Continuation from the previous 127 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
First of all and before everything else, I would like to extend my gratitude to Xiaoyu Li (Microsoft PM) for taking her time and exchanging long emails and doing a call with me to clear up the doubts. I hate it when the results are wrong and given this feature is in a preview, my experience has been far from perfect. Xiaoyu has helped me understanding the reasons behind the wrong results and without her this blog would have had a different outcome.
We all know the importance of information sorting and even besides of how we want/need to consume the information, the importance on the analysis performance is not easy to underestimate.
Regarding the Columnstore Indexes, in the past I have dedicated a good amount of attention to this topic with the articles on the matter with
Columnstore Indexes – part 45 (“Multi-Dimensional Clustering”), Columnstore Indexes – part 57 (“Segment Alignment Maintenance”) and Columnstore Indexes – part 110 (“The best column for sorting Columnstore Index on”) between others.
The potential & practical benefits of the ordered Clustered Columnstore Indexes are huge – processing less information in memory and on disk is something that every single query against major tables with multiple TB of space occupied will benefit from. Scanning Disk especially is not cheap until we get the persistent-memory available in abundant quantities.
This year (2019), Microsoft has announced the public preview of the ordered Clustered Columnstore Indexes on Azure SQL Data Warehouse – and I think this is absolutely exiting news and this is the blog post where I shall take this feature for a “test drive”.
The Syntax and the functionality
The implemented syntax is rather plain and understandable:
CREATE CLUSTERED COLUMNSTORE INDEX index_name
ON { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ORDER (column [,...n] ) ]
[;]
After creating (or dropping and recreating a Clustered Columnstore Index we can specify the reserved word ORDER and then one or !!!MULTIPLE!!! columns. This looks like an extremely promising feature!
On Azure SQL Data Warehouse one can of course define table as a Columnstore and with that specification it is also possible to define an ORDER option with one or multiple columns.
For the syntax and basic functionality testing purposes on Azure SQL Data Warehouse, let us then create a table with a Clustered Columnstore Index, load some data and see if by recreating an Ordered Clustered Columnstore Index we can achieve some improvements.
I will create a basic HEAP table, put some 100 Million Rows into it and then add add a Clustered Columnstore:
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL
)WITH (HEAP);
SET NOCOUNT ON
INSERT INTO dbo.SampleDataTable
SELECT t.RN
FROM
(
SELECT TOP (500 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
CROSS JOIN sys.objects t6
CROSS JOIN sys.objects t7
CROSS JOIN sys.objects t8
) t
OPTION (MAXDOP 1);
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable;
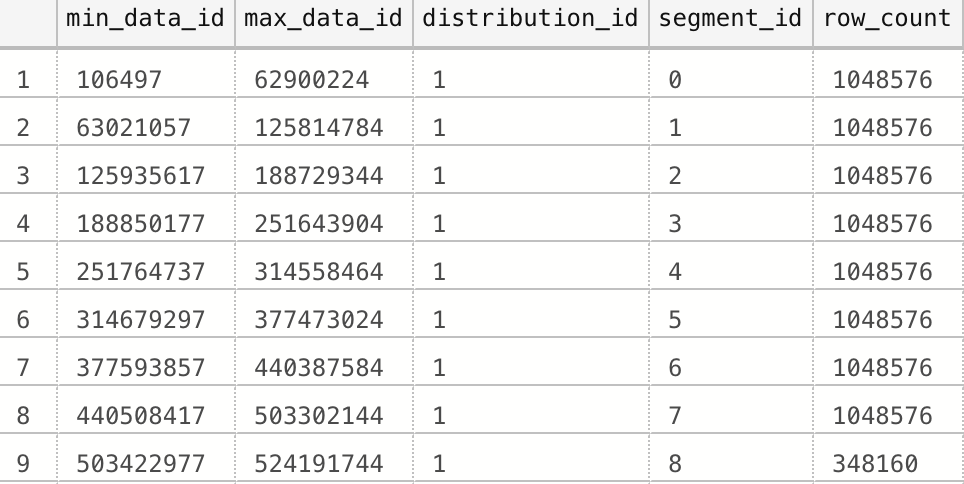
For checking on the status of the segments, we shall use an almost equivalent to the original, that is called sys.pdw_nodes_column_store_segments, while ordering the results on the minimum and maximum values:
SELECT min_data_id, max_data_id, distribution_id, segment_id, row_count
FROM sys.pdw_nodes_column_store_segments seg
ORDER BY min_data_id, max_data_id;
Well, take a look at the results:
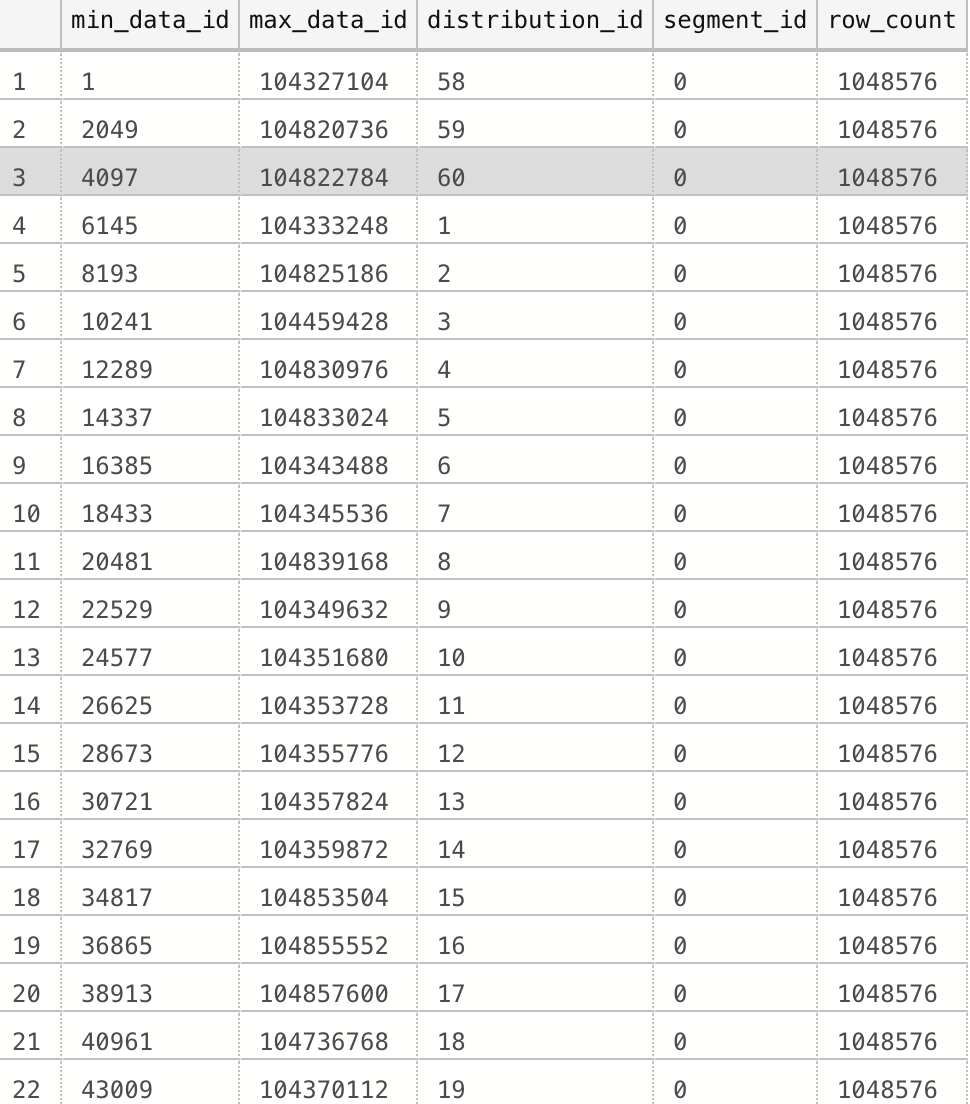 Did you notice any order overlapping ? I did… It looks like a chaos, even though we load data in the ordered fashion, making sure it lands into our table correctly, but as on Azure SQL Database, Azure SQL Managed Instance or Sql Server, creation or rebuild of the Columnstore Index will cause Vertipaq engine to sort data in the fashion to guarantee the most impactful compression while keeping an extremely effective deflation (decompression) for users being able to query their data as fast as possible.
