This is the 5th blog post in the growing series of blogpost on the Graph features within SQL Server and Azure SQL Database that started at SQL Graph, part I.
This time we are focusing on the one of the most important addition to the graph engine in SQL Server 2019 (CTP 3.1 to be more precise) that is introducing the support of the shortest path to the SQL Server & Azure SQL Database. With other prominent members of Microsoft Data Platform holding the keys to claim the support of the shortest path algorithm it was very important to break this chain for the most essential member – the relational database engine.
The Shortest Path is something of a 101 member (aka basic) when you are learning the databases – it is the name for the family of algorithms that are used to calculate the shortest path between 2 vertices in a graph. The most common purpose of such calculations is finding the most effective way of travelling between two places, where we want to make sure that our trip is the most effective one. Another usage case would be something that you might have heard – the term 6 degrees of separation (supposedly the distance (number of connections) that any human is distanced from any other humans on the planet). As a matter of a fact this is one of the most frequently used algorithms for solving more complex and let’s say more important problems, such as the Betweenness Centrality or Transitive Closure.
The application range will go from transit and movement processes to information/virus spreading, maze solving & so much more.
The most often referred algorithm to me is the Dijkstra’s algorithm – some of my friends and colleagues will mention this one (sometimes under “that unpronounceable name”) that allows one to calculate non-negative edge weight path between 2 vertices, while other algorithms of course have their place and applications – the cases where the edges have a negative weights and so on (and in the end the decision of the algorithm choice will be always up to the database maker).
I have to be honest – once Microsoft has revealed that the Graph Engine is coming into Azure SQL Database & SQL Server, the minimal feature set I was expecting, and to be clear – the ABSOLUTE minimum of the features sets I was expecting would definitely include the shortest path, but the SQL Server 2017 came and we have had no such functionality. It is now that we can rightfully rejoice that this feature (essential for a fully-fledged graph engine in my opinion) is coming with SQL Server 2019. I am incredibly happy and grateful to the team who are working very hard to deliver us new functionalities and the only hard critic I have is mostly targeted to the leadership: to put more resources into development to deliver more content. :)
And so a couple of weeks ago the ever-amazing Shreya Verma, who is pushing the Graph Engine development from the Program Management side has published the official announcement of the Shortest Path capabilities in the Graph Engine.
T-SQL Changes with the Shortest Path
The number of changes to the T-SQL languages is quite interesting – besides having a new function SHORTEST_PATH(), changes to the syntax of the table node referral, aggregation function application, reserved keywords combination for the WITHIN GROUP (GRAPH PATH) expanded beyond the initial offering of the STRING_AGG() aggregation function in SQL Server 2017.
In the times like this – it all sounds to me like a major addition to the graph engine, which makes me truly happy.
Let’s start with some of the details:
SHORTEST_PATH() function will allow you to traverse the given graph looking for the shortest path between different Nodes. It will use the Arbitrary Length Pattern to define the traversal path. This function will not return any results any results in SELECT clause because it must be used within MATCH clause only!
To my understanding because one of the mechanisms being used is depth-first search, in situation where multiple shortest path do exist, the function will return the first one only.
Arbitrary Length Pattern is the definition of how deep/far the SHORTEST_PATH should execute its search. If we have a really big graph with hundreds of thousands of Nodes, the task might become unbearable for any graph engine and for that purpose some of the algorithms will use the simplification with the definition of the clusters of the Nodes – defining them as a one single node, because if you are doing a calculation over all possible shortest paths in such a graph, you better have a couple of weeks/years and a very big drive to store the intermediate results … :)
Back to the Arbitrary Length Pattern – in SQL Graph (yeah, I call it this way), we can define the length pattern of the calculation with 2 possibilities:
1. + : plus means that there is no limit, and the engine will have to traverse the graph as deep as needed, virtually unlimited.
2. {1,n} : Will repeat the pattern from 1 to n times. The search will terminate as soon as the max number of pattern iterations (n) is reached.
FOR PATH is a requirement to be applied with a Node or an Edge table within the FROM section for every single Node/Edge that will participate in the calculation of the Shortest Path. This is a really cool identification and I really love this requirement, that will force T-SQL writers to know what they are writing and to focus on the better practices. I always wished that a wrong identification of a table with a FOR PATH attribute will force an error message and this is exactly what is to be found in the engine.
FOR PATH identifies the Node/Edge that will return a collection and that the attributes of this table cannot be projected directly in the SELECT clause and cannot be filtered directly in the WHERE clause.
If you have a need to project the results from the Edge/Node table to the SELECT or to filter those sources, you will have to use one of the Graph Path Aggregate Functions for that purpose.
