I would like to share a little secret with you. Well, that is not exactly a secret – it has been publicly available since a good number of months in preview (6 months, I believe to be more precise), and I have been sharing the news on this feature in my presentations since at least June (Hi people from Porto.Data, do you remember my last session ? :))
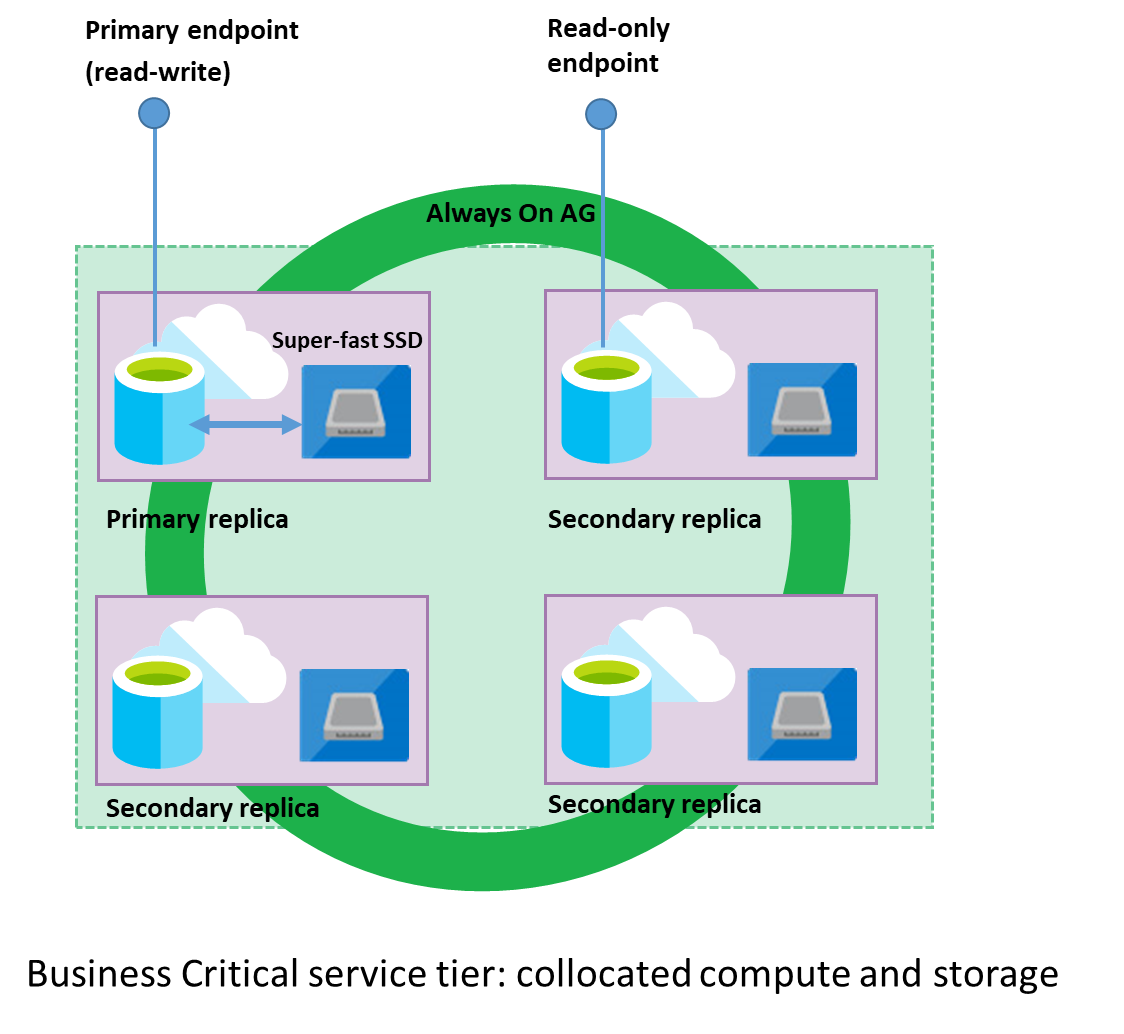
For the last almost 10 years, every single presenter on the Azure SQLDatabase kept repeating some variations of the introduction phrase “Azure is doing its best to deliver you a certain high availability and disaster recovery by keeping 3 replicas of your Azure SQLDatabase. Should something go wrong with the instance you are working on, the secondary REPLICA will take over and carry on“.