Did you notice any order overlapping ? I did… It looks like a chaos, even though we load data in the ordered fashion, making sure it lands into our table correctly, but as on Azure SQL Database, Azure SQL Managed Instance or Sql Server, creation or rebuild of the Columnstore Index will cause Vertipaq engine to sort data in the fashion to guarantee the most impactful compression while keeping an extremely effective deflation (decompression) for users being able to query their data as fast as possible.
Let’s try to force the ordering of the Columnstore Index with the above-mentioned syntax, ordering on our only column C1:
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable ORDER ( C1 ) WITH (DROP_EXISTING = ON);
Now we can check on the ordered results with the same result
SELECT min_data_id, max_data_id, distribution_id, segment_id, row_count
FROM sys.pdw_nodes_column_store_segments seg
ORDER BY min_data_id, max_data_id;
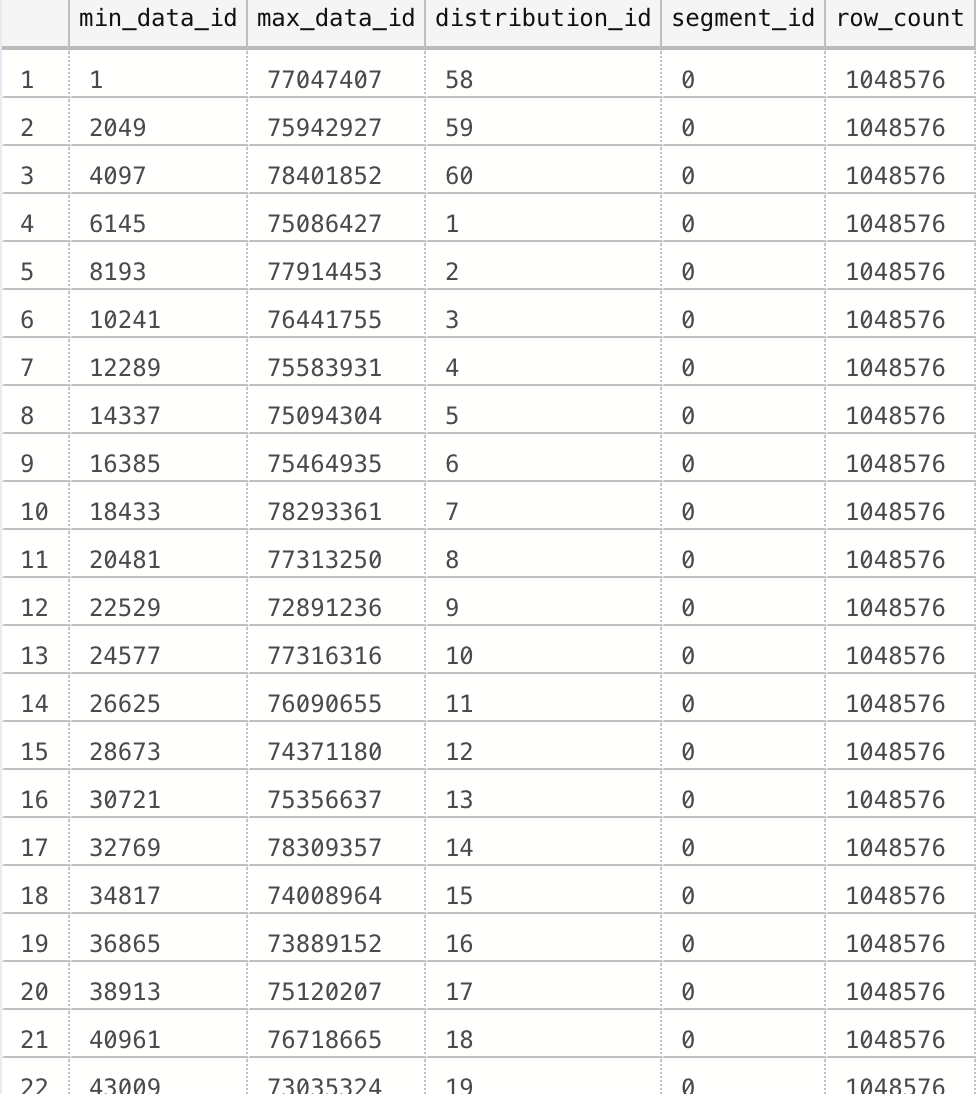 Did you notice any difference ? It looks like we have extremely similar overlapping values between our segments. The thing is (and the huge trick) – the order should take place not within the whole Clustered Columnstore Index or Clustered Columnstore Index Partition for the matter, no! Since at the Azure SQL Data Warehouse we have distributions (and please consult Azure SQL Data Warehouse – Massively parallel processing (MPP) architecture for understanding what it exactly is – the bottom line would be a kind of additional internal sub-partitioning :))
Did you notice any difference ? It looks like we have extremely similar overlapping values between our segments. The thing is (and the huge trick) – the order should take place not within the whole Clustered Columnstore Index or Clustered Columnstore Index Partition for the matter, no! Since at the Azure SQL Data Warehouse we have distributions (and please consult Azure SQL Data Warehouse – Massively parallel processing (MPP) architecture for understanding what it exactly is – the bottom line would be a kind of additional internal sub-partitioning :))
Focusing the data, one can only wonder if the as a matter of a fact there was no major sorting operation, because many segments distributed between those perky 60 distributions.