I think that this item will give the biggest headache to the developers, but reading the documentation (haha, who is reading the documentation in the modern times!) will give the right understanding.
Graph Path Aggregate Functions
These are the functions that will allow us to return the results and to filter the search collection as described in the FOR PATH section.
For the purpose of calculations and returning the results we shall have the following functions in the initial release: STRING_AGG, LAST_VALUE, SUM, AVG, MIN, MAX and COUNT. These functions can also be used in SELECT or ORDER BY clauses.
Testing the Shortest Path
Let’s set up the test scenario with 2 nice tables – table Person which will be a Node table & a table Follows which will serve as the Edge table, connecting the Person Nodes. We are also adding the EDGE Constraint EDG_Person_Follows making sure that a person can only follow another person:
DROP TABLE IF EXISTS dbo.Follows;
DROP TABLE IF EXISTS dbo.Person;
CREATE TABLE dbo.Person(
PersonID BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED ,
FULLNAME NVARCHAR(250) NOT NULL ) AS NODE;
CREATE TABLE dbo.Follows(
Since DATETIME2 NULL,
CONSTRAINT EDG_Person_Follows CONNECTION (Person TO Person)
)
AS EDGE;
We need to put some data and for that purpose I am adding the following connections between the 12 imaginary persons that I have created:
John Doe follows Maxine Williams, Manha Curran, Maysa Hays, Ciaron Roberts & Carole Sanchez
Andres Martins follows Tyron Mcdonnell
Tyron Mcdonnell follows Ellesha Wong & Sumaya Lang
Sumaya Lang follows the same people as John Doe: Maxine Williams, Manha Curran, Maysa Hays, Ciaron Roberts & Carole Sanchez
Maxine Williams follows Manha Curra, Maysa Hays, Simrah Freeman, Rickie Devine
Carole Sanchez follows Andres Martins, Maxine Williams and Simrah Freeman
TRUNCATE TABLE dbo.Follows;
DELETE FROM dbo.Person;
INSERT INTO dbo.Person
VALUES ('John Doe'),
('Andres Martins'),
('Tyron Mcdonnell'),
('Ellesha Wong'),
('Sumaya Lang'),
('Maxine Williams'),
('Manha Curran'),
('Maysa Hays'),
('Ciaron Roberts'),
('Carole Sanchez'),
('Simrah Freeman'),
('Rickie Devine');
-- John Doe follows almost everyone whos name starts with letters C &vM (but not himself, as obvious)
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and (p2.FULLNAME LIKE 'C%' OR p2.FULLNAME LIKE 'M%')) pf
WHERE p1.FULLNAME = 'John Doe';
-- Andres Martins follows Tyron Mcdonnell
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.FULLNAME = 'Tyron Mcdonnell'),
GetDate()
FROM dbo.Person p1
WHERE p1.FULLNAME = 'Andres Martins';
-- Tyron follows Ellesha & Sumaya
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.FULLNAME IN ('Ellesha Wong','Sumaya Lang')) pf
WHERE p1.FULLNAME = 'Tyron Mcdonnell';
-- Sumaya follows the same people as John Doe
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and (p2.FULLNAME LIKE 'C%' OR p2.FULLNAME LIKE 'M%')) pf
WHERE p1.FULLNAME = 'Sumaya Lang';
-- Maxine follows Manha, Maysa, Simrah & Rickie
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and p2.FULLNAME IN ('Manha Curran','Maysa Hays','Simrah Freeman','Rickie Devine')) pf
WHERE p1.FULLNAME = 'Maxine Williams';
--Carole Sanchez follows Andres, Maxine and Simrah
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and p2.FULLNAME IN ('Maxine Williams','Andres Martins','Simrah Freeman')) pf
WHERE p1.FULLNAME = 'Carole Sanchez';
 The visual overview, created with an excellent free, multi-platform and open-sourced tool called Gephi is presented on the picture on the left.
The visual overview, created with an excellent free, multi-platform and open-sourced tool called Gephi is presented on the picture on the left.
Even with just 12 Nodes and just 20 Edges, some of the calculations won’t be that easy for a regular human, given the directed graph and the necessity to compare with the alternatives paths.