Yeah, RE-PLI-CAS…
3 of them in total!
Just like in a Availability Group …
Meaning that potentially we could use the secondary replicas not just for the DR or HA, but also to improve the reading through-output, or in other words to set up a Read Scale.
In the solutions, such as Data Warehousing – where read access can be very heavy, spreading them out is absolutely essential, and this alone could mitigate some of the impact of the Azure SQL Database Recovery Model (which is FULL only, as required by the Availability Groups).
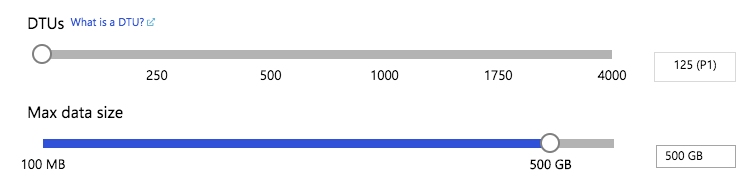 In order to set up a Premium Tier/Edition Azure SQL Database is needed. We may argue from different angles of how which editions should provide this functionality, but I believe that there is some certain point of support where any company is not financially capable/interested in providing you the network bandwidth, disk speed, etc – beyond which there is no financial sense. After all, this a commercial public cloud is a commercial service. :)
In order to set up a Premium Tier/Edition Azure SQL Database is needed. We may argue from different angles of how which editions should provide this functionality, but I believe that there is some certain point of support where any company is not financially capable/interested in providing you the network bandwidth, disk speed, etc – beyond which there is no financial sense. After all, this a commercial public cloud is a commercial service. :)
In any case, expecting this functionality from a free tier won’t take you far. ;)
Right now, in October of 2018, there is no way of configuring the “Read Scale-Out” through the GUI (this is how Microsoft calls the Azure SQL DB Readable Secondary option), and for that purpose we can use Powershell or REST API.
Notice, even though the way for the Azure CLI is not documented, I assume that by now it should be working as well.
Let’s execute the following Powershell script, entering into our Azure Account and selecting our subscription, that was used for the Azure SQL Database Premium Edition creation (I have really called it ‘That Secret Subscription’, as you would imagine:
Connect-AzureRmAccount; Get-AzureRmSubscription -SubscriptionName 'That Secret Subscription' | Set-AzureRmContext;
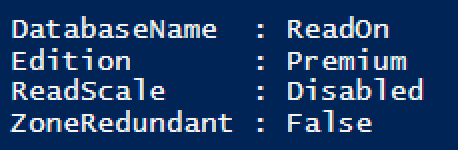 The next steps are pretty easy – we need to invoke the good old Get-AzureRmSqlDatabase and simply obtain the necessary properties and for the demo purposes I have included just the Database Name, its Edition, ReadScale ( this is the one that interests us here ) and the Zone Redundancy:
The next steps are pretty easy – we need to invoke the good old Get-AzureRmSqlDatabase and simply obtain the necessary properties and for the demo purposes I have included just the Database Name, its Edition, ReadScale ( this is the one that interests us here ) and the Zone Redundancy:
Get-AzureRmSqlDatabase -ResourceGroupName mySecretResourceGroup -ServerName secretServerName -DatabaseName 'ReadOn' | Format-List DatabaseName, Edition, ReadScale, ZoneRedundant;
You can see that the ReadScale is disabled, and so all we have to do right now is to enable it with the help of the Set-AzureRmSQLDatabase cmdlet:
Set-AzureRmSqlDatabase -ResourceGroupName mySecretResourceGroup -ServerName secretServerName -DatabaseName 'ReadOn' -ReadScale Enabled;
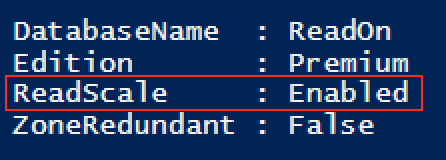 After re-executing the Get-AzureRmSqlDatabase cmd-let, the available & updated properties are visible with the ReadScale clearly showing to be ready for the consumption, and so we can advance and test it out within the Azure SQL Data Studio (or you can still use the good old SSMS, if you wish).