Let’s reorder the results, this time forcing the order of the results from the segments by the distribution and then the segment_id:
SELECT min_data_id, max_data_id, distribution_id, segment_id, row_count
FROM sys.pdw_nodes_column_store_segments seg
ORDER BY distribution_id, segment_id;
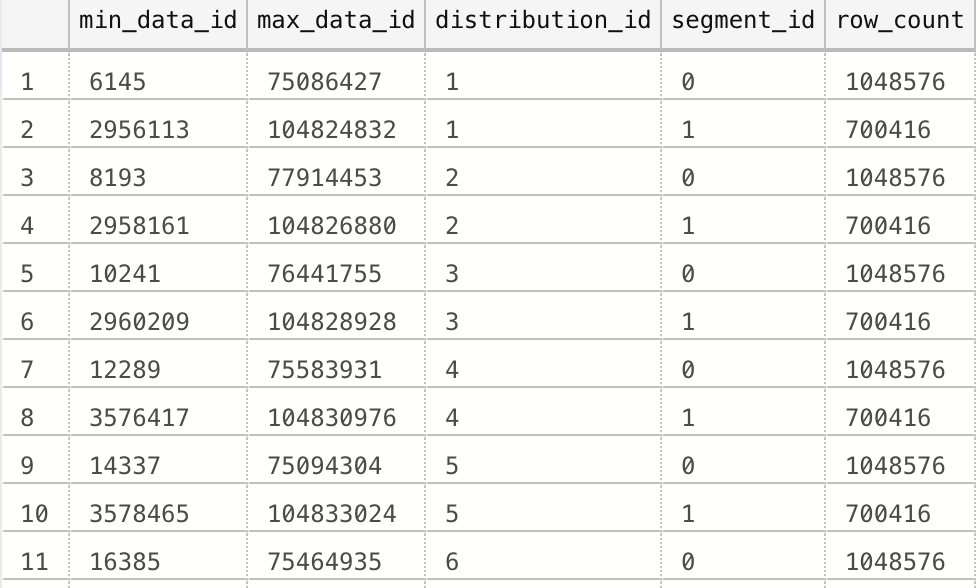 I confess that I can not see a perfect distribution and the values 75.086.427 as maximum for the segment_id = 1 and the minimum 2.956.113 of the segment_id = 2 are clearly not the source of joy I expected to get right away. I was expecting perfect result that we are used to get when ordering the data with the help of Rowstore Index creation and then with the creation of the Clustered Columnstore Index with the hint (DROP_EXISTING = ON).
I confess that I can not see a perfect distribution and the values 75.086.427 as maximum for the segment_id = 1 and the minimum 2.956.113 of the segment_id = 2 are clearly not the source of joy I expected to get right away. I was expecting perfect result that we are used to get when ordering the data with the help of Rowstore Index creation and then with the creation of the Clustered Columnstore Index with the hint (DROP_EXISTING = ON).
One of the early important conclusions to arrive is that sorting does not make a lot of sense if we are playing in the lower hundreds of millions of rows league. We need to pump our game up to at least 500 segments, so that we have at least 8 segments per distribution (60 * 8 = 480 segments, plus some distributions will get the rest 20 segments distributed).
Half a billion Columnstore
Let’s create those 500 segments with 1.048.576 rows each:
DROP TABLE dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL
) WITH (HEAP);
SET NOCOUNT ON
INSERT INTO dbo.SampleDataTable
SELECT t.RN
FROM
(
SELECT TOP (500 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
CROSS JOIN sys.objects t6
CROSS JOIN sys.objects t7
CROSS JOIN sys.objects t8
CROSS JOIN sys.objects t12
CROSS JOIN sys.objects t13
CROSS JOIN sys.objects t14
CROSS JOIN sys.objects t15
CROSS JOIN sys.objects t16
CROSS JOIN sys.objects t17
CROSS JOIN sys.objects t18
) t
OPTION (MAXDOP 1);
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable
ORDER ( C1 )
Now we are able to check results with the very same query against the sys.pdw_nodes_column_store_segments DMV:
SELECT min_data_id, max_data_id, distribution_id, segment_id, row_count
FROM sys.pdw_nodes_column_store_segments seg
ORDER BY distribution_id, segment_id;
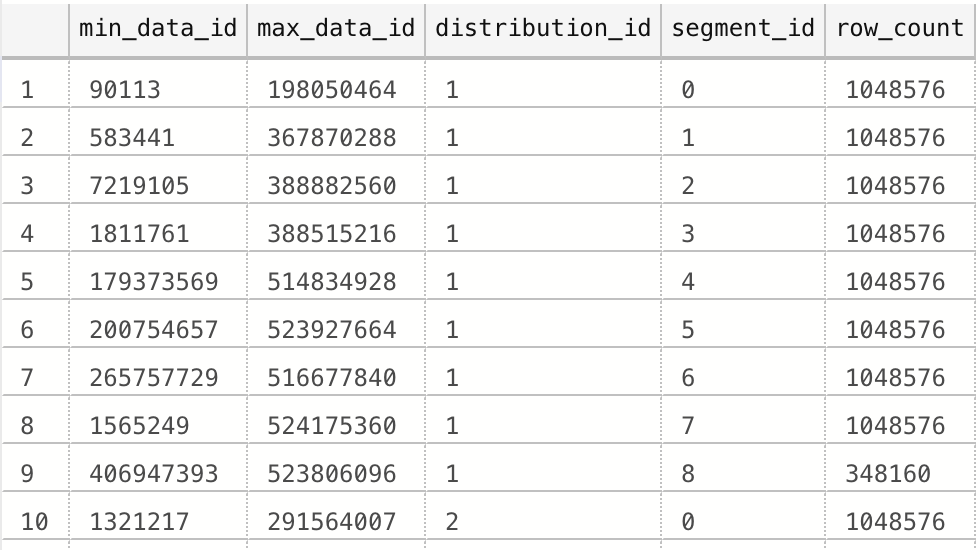 On the left side you can see the exact output I have received for the distribution_id = 1.
On the left side you can see the exact output I have received for the distribution_id = 1.