Let’s take our first attempt at calculating the Shortest Path in the SQL Server 2019 and run the following query, which will show us all possible Edge Paths from the John Doe (and to remind you that the selection of the shortest path will return you not 1 but a conjunction of the different shortest path to all available nodes, if we won’t specify the final Node):
SELECT p1.PersonId, p1.FULLNAME as StartNode, LAST_VALUE(p2.FULLNAME) WITHIN GROUP (GRAPH PATH) AS FinalNode, STRING_AGG(p2.FULLNAME,'->') WITHIN GROUP (GRAPH PATH) AS [Edges Path], COUNT(p2.PersonId) WITHIN GROUP (GRAPH PATH) AS Levels FROM dbo.Person p1, dbo.Person FOR PATH p2, dbo.Follows FOR PATH follows WHERE MATCH(SHORTEST_PATH(p1(-(follows)->p2)+)) AND p1.FULLNAME = 'John Doe';
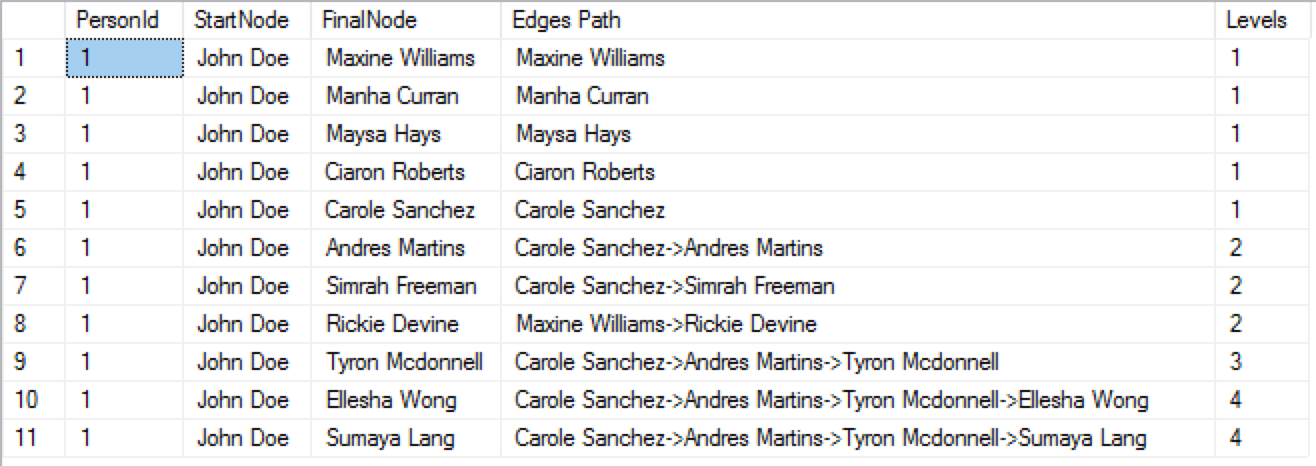 Let’s parse through the query itself:
Let’s parse through the query itself:
– We are using Graph Path Aggregate Functions LAST_VALUE, STRING_AGG and COUNT that require the usage of the WITHIN GROUP (GRAPH PATH) attribute, specifying that the aggregations/calculations shall be done over the graph path.
– we have the original dbo.Person Node with the alias of p1 which do not have FOR PATH specification, since we shall not be parsing calculating the shortest path over this reference in our query
– we have the second reference of the dbo.Person Node, this time with the FOR PATH attribute, because we shall be constantly looping over it with the Shortest Path calculations
– the same attribute FOR PATH is applied to our Edge dbo.Follows, since we need to loop over it.
– the SHORTEST_PATH function is within the MATCH predicate, explicitly stating the search path that a person should follow another person and that there is no limit for the depth search since the Arbitrary Length Pattern is specified with + (plus).
– we are filtering on the name of the person from the original table that contains no FOR PATH attribute, because any predicate over the p2 at this level of the query would be illegal and would result in an error.
Notice that we are not attempting to filter the final destination of the shortest path and that’s the reason why we receive 11 results for every other destination in our graph with 12 nodes (excluding the John Doe himself).
Let’s filter then on the destination Node and in this case let’s select Tyron McDonnell. In order to be a correct T-SQL query we shall need to wrap the filter over the original query in the following way, where the original query will be a source from which we are selecting – meaning we are really wrapping around the original query:
SELECT StartNode, [Edges Path], FinalNode, Levels FROM (SELECT p1.PersonId, p1.FULLNAME as StartNode, LAST_VALUE(p2.FULLNAME) WITHIN GROUP (GRAPH PATH) AS FinalNode, STRING_AGG(p2.FULLNAME,'->') WITHIN GROUP (GRAPH PATH) AS [Edges Path], COUNT(p2.PersonId) WITHIN GROUP (GRAPH PATH) AS Levels FROM dbo.Person p1, dbo.Person FOR PATH p2, dbo.Follows FOR PATH follows WHERE MATCH(SHORTEST_PATH(p1(-(follows)->p2)+)) AND p1.FULLNAME = 'John Doe' ) src WHERE FinalNode = 'Tyron Mcdonnell';

The result speaks for itself.