After re-executing the Get-AzureRmSqlDatabase cmd-let, the available & updated properties are visible with the ReadScale clearly showing to be ready for the consumption, and so we can advance and test it out within the Azure SQL Data Studio (or you can still use the good old SSMS, if you wish).
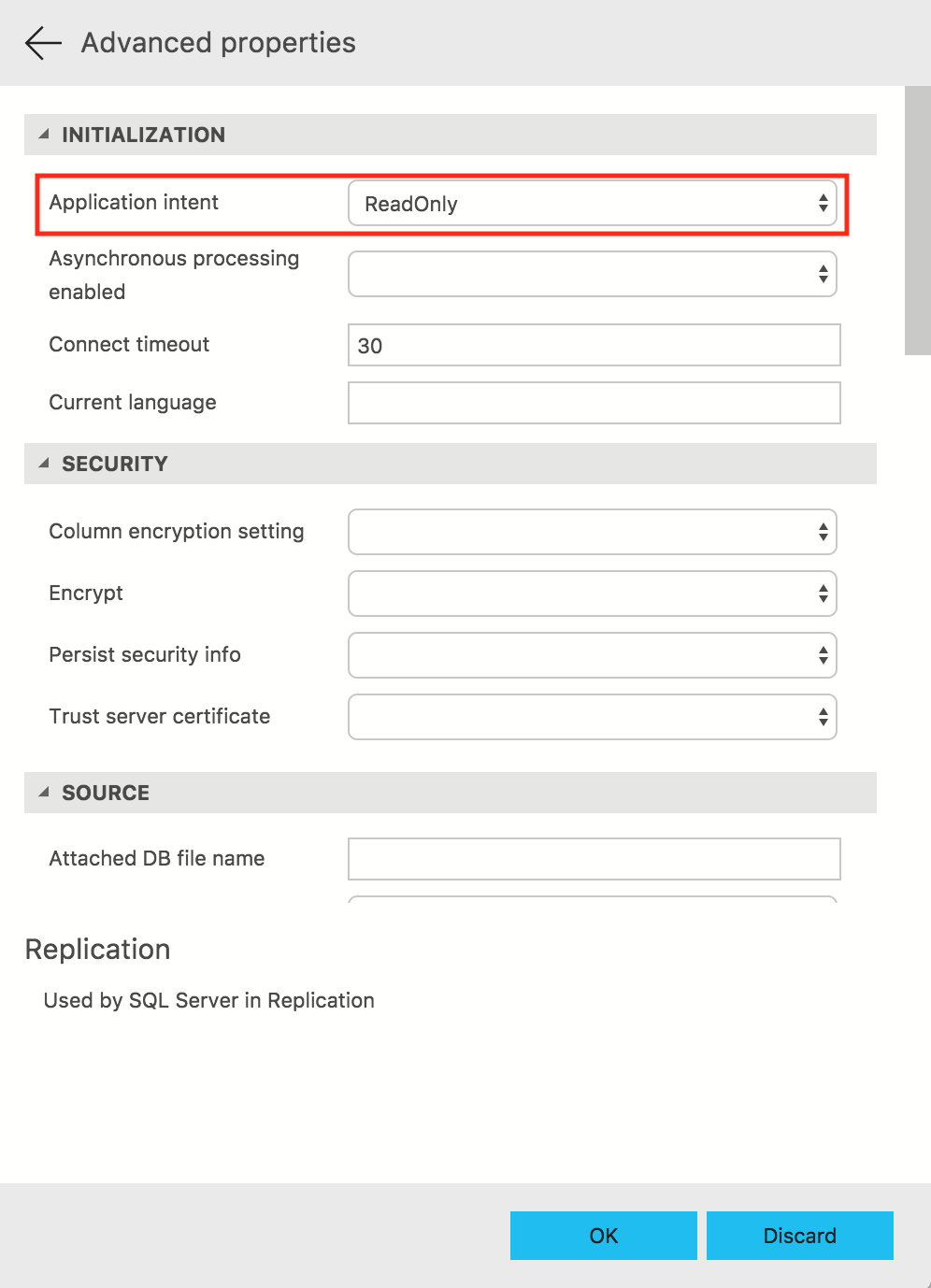 For that purpose, please open the Azure SQL Data Studio, connect to your logical Azure SQL Database Server with the accordingly created credentials and after opening advanced options, select the ApplicationIntent property (currently the one on the top) and choose ReadOnly.