DOES IT STRIKE YOU LIKE SOMETHING IS WRONG THERE ?
This is how it looks visually:
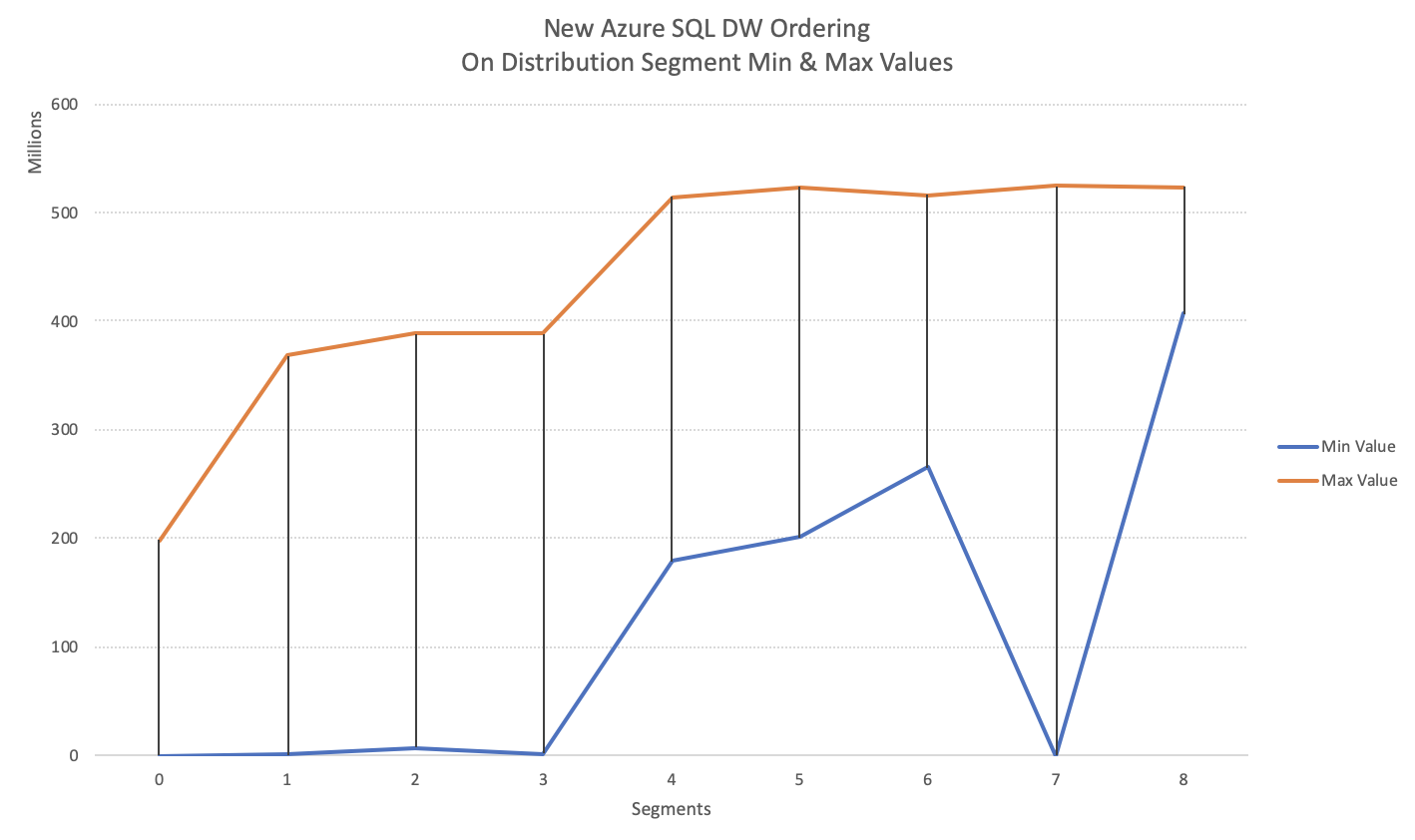
with blue line defining the minimum value, the orange line defining the maximum values and the grey lines between them showing the covered potential distance. The thing is that what I expected was the minimum space occupied by the grey line and no overlapping whatsoever and if you imagine a query that looks up the values of 30 millions – whole 7 segments will be subjects to the search.
For showing you what I mean, I will lead you with the traditional method of tuning the Columnstore Indexes, where creation of the Clustered ROWSTORE Index follows with the creation of the Clustered Columnstore Index (and there is no MAXDOP for Azure SQL Data Warehouse unfortunately…) :
CREATE CLUSTERED INDEX cci_SampleDataTable ON dbo.SampleDataTable ( C1 )
WITH (DROP_EXISTING = ON)
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable
ORDER ( C1 )
WITH (DROP_EXISTING = ON);
SELECT min_data_id, max_data_id, distribution_id, segment_id, row_count
FROM sys.pdw_nodes_column_store_segments seg
ORDER BY distribution_id, segment_id;
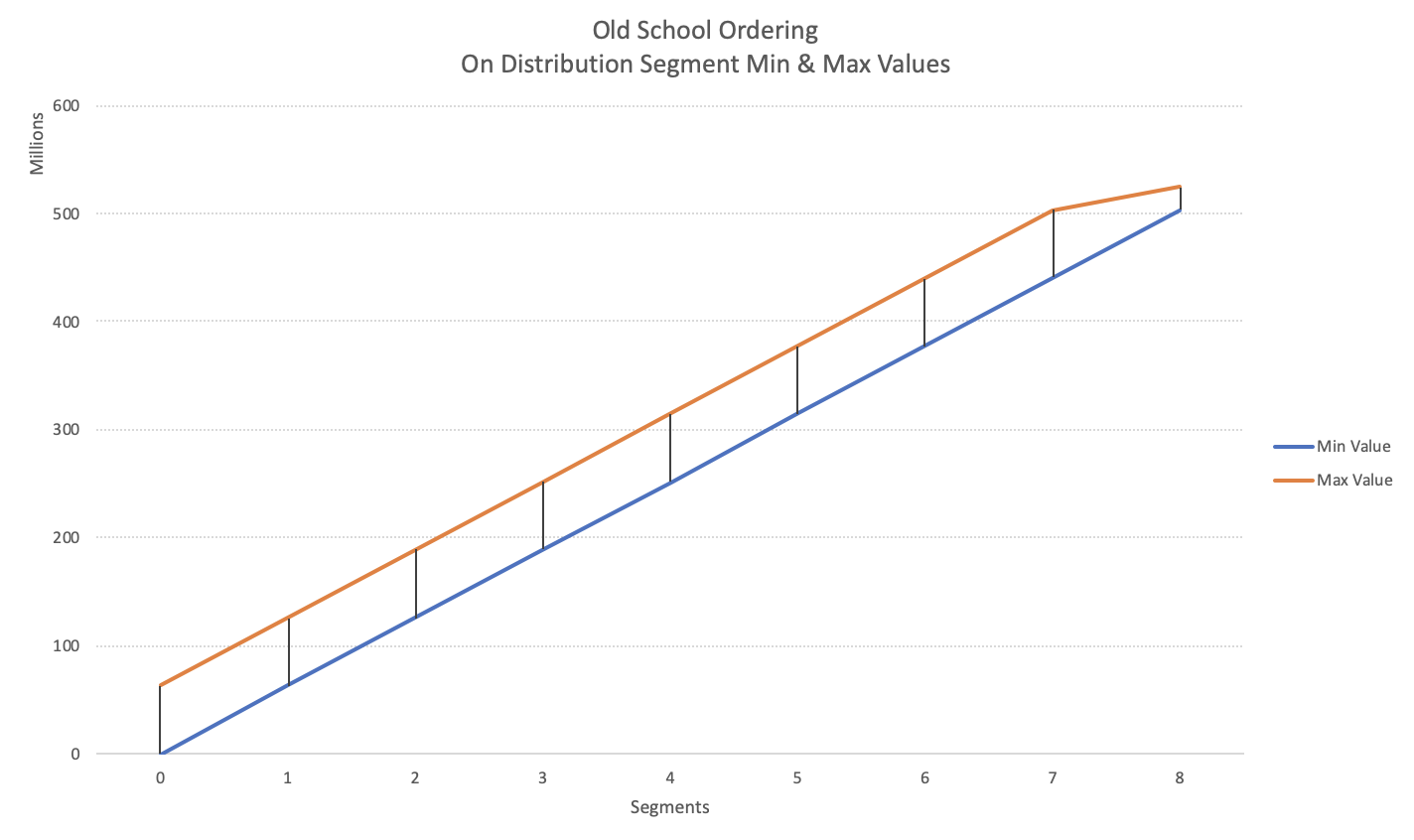
For looking up the same value the Query Optimizer would have to process just 1 segment of the 7.
This is what I would expect, or at least something similar … I would totally understand those traditional “steps” from the parallelism, that those who attended my workshops have had to learn.
Mind the Environment
Well … :)
 It comes that actually I have forgotten something QUIIITE important while doing my initial tests – the resource classes in Azure SQL Data Warehouse. Even though the ever-patient James Rowland Jones taught me this in his wonderful workshop at SQLBits about the resources classes I tend to forget about them and the fact the default administrator has the smallest resource class which accesses just 3% of the total memory available to the Azure SQL Data Warehouse instance, the complete documentation on this topic you can find (surprise!!!) at the Microsoft Documentation site. Think about this problem as you would think about Resource Governance management in traditional Sql Server.
It comes that actually I have forgotten something QUIIITE important while doing my initial tests – the resource classes in Azure SQL Data Warehouse. Even though the ever-patient James Rowland Jones taught me this in his wonderful workshop at SQLBits about the resources classes I tend to forget about them and the fact the default administrator has the smallest resource class which accesses just 3% of the total memory available to the Azure SQL Data Warehouse instance, the complete documentation on this topic you can find (surprise!!!) at the Microsoft Documentation site. Think about this problem as you would think about Resource Governance management in traditional Sql Server.