If we want to list every single person who is not further than just 2 connections away from John Doe, we just need to specify the Arbitrary Length Pattern between 1 and 2 in the following format (regular expression kind-of) – {1,2}:
SELECT
p1.PersonId,
p1.FULLNAME as StartNode,
LAST_VALUE(p2.FULLNAME) WITHIN GROUP (GRAPH PATH) AS FinalNode,
STRING_AGG(p2.FULLNAME,'->') WITHIN GROUP (GRAPH PATH) AS [Edges Path],
COUNT(p2.PersonId) WITHIN GROUP (GRAPH PATH) AS Levels
FROM
dbo.Person p1,
dbo.Person FOR PATH p2,
dbo.Follows FOR PATH follows
WHERE
MATCH(SHORTEST_PATH(p1(-(follows)->p2){1,2}))
AND p1.FULLNAME = 'John Doe'
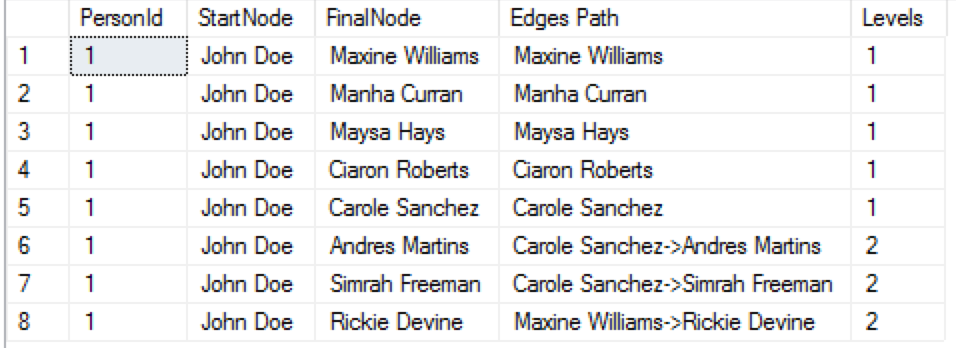 On the right image you can see the results where we are not getting the 3 and 4 level connections from the John Doe, because our Arbitrary Length Pattern has limited the depth of the search just by the 2 levels.
On the right image you can see the results where we are not getting the 3 and 4 level connections from the John Doe, because our Arbitrary Length Pattern has limited the depth of the search just by the 2 levels.
Imagine writing your own queries to do this job! Oh yes, some people indeed made such efforts in the past 15 years …
Errors
There are some interesting error that must be pretty frequent for the people starting up with the Shortest Path:
– Referring to the table that is marked with the FOR PATH attribute for parsing/looping (and in the query below I am referencing the p2 alias of the Person FOR PATH Node):
SELECT p1.PersonId, p1.FULLNAME as StartNode, LAST_VALUE(p2.FULLNAME) WITHIN GROUP (GRAPH PATH) AS FinalNode, STRING_AGG(p2.FULLNAME,'->') WITHIN GROUP (GRAPH PATH) AS [Edges Path], COUNT(p2.PersonId) WITHIN GROUP (GRAPH PATH) AS Levels FROM dbo.Person p1, dbo.Person FOR PATH p2, dbo.Follows FOR PATH follows WHERE MATCH(SHORTEST_PATH(p1(-(follows)->p2)+)) AND p1.FULLNAME = 'John Doe' AND p2.FullName = 'Ellesha Wong';
The result of the error message is printed below:
Msg 13961, Level 16, State 1, Line 1 The alias or identifier 'p2.FullName' cannot be used in the select list, order by, group by, or having context.
– Graph Path Aggregate Functions without WITHIN GROUP (GRAPH PATH) – in the query below I am trying to do a COUNT() without a GRAPH PATH
SELECT p1.PersonId, p1.FULLNAME as StartNode, LAST_VALUE(p2.FULLNAME) WITHIN GROUP (GRAPH PATH) AS FinalNode, STRING_AGG(p2.FULLNAME,'->') WITHIN GROUP (GRAPH PATH) AS [Edges Path], COUNT(p2.PersonId) AS Levels FROM dbo.Person p1, dbo.Person FOR PATH p2, dbo.Follows FOR PATH follows WHERE MATCH(SHORTEST_PATH(p1(-(follows)->p2)+)) AND p1.FULLNAME = 'John Doe';
The error message is also about to be clear on the error:
Msg 13961, Level 16, State 1, Line 1 The alias or identifier 'p2.PersonId' cannot be used in the select list, order by, group by, or having context.
