
The basic requirement would be a Kubernetes Cluster with at least 4 CPU Cores and 16 GB RAM by my estimations (and I do not see anything official on this on the documentation).
The profiles of the K8s Cluster that are supported for Azure Arc for Data Services are rather impressive:
– AKS (Azure Kubernetes Service) with either premium or standard storage
– Azure AKS HCI (Stack)
– AKE
– EKS (AWS Elastic Kubernetes Service)
– Kubeadm
– Openshift
– Azure Openshift.
I will not dive into how you should set up the network or how it should be protected, since this is not my cup of the tea and I ask good respective specialists in those areas with the help.
The part that I want to make sure you understand is that there several essential connections that your cluster will need to make in order for you to get all the essential bits, even though I expect that for the unconnected mode in the future there will be a package to download.
The computer/server which you will use to connect to the Azure will have to have access to some sites, such as MCR (Microsoft Container Registry), Azure Portal Login and Management, Azure Resource Manager APIs and the Azure monitor APIs if you want to have your metrics uploaded to Azure. Hence you will have to be able to access at least some of the following URLs:
mcr.microsoft.com
login.microsoftonline.com
management.azure.com
*.ods.opinsights.azure.com
*.oms.opinsights.azure.com
*.monitoring.azure.com
and even more details on this topic can be found at Connectivity modes and requirements.
To setup the Azure Arc Data Services, you will need to accept all terms and conditions, and have a good access to Azure Portal or as an alternative you will need to deal with the customisations right from the beginning (and untecipating the further blog posts – if you are running a plain simple K8s cluster in your own environment
Other important requirements are:
– Kubectl: you will have to control and check the status of your Kubernetes Cluster, right ?
– Azure CLI (az): to be able to run the commands for the Azure Arc Data Controller creation
– Azure Data CLI (azdata): the essential because it will do all the heavy lifting and actual commands.
– Azure Data Studio: for running the Yupiuter Notebook and for working with Azure SQL Managed Instance and Azure PostgreSQL Hyperscale
– Azure Arc Extension for Azure Data Studio: if you want to have a better visual control for the nodes of Azure SQL Managed Instance
– PostgreSQL extension in Azure Data Studio: if you want to have a better visual control for the nodes of Azure PostgreSQL Hyperscale
The whole list that might get updated can be found at the Install client tools for deploying and managing Azure Arc enabled data services.
The feeling of setting up and using the Azure Arc for Data Services at the moment will give you the idea of a huge connection with SQL Server Big Data Clusters, since a lot of commands are extremely similar, starting with the fact that they are both using Kubernetes as an underlying layer.
Azure Arc Data Controller
 Setting up Azure Arc for Data Services can be pretty different experience, depending on the underlying K8s cluster and its hardware, because as I always say “the quality of any software can be measured by the quality of the error messages it delivers“.
Setting up Azure Arc for Data Services can be pretty different experience, depending on the underlying K8s cluster and its hardware, because as I always say “the quality of any software can be measured by the quality of the error messages it delivers“.
Expect 1.5 – 2.0 CPU Cores to be spent on the internal K8s & Azure Data Arc management, and at least 10 GB of RAM for the same purpose. This means if you have like 16 GB of RAM and 4 CPU Cores in your cluster, you mostly like see the finish line and you might cross it, but you won’t be able to enjoy the result.
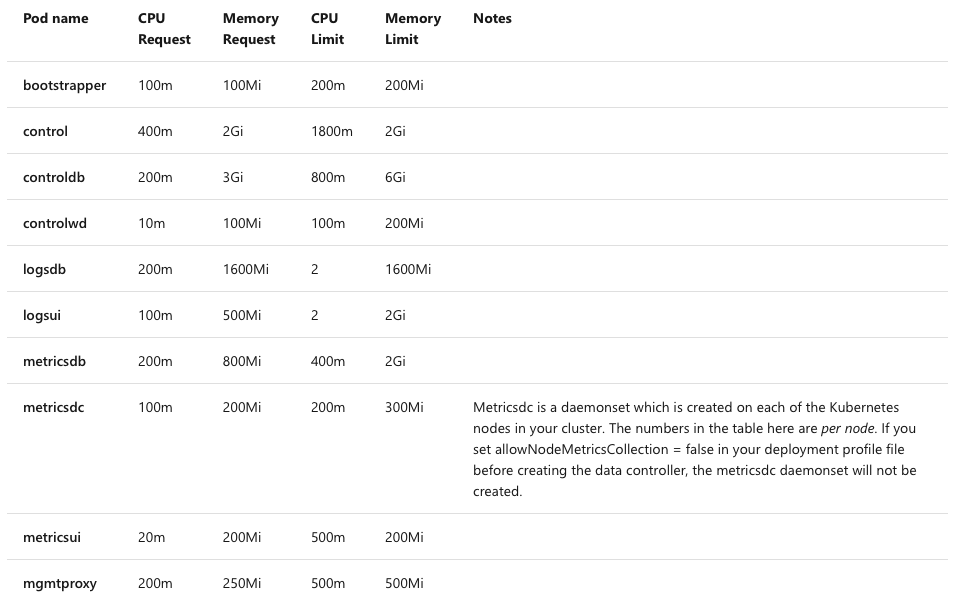
When creating an Azure Arc for Data Services you will notice that besides the expected services such as bootstrapper, there will be a number of pods running, such as:
– Collectd – a Unix Daemon that collets the system and application performance metrics. The information collected can be stored locally or forwarded to different location/processor.