To solve this problem I decided to create a new Login CCIBuilder with some super-secret password:
CREATE LOGIN CCIBuilder
WITH PASSWORD = 'YouGotMy$#$%=^Sec$%#$%ret_243';
Inside the database, we need to create the respective user and add this user to the db_owner and the larger resource role, because we want to give at least 22% of the available memory for the sorting task:
CREATE USER CCIBuilder for LOGIN CCIBuilder; EXEC sp_addrolemember 'db_owner', 'CCIBuilder'; EXEC sp_addrolemember 'largerc', 'CCIBuilder';
And then without any further complications besides changing the sys.objects to sys.all_objects in our original script I executed the old/new version and loaded 500 million rows into our test table:
DROP TABLE dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL
) WITH (HEAP);
SET NOCOUNT ON
INSERT INTO dbo.SampleDataTable
SELECT t.RN
FROM
(
SELECT TOP (100 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.all_objects t1
CROSS JOIN sys.all_objects t2
CROSS JOIN sys.all_objects t3
CROSS JOIN sys.all_objects t4
CROSS JOIN sys.all_objects t5
CROSS JOIN sys.all_objects t6
CROSS JOIN sys.all_objects t7
CROSS JOIN sys.all_objects t8
CROSS JOIN sys.all_objects t12
CROSS JOIN sys.all_objects t13
CROSS JOIN sys.all_objects t14
CROSS JOIN sys.all_objects t15
CROSS JOIN sys.all_objects t16
CROSS JOIN sys.all_objects t17
CROSS JOIN sys.all_objects t18
) t
OPTION (MAXDOP 1);
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable
ORDER ( C1 )
-- Check the final results
SELECT min_data_id, max_data_id, distribution_id, segment_id, row_count
FROM sys.pdw_nodes_column_store_segments seg
ORDER BY distribution_id, segment_id;
My results can be seen on the imagse below (again, I am focusing here at the level of one distribution) and you can definitely notice some improvements when comparing to the original sorting output, but still far from being perfect:


Trusting that this might not be enough, the next logical step is to go up to the 70% of the available memory usage with the Extra Large Resource Role – xlargerc:
EXEC sp_addrolemember 'xlargerc', 'CCIBuilder';
,
while not forgetting to reconnect to the Azure SQL Datawarehouse for the test purposes.
The definitely strange feeling here is that our table is tiny and its occupied space should be virtually invisible for the Azure SQL Datawarehouse.
The results were still disappointing:

Bearing in mind that I am a cheap bloke and using the lowest available tier (DW100C), I decided to scale until I can find some reasonable result and I naturally started with DW200C, and voila the results below – we got exactly what we wanted:
The image I have been waiting and fight for during the days!!!
