More than a year ago, I have started blogging about the Graph Databases at SQL Graph, part I, which besides a lot of drafts – never developed much further, but now with the announced features in SQL Server 2019 CTP 2.0 and Azure SQL Database, it was definitely the time to focus and publish my thoughts about them, because besides being a critic of the feature (because it lacks the necessary investment and features), I am a true believer that if given enough resources the SQL Graph can become relatively fast a major competitor in the world of graph databases (and I promise to lay out my thoughts in one of the upcoming blog posts, until the end of the year).
In the end of September 2018, Microsoft has announced that we are getting a new feature both in Azure SQL Database as well as in the SQL Server 2019 CTP 2.0, the feature that is called the Edge Constraints.
Rarely do I see a feature that has a huge potential that is not getting a major hype
I guess with the surge of all the NoSQL solutions, almost everyone are a kind of on a downer towards any relational feature (especially since NoSQL, might have been called – NotReallyARelationalDatabaseUntilWeNeedAPerformanceAndSQL), but dear readers: this is something that will contribute towards Data Quality (think about at least 80% of your problems) and ultimately performance, I am astonished that the majority of the market is not rejoicing and not celebrating it.
The Edge Constraints
The new constraint type, the Edge Constraints will serve to ensure the quality of the data, when designing the graph schema – for example if you imagine that we have a one-directional relationship between certain types of the nodes(vertices): a Computer(node)->lays on(edge)->a Table(node). We would definitely not want to follow the path in the opposite direction (thus laying table on the computer), unless we would want to destroy it. :)
The Connection Edge
Their definition in the T-SQL language is a very interesting enrichment of the much beloved (and I guess feared) language –
CONSTRAINT [ConstraintName] CONNECTION ([SourceTableName] TO [DestinationTableName])
where as a matter of a fact, the SourceTableName can equals to DestinationTableName as well, since we are using an additional table to connect the reference.
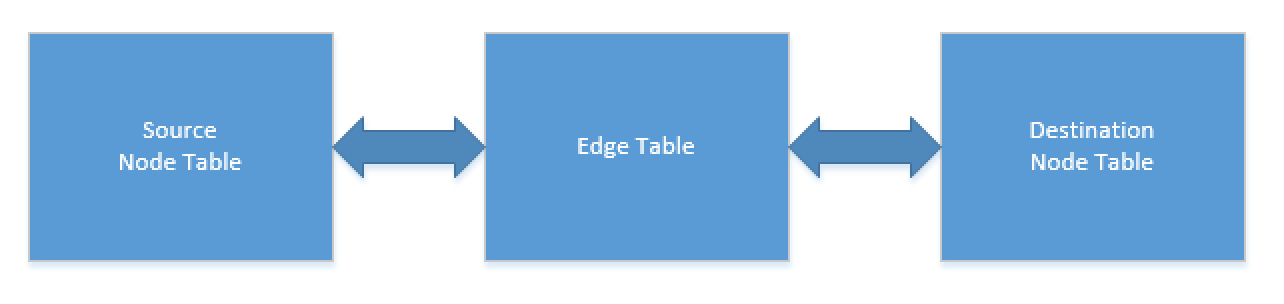 In SQL Server 2017 we only had one model that would allow the bi-directional connection between the nodes, which is as a matter of a fact is not always the desired state. Though one might say, that we could always build the necessary constraints manually, using the traditional foreign keys – it is to note the difficulty of such construction and the easiness of making a wrong step here. From the other side, the rise of the non-relational databases is in part the matter of not wanting/being able to take of data quality and non understanding what it can do for the bottom line of the data extraction and data processing.
In SQL Server 2017 we only had one model that would allow the bi-directional connection between the nodes, which is as a matter of a fact is not always the desired state. Though one might say, that we could always build the necessary constraints manually, using the traditional foreign keys – it is to note the difficulty of such construction and the easiness of making a wrong step here. From the other side, the rise of the non-relational databases is in part the matter of not wanting/being able to take of data quality and non understanding what it can do for the bottom line of the data extraction and data processing.