– Fluentbit for processing and forwarding the log records. Microsoft has already released a Azure Blob output connector in collaboration with Fluentbit, which I think from many points of view is a wonderful collaboration – business-wise and consumer-wise, if you are using Azure.
– InfluxDB Telegraf – agent for collecting the logs.
– ElasticSearch for all the logs, there is almost always elastic search :)
– InfluxDB – The platform for building and operating time series applications.
– Telegraf – the server agent to help you collect metrics from your stacks, sensors and systems.
– Controller – someone or something has got to control the stuff, right ?
The installation will also result in the creation of the respective pods fo the Kibana and Grafana, which then can be used to monitor the Azure Arc for Data Services.
Each of those services will provide not only the interface for communications, but a true dashboard experience as one would expect from a standalone installation.
I love the fact that those are real installations that are useful right away instead of extra hustle that I would expect from a new service.
For Azure SQL Managed Instance the absolute minimum requirements are:
– 1 CPU Core
– 2 GB RAM
where each instance of it, a respective 3 pods with be created with Fluentbit (log processor that will take extra 100 MB Ram and 0.1 CPU cure), arc-sqlmi (the instance) and collectd (the service that collects the metrics to be reported back to Azure)
For Azure PostgreSQL Hyperscale they requirements are a bit lower:
– 1 CPU Core
– 256 MB RAM
where each instance of it, a respective 3 pods with be created with Fluentbit (log processor that will take extra 100 MB Ram and 0.1 CPU cure), Postgres (the instance) and Telegraf (see above)
Storage
I won’t write you how much time we (me and a colleague of mine, Renan Ribeiro) have spent, trying to figure out some of the troubles with the storage, I will simply recommend you to follow the guidelines BY THE BOOK. EACH LINE. For your own sake.
Take a good care of the storage classes within your K8s cluster and provision enough required space with respective permissions, if so needed.
Also, even though this is trivial, but never is too much to remind, that “You must use a remote, shared storage class in order to ensure data durability and so that if a pod or node dies that when the pod is brought back up it can connect again to the persistent volume.”
Be aware that there are FIXED requirements for the persistent volumes for each of the pods, and the more pods you are creating (and you are creating a good number right away with the controller installation) – the more PVs (persistent volumes) you will have.
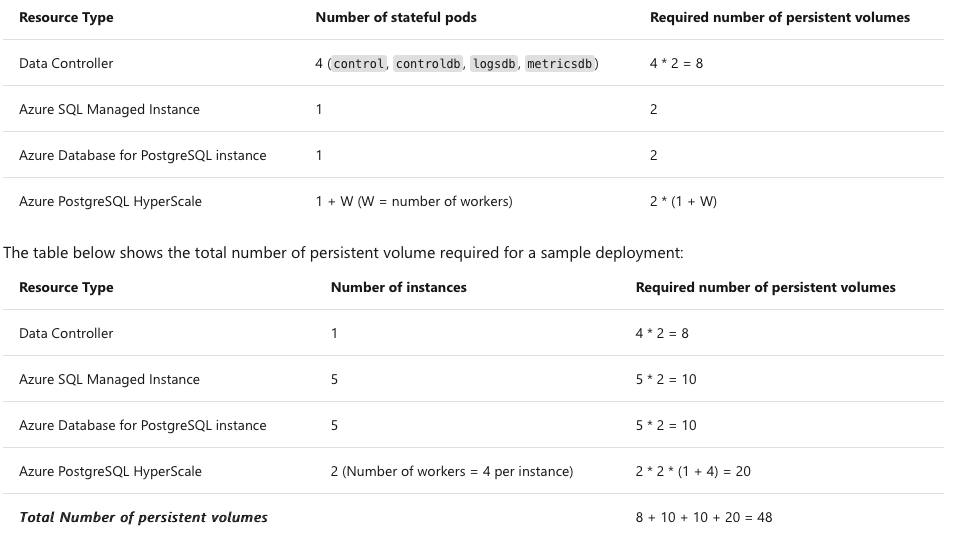
Without trying to impress you, I will rather provide here an image of the respective calculations and a practical example right from the documentation:
Running Requirements
In addition to the cores and memory you request for each database instance, you should add 0.25 of CPU core and 250 MB of RAM for the agent containers.
 Here is a screenshot of the calculations that need to be done in order to make the execution smooth and please take them especially serious as with any preview service, there are a lot of bugs to be corrected and from my personal experience, if you are not proficient with K8s commands – good luck!
Here is a screenshot of the calculations that need to be done in order to make the execution smooth and please take them especially serious as with any preview service, there are a lot of bugs to be corrected and from my personal experience, if you are not proficient with K8s commands – good luck!
Notice also in the Sizing Guide the recommendation of having around 25% of available capacity free, to allow K8s schedule and create pods and scale the respectful resources. While in real life it is most probably to be an exaggeration, since business has got to make money and not to keep the free CPU Cores & RAM taking rest, it is more of a sign of not “over-virtualize”.
In the next blog post I intend to take a closer look at the setup process of the Azure Arc for Data Services.
to be continued with Azure Arc enabled Data Services, part 3 – Configuring on a plain vanila Kubernetes