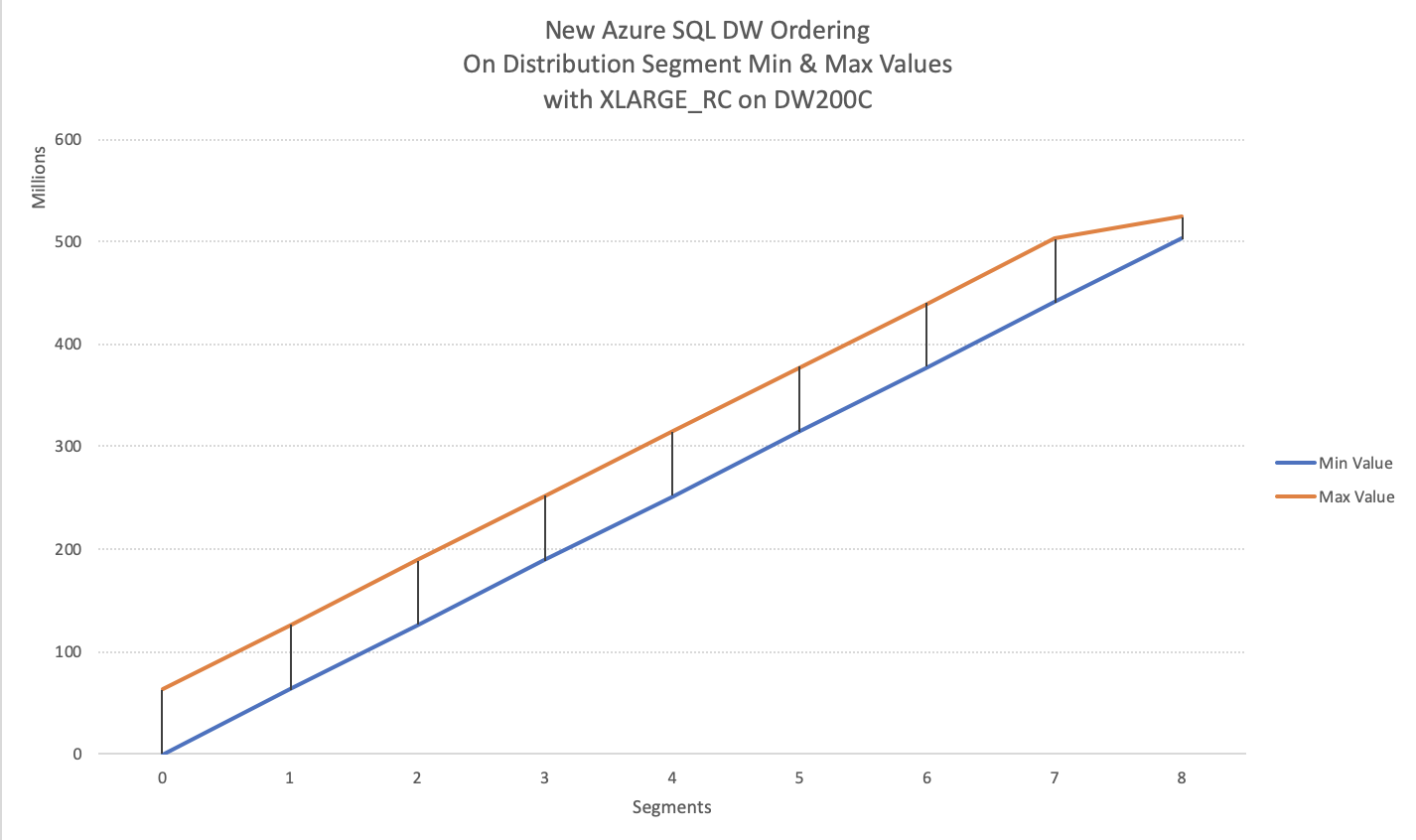
The alignment is 100% and it is indeed perfect as expected.
Take a look at the resources consumption when I was doing my final tests (that was days after discovering the problem with the great help of Xiaoyu Li):
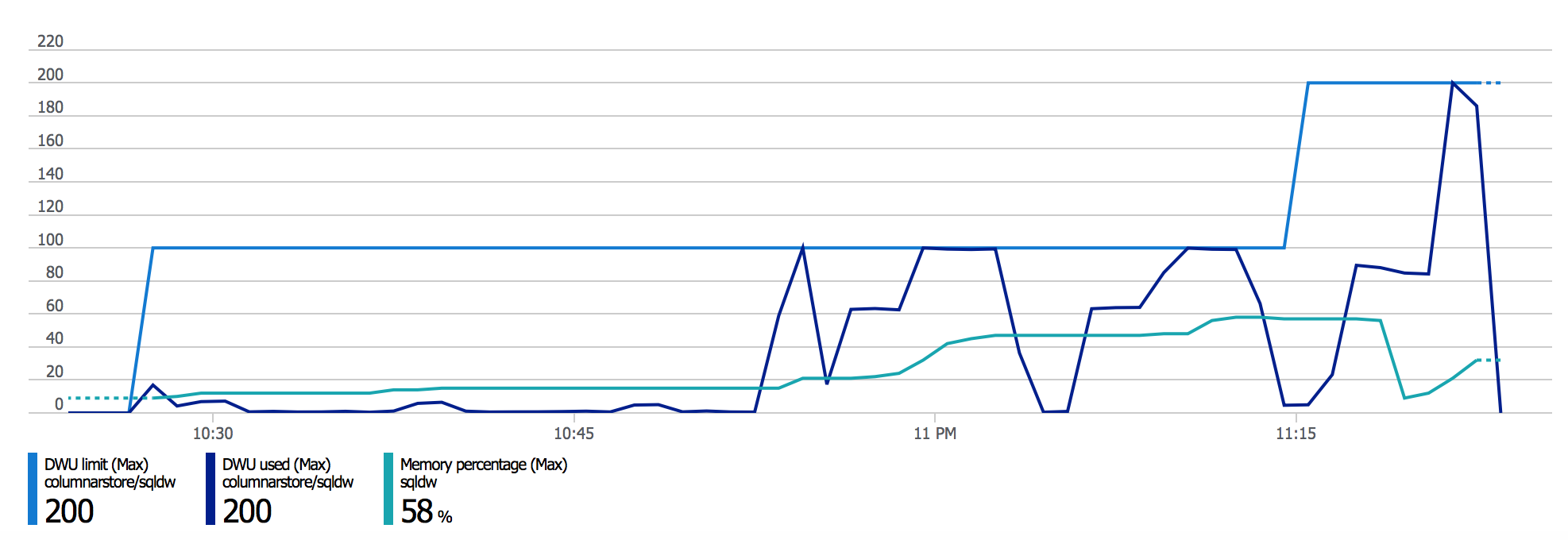
It seems though as the memory was not the main problem or that the indicators are not showing the exact depth of it, but without any shadow any sorting is a question of available memory.
Early Thoughts
Even though this is a public preview functionality and not a GA, I believe there must be a better messaging about the process.