For that purpose, please open the Azure SQL Data Studio, connect to your logical Azure SQL Database Server with the accordingly created credentials and after opening advanced options, select the ApplicationIntent property (currently the one on the top) and choose ReadOnly.
That’s it – connect to the Database and open your query and start firing away your queries right away! :)
But wait a second! How should we be able to determine if we are truly on a different replica, then the primary one? The good battle-hardened sys.fn_hadr_is_primary_replica function does not exists on Azure SQL Database:
SELECT * FROM sys.fn_hadr_is_primary_replica ( 'ReadOn' );
Started executing query at Line 1 Msg 208, Level 16, State 1, Line 1 Invalid object name 'sys.fn_hadr_is_primary_replica'.
Trying out the sys.availability_replicas will not result in anything positive, as well…
According to the documentation, we can use the following database property DATABASEPROPERTYEX(DB_NAME(), ‘Updateability’) in order to find out the current situation:
SELECT DATABASEPROPERTYEX(DB_NAME(), 'Updateability') as [Updatability];

On the image above you can see that I have managed to connect to the read-only replica, and hence should be able to improve my reading performance. :)
Should I try to fire any of the queries that might affect the status of the information on the database, such as DML or DDL, the error message will backfire instantly, warning that database is in read-only mode:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
Started executing query at Line 1 Msg 3906, Level 16, State 2, Line 2 Failed to update database "ReadOn" because the database is read-only.
Opening a different connection, without the Read Scale-Out aka Readable Secondary aka Application Intent Read-Only option, will allow me to do whatever I wanted to do, such as load 10 Row Groups with Clustered Columnstore Index in a new table:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
TRUNCATE TABLE dbo.SampleDataTable;
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
Going back to the read-only connection would allow me to run the query almost instantly:
SELECT COUNT(*) as Result FROM dbo.SampleDataTable ;
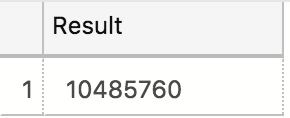
As already previously stated in the advertisement – it just works! ;)
Current Limitations
Right now we do not have access to more than 1 secondary replica and all the juicy additions for the Round Robin or Read-Write intent of SQL Server 2017 & 2019 CTP 2.0 are not supported, since the feature is officially in the preview phase, but I really hope that by the time the feature goes into GA (General Availability) – more and more of the standard Availability Features will become available on Azure SQL Database.
Geo-Replicated Databases
You will need to set up the ReadScale property on each and every single geo-replicated database, in order to avoid the surprises. Otherwise your application might just suddenly stop working after the failover to the other region.
Azure SQL Managed Instance
Because the Azure SQL Managed Instance is a very publicly declared Availability Group, it is explicitly enabled there by default, and the only thing you need to do in order to enable access to it, is to use in your connection string the already above mentioned property ApplicationIntent by assigning to it the value ReadOnly:
ApplicationIntent=ReadOnly;
Final Thoughts
I really hope that the preview will work out well, and that this feature will make it into the final release – thus giving a huge advantage to the PaaS by enabling users to get extra Read performance on the expensive premium editions.
As far as I am concerned, one day it should be enabled by default and heavily promoted so that the Microsoft Azure clients can get the very best on the invested money.
I am also hoping that the full spectrum of the Availability Groups properties will be supported with a possibility to scale out between multiple secondary replicas, use round robin between them and read/write redirection, etc will be supported in the months after the GA, which should hopefully take place in the next couple of months.
Nice Article
Hi
Yes this is gr8, i wrote about it in 2018-7 at my blog in Hebrew (you can click on translate… :))
http://www.sqlazure.co.il/2018/07/load-balance-read-operations-in-sql.html
Great, thank you for sharing!
Niko, Nice article! Would love to see a 2021 update of this article…