Important but sad news
Now to the bad news – there is no way right now to calculate the weighted path. If you are using complex calculations that require weighted calculations, such as the ones in the travelling or any complex calculations for the radio tower placements – you are out of luck currently. I see how to solve this problem currently for a small number of situations (by introducing a number of additional nodes that will lengthen the connections proportionally), but if we go into real decimal values or negative weights – we shall be seriously out of luck.
There is a progressive need of features built in SSMS and in the Data Studio to display the basic graph information and filtering. If we want to get really serious about popularising the Graph Databases, we need to make them much more accessible and explorable for the young people.
If we thing about the geographical information, which visualisation is supported in SSMS – there must be done something to give some basic visualisation, like some of the Azure Platforms, such as CosmosDB are doing.
The good news here is that the documentation is specific on including the words that weighted calculations are not supported, YET. :) Yes, I am an optimist! :)
My views and hopes are on set on the post SQL SERVER 2019 release, and I am truly believing that the future implementations will depend so much on the usage and the celebration of the wonderful work done by Shreya, Devin, Gjorgji and every single person on their team. Of course the respective leader team who approved this effort deserves their praise, but I always prefer to celebrate more the people who are doing the battles in the trenches.
Final Thoughts
I think this opens a brand new era in the Microsoft Relational Data Platform where some of the early graph problems can be effectively solved within the secure and high performing environment. I am tired to repeat to everyone – think abut the complex problems with the speed of the Batch Execution Mode where even a brute force with the intelligence of the Query Optimiser can solve some non-trivial cases within a couple of instants.
I love the additions to the T-SQL and even though I do recognise that not every regular developer will be able to write complex queries with graph analysis easily, but even if we rewind 14 years back – the Windowing Functions still have not received the attention that they deserve because of their complexity. This complex query writing will open more position for Database Developers and Analysts and that’s a good thing for everyone in the industry – the companies can tackle more complex problems with more ease and speed and there will be new roles and jobs to fill. :)
By the way, that WITHIN GROUP (GRAPH PATH) expansion looks interesting, giving me some interesting thoughts on potential of those 7 aggregation functions (STRING_AGG, LAST_VALUE, SUM, AVG, MIN, MAX and COUNT). Is this the are where Microsoft is taking us for the ride ? I am definitely jumping in! :)
I do welcome the new era of the Graph evolution and I hope for many more things to come.
to be continued …
Very nice article. Thanks for pointing to Gephi.
The SQL Server graph extensions are amazing.
I have a graph representation in an external system. These graphs already have there own nodeids and edgeids.
I would like to resuse these IDs as the ID Part of the virtual node_id$/edge_id$ whehn importing the graph.
These would allow the parallel load of nodes and edges without the need to load the nodes first to get the nodes_id$ for to load the edges.
I find it really ugly to qeury the node table for the node_id$ to fill the edges.
I would also like to create a MSTVF to return edges or nodes.
Hi Cristoph,
I do not think what you wish is possible.
I do agree that the ways of getting the node_id$/edge_id$ is far from ideal, but that was the solution that the QP team has choosen to implement and I tend to believe that they have good reasons for that.
Best regards,
Niko
Hey Niko,
yes the design is clever by not introducing new types or sqlclr things. Maybe one day node_id$/edge_id$ creation will be more flexible.. I will definitly use the new graph features when SQL 2019 is released. A graph feature roadmap would be nice. Kind Regards Christoph
Hi Christoph,
agreeing so much with you on the roadmap, but what I imagine is that given the frequency of the releases (a kind of 24 months or something), I guess there is not much wish from Microsoft side to make public any of the roadmaps, given that they change the course so fast & frequently.
I am a believer in the competence of the Program Management and Developers working on the SQL Graph and so I am anxiously waiting for more news and developments.
Best regards,
Niko Neugebauer
Hi Niko,
did you succeed in confincing Visual Studio to accept the new synatx? I get “synatx error” …
Cheers
Christoph
Hi Christoph,
Nope, not really. I did not tried.
Best regards,
Niko Neugebauer
Excellent. The most useful GRAPH on SQL Server article I’ve found.
On the shortest path example between ‘John Doe’ and ‘Tyron Mcdonnell’, is it possible to retrieve each hop as a separate row rather than having them in the string_Agg function (other than taking them back out of string_agg)?
Hi Paul,
Thank you for the kind words.
You could use STRING_SPLIT() function in order to extract the single hops.
Best regards,
Niko