– Better Documentation on the requirements of the memory and DWUs for respective operations
– A clear warning mechanism that there is not enough memory to complete the operation as expected. Imagine someone scaling down the Data Warehouse for whatever purposes and until the rebuild process every performance will be fine. By the moment an Index Rebuild is executed the alignment falls completely apart because of lack of the memory, the discovery process not only of the developers and DBAs, but even Microsoft Support will go totally insane trying to determine the reasons for the difference.
– I would love to be able to determine if I want to sort in-memory or by using TempDB. Sometimes there is enough time for slow sorting but I NEED the result and sometimes all I care is the speed to get the job done – cause the maintenance windows is coming to an end. Would it not be nice if we could specify the sorting destination ? (There is an old error message since Sql Server 2017 pointing out that sorting is not supported in TempDB … I am sure it can be fixed though :))
DMVs
One can determine what table and index are sorted on which columns through the good old sys.index_columns DMV where the new column column_store_order_ordinal will shine the light upon the information:
SELECT column_store_order_ordinal, *
FROM sys.index_columns
WHERE object_id = OBJECT_ID('SampleDataTable');
![]() What gives me even more joy is the location of this property – thus it should be possible and expectable to get this feature one day on Azure SQL Database, Azure SQL Managed Instance and Sql Server. :)
What gives me even more joy is the location of this property – thus it should be possible and expectable to get this feature one day on Azure SQL Database, Azure SQL Managed Instance and Sql Server. :)
Notice that if we sort on the multiple columns, with the exact value within column_store_order_ordinal column we shall be able to determine the exact order of those columns.
SSMS Support
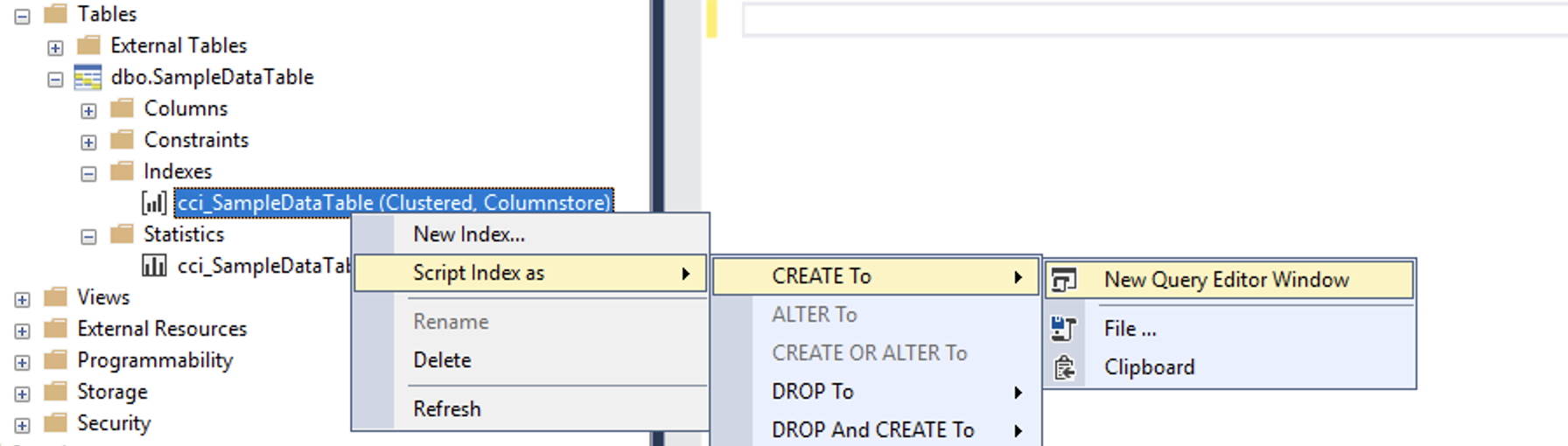 Starting with SSMS 18.3 there is support for ORDER option when scripting out the Clustered Columnstore Indexes on Azure SQL Data Warehouse, as you can notice on the picture on the left side of this very text.
Starting with SSMS 18.3 there is support for ORDER option when scripting out the Clustered Columnstore Indexes on Azure SQL Data Warehouse, as you can notice on the picture on the left side of this very text.
The output will include all defined column for sorting, which is cool and necessary option for a comfortable and secure (as in not loosing the configuration) deployment of this feature.
![]()
The Performance
There is nothing like understanding the real performance implications for using a new feature and for that purpose I ran multiple times the following scripts for recreating the Clustered Columnstore Index without an order as well as recreating it in an ordered fashion, to check how much of a difference in overall execution time it will produce:
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable WITH (DROP_EXISTING = ON);
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable ORDER ( C1 ) WITH (DROP_EXISTING = ON);
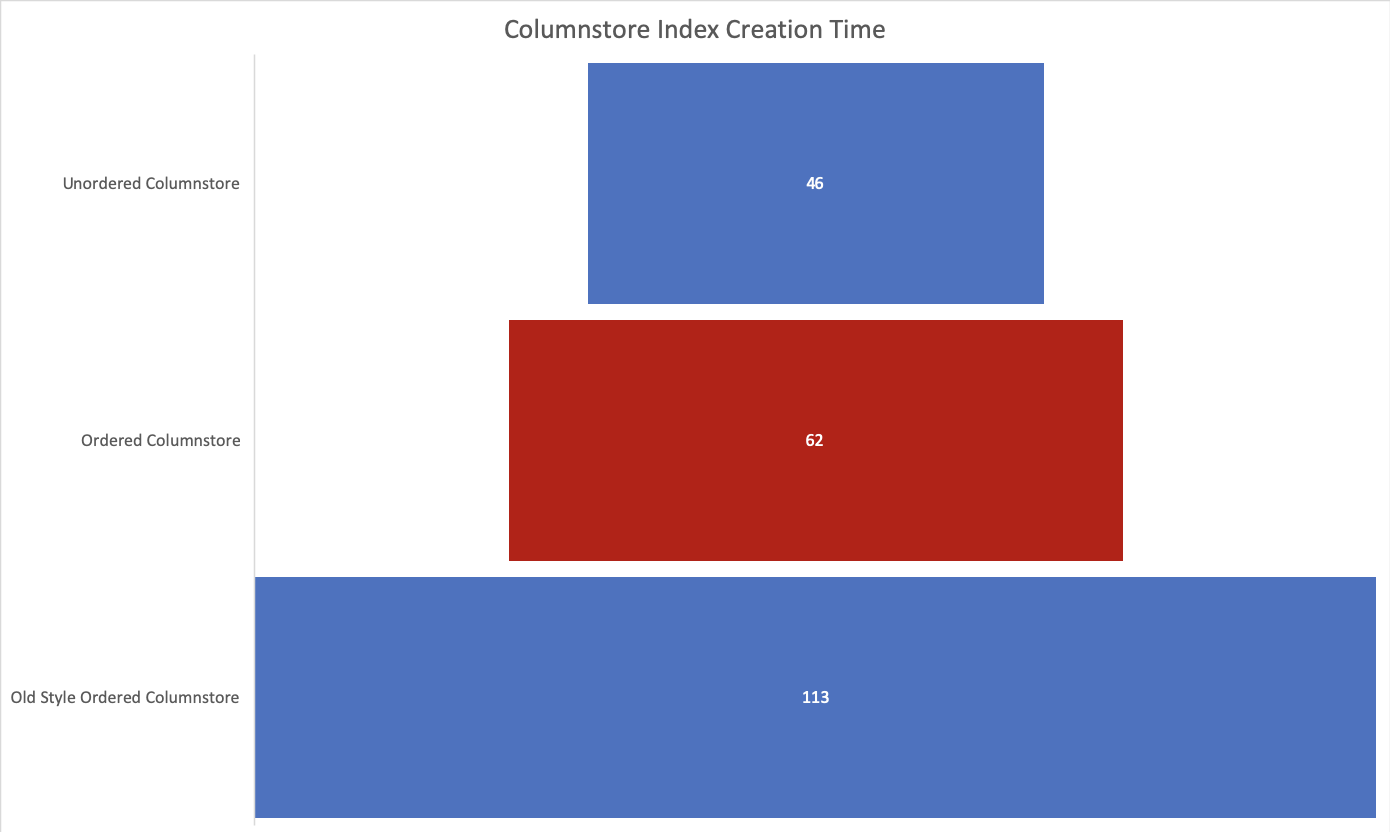 The results after multiple executions on DW200C tier instance (and you will have to test your own data to arrive to any reasonable conclusion. The loss of 34% for getting data ordered for Clustered Columnstore Indexes seems to be quite heavy, but given that we are wrangling and sorting the data, this will work perfectly well for the scenarios where a reasonable maintenance window can be found. The good news is when comparing to 145% loss that occurs when sorting the Columnstore Indexes in the old ways – the new functionality sounds truly exciting!
The results after multiple executions on DW200C tier instance (and you will have to test your own data to arrive to any reasonable conclusion. The loss of 34% for getting data ordered for Clustered Columnstore Indexes seems to be quite heavy, but given that we are wrangling and sorting the data, this will work perfectly well for the scenarios where a reasonable maintenance window can be found. The good news is when comparing to 145% loss that occurs when sorting the Columnstore Indexes in the old ways – the new functionality sounds truly exciting!
Of course re-sorting is not a daily activity in the most cases and hence there is no need to worry about the wrong stuff such as physical fragmentation and so on.
Space Occupied by Sorted vs Non-sorted Columnstore Index