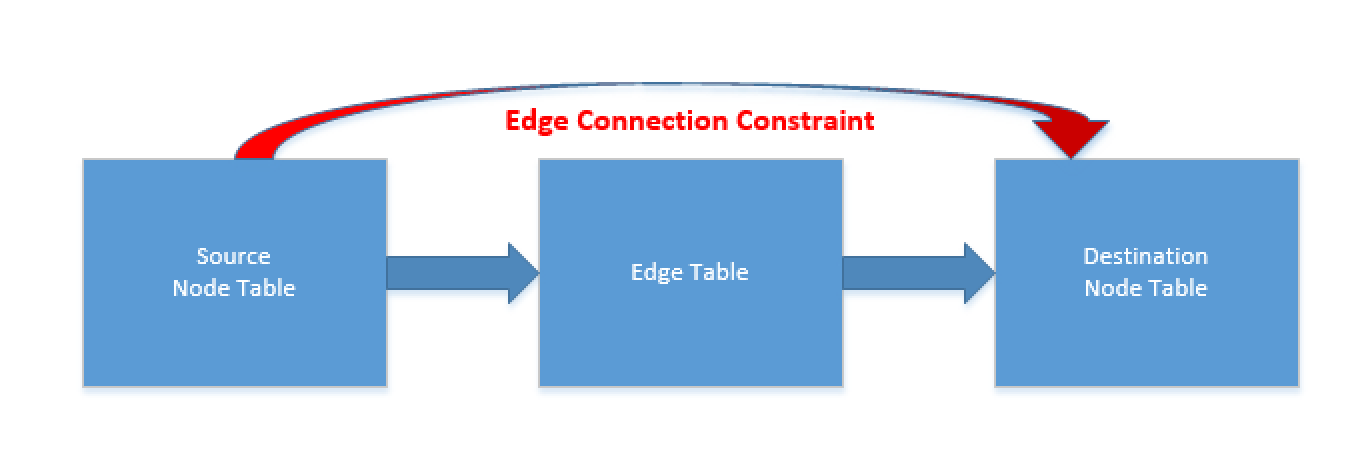 In SQL Server 2019 we can define a directional model, which will point a concrete direction, such as previously mentioned (a book on the table and not a table on the book). Besides guaranteeing a data quality within our database we shall take potentially improve the performance of some of our data processing queries.
In SQL Server 2019 we can define a directional model, which will point a concrete direction, such as previously mentioned (a book on the table and not a table on the book). Besides guaranteeing a data quality within our database we shall take potentially improve the performance of some of our data processing queries.
We can define the Edge Constraint (Connection) inside the edge table definition or inside alter the table command:
CREATE TABLE dbo.SomeTable(
SomeValue TINYINT NULL,
CONSTRAINT EDG_SomeTable CONNECTION (TableA TO TableB)
) AS EDGE;
ALTER TABLE dbo.SomeTable DROP CONSTRAINT EDG_SomeTable;
ALTER TABLE dbo.SomeTable ADD CONSTRAINT EDG_SomeTable CONNECTION (TableA TO TableB);
The possibilities are pretty good and you do not have to define the Edge Connection Constraint between the 2 tables, and so consider the following example of the “self” connection of the Person table that is friends with another person:
DROP TABLE IF EXISTS dbo.FriendsWith;
DROP TABLE IF EXISTS dbo.Person;
CREATE TABLE dbo.Person
(
Id INT NOT NULL identity(1,1) primary key,
FullName NVARCHAR(75) NOT NULL,
Age TINYINT NOT NULL,
) AS NODE;
CREATE TABLE dbo.FriendsWith(
YearsOfFriendship TINYINT NULL,
CONSTRAINT EDG_FriendsWith CONNECTION (Person TO Person)
)
AS EDGE;
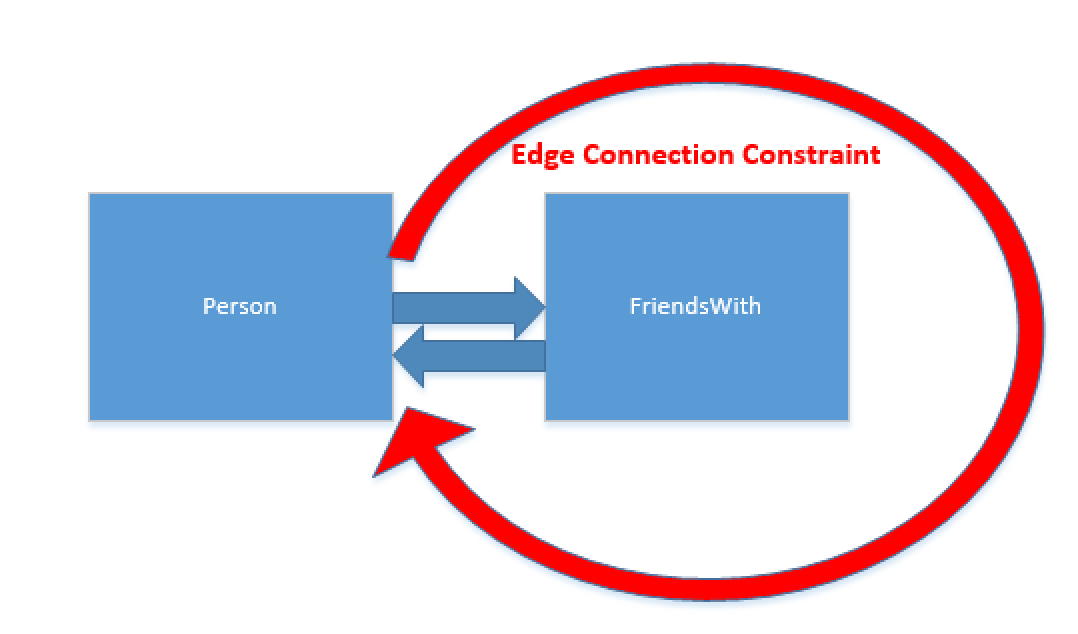 On the left you will find a small picture pointing the schema of our definition.