I expect this to be a relatively minor item, but of course there will be outliers. For the test table the results were pretty much the same (Ha! There is only one column with distinct values!) and for some test Data I won’t be able to share on the blog my results were within 2% of variation, making it negligible in my eyes.
Further Important Questions and Improvements
What about the future additions of the Segments ? I would love that in the matter of possible the data if loaded through Bulk Load API would at least be sorted and attempted to be integrated with the existing values. Imagine if we are simply adding additional 500 Million values that are sequential and starting right at the point where we stopped. It would be sad if we would ignore this.
Oh and by the way, there must be a way to improve communication between the distributions… A kind of impossible, most probably, but still I wish we could have a knob for it !
Final Thoughts
Ordering data makes total sense and can result in huge performance gains. On Azure SQL Data Warehouse one must keep in mind that because of the internal distributions, while a single table should have at least 60 million rows, with current sorting implementation the overlapping will carry on between the distributions. The effect of ordering will become visible only after we have at least a couple of Segments in each of the distributions – meaning that a starting point for Clustered Columnstore Indexes on Azure SQL Data Warehouse will be around 100-120 million rows and only after reaching a good billion of rows it should become truly impactful.
A very important part to keep in mind that while rebuilding Clustered Columnstore Index, a partition-level operation is a huge paramount to success. The ordering takes place on the partition level in any way and so you will have less data to sort and can finish the operation faster and affecting less the overall access to the table potentially. For some obscure reasons to me – partitioning is still the one of most less understood and less used tool overall on Microsoft relational platform. On Azure SQL Data Warehouse seems to be few reasons not to use it, if you are working with large billions of rows.
Azure SQL Datawarehouse keeps adding features that distinguish this platform from other Microsoft Data Platform offerings – starting with the automatically closing Delta-Stores (which I need to write on, especially since they are to make it into SQL Server 2019).
My guess is that there will be scenarios when people will simply choose Azure SQL DW based on the features that are exclusive to the platform and face the differences & difficulties in order to gain important momentum.
From the other perspective, of course the gap between the new features making into Azure SQL Database and SQL Server is not getting smaller with time, but
The more advanced features of T-SQL must be a huge pain in the neck to implement in the distributed system, but they are still the key for the successful migrations to Azure SQL Datawarehouse and without them most clients are too scared to risk facing truly complex challenges.
Coming back to the SQL Server & Azure SQL Database –Â I want this feature. I want it badly. Dear Microsoft, I know that there are other priorities – but this one will make so many happy – it is difficult to underestimate the true impact.
This is one of my top wished features for so long, beating the need to control the maximum size of the Row Groups and almost reaching the level of the good dictionaries for the strings and persisted computed columns …
to be continued with Columnstore Indexes – part 129 (“Compatibility with the New Features of Sql Server 2019”)
Segment elimination really is quite fragile. As you point out it’s an operational risk. Seemingly low-risk changes can radically alter query performance. This can be downtime inducing.
To me, it seems that partitioning is the most reliable form to force segment elimination to occur.
I’d like to have a more lightweight feature than partitioning for this. I’d like to declare that incoming data is to be split cleanly into segments. For example, I’d want to declare that for each month SQL Server is supposed to keep completely segregated segments and delta stores. No need for all the partitioning mechanic.
Like this:
CREATE INDEX …
PARTITION SEGMENTS BY (Month)
This could be combiled with the “ORDER” feature that already exists. Partitioning would be more appropriate for low cardinality values such as status enums. If we sort on those we’d get multiple different values per segment. Ideally, we want just one.
Hi tobi,
Indeed … This is a great idea!
I guess that partitioning in general did not have enough love & attention from Microsoft after the initial release.
I expect that after SQL 2019 the Columnstore Indexes will get more attention again …
Best regards,
Niko