On the left you will find a small picture pointing the schema of our definition.
It works perfectly, meaning that the T-SQL gives no error for the script execution and that we have successfully guaranteed that a Person can be friendly with another person only.
But what if we determine that a Person can be friends with Pets – can this new type of constraints support this ?
DROP TABLE IF EXISTS dbo.FriendsWith;
DROP TABLE IF EXISTS dbo.Person;
DROP TABLE IF EXISTS dbo.Pet;
CREATE TABLE dbo.Person
(
Id INT NOT NULL identity(1,1) primary key,
FullName NVARCHAR(75) NOT NULL,
Age TINYINT NOT NULL,
) AS NODE;
CREATE TABLE dbo.Pet
(
Id INT NOT NULL identity(1,1) primary key,
PetName NVARCHAR(75) NOT NULL,
Age TINYINT NOT NULL,
) AS NODE;
CREATE TABLE dbo.FriendsWith(
YearsOfFriendship TINYINT NULL,
CONSTRAINT EDG_FriendsWithPerson CONNECTION (Person TO Person),
CONSTRAINT EDG_FriendsWithPet CONNECTION (Person TO Pet),
)
AS EDGE;
Yes, it does!
But please take an important note that what we have defined is that a person in order to be a friend with another person (and actually it can serve as the person being a friend of him/her/themselves) will have to be a friend with a pet :)
As a matter of a fact, we can actually build some ridiculous and even impossible connections if we try, like before Microsoft gives us power, but with that power comes a relatively big responsibility.
Given the logic of the Edge Constraints, I would of course try to create them on a regular (non-edge) table to see if it works, but of course I have faced the problem right away as the script below shows (the dbo.FriendsWith table is not an Edge table in this case):
DROP TABLE IF EXISTS dbo.FriendsWith;
DROP TABLE IF EXISTS dbo.Person;
DROP TABLE IF EXISTS dbo.Pet;
CREATE TABLE dbo.Person
(
Id INT NOT NULL identity(1,1) primary key,
FullName NVARCHAR(75) NOT NULL,
Age TINYINT NOT NULL,
) AS NODE;
CREATE TABLE dbo.Pet
(
Id INT NOT NULL identity(1,1) primary key,
PetName NVARCHAR(75) NOT NULL,
Age TINYINT NOT NULL,
) AS NODE;
CREATE TABLE dbo.FriendsWith(
YearsOfFriendship TINYINT NULL,
CONSTRAINT EDG_FriendsWithPerson CONNECTION (Person TO Person),
CONSTRAINT EDG_FriendsWithPet CONNECTION (Person TO Pet),
);
Msg 13930, Level 16, State 1, Line 19 Edge constraint cannot be created on table 'FriendsWith'. The table is not an edge table. Msg 1750, Level 16, State 0, Line 19 Could not create constraint or index. See previous errors.
I believe, that if we try hard and built all the necessary tables, there must be some trace flag that will allow us to experiment with the tables that are not truly of the Edge type, but this is well beyond the scope of this blog post.
The Meta Data
If we rebuild the last example of the 2 constraints for the friendship between persons with persons and persons with pets – where in the world could we observe the stored metadata ?
Microsoft is providing us currently with the 2 type of the DMVs to see that:
The sys.edge_constraints and the sys.edge_constraint_clauses.
The sys.edge_constraints provides us with the information about which constraints has been defined over the Node & Edge tables:
SELECT OBJECT_NAME(parent_object_id) as ParentObjectIdTable, * FROM sys.edge_constraints;
![]()
and looking at the result you will definitely understand that the shown fields show this constraint to be a heir of the regular constraints, where I could not fit into the picture the columns delete_referral_action & delete_referral_action_desc – which should be pretty much clear to anyone reading this blog.
Regarding the DMV sys.edge_constraint_clauses, this one represents as an extremely valuable one, providing the exact details of the connection, by pointing to the concrete Node tables that are getting connected and thus guaranteeing their data quality:
SELECT OBJECT_NAME(object_id) as ConstraintName, OBJECT_NAME(from_object_id) as NodeFrom, OBJECT_NAME(to_object_id) as NodeTo, clause_number FROM sys.edge_constraint_clauses;

From the picture above, you can clearly see the connections we have established between the Person and Persona as well as between the Person and the Pet tables. Simply and lovely. :)
The only thing I do not understand here is the clause_number value and its importance, but this might have to do with some Query Optimiser things … In any case I am going to try to find out and update this blog in the future.
The Reading Processing Speed
There MIGHT be situations where the Edge Constraint shall improve the reading speed of your graph queries, even though you need to understand that the main goal of the constraints is to guarantee that you get reliable results, that corresponds your expectations and your business situation.
Like in the case of the foreign keys, if you are looking up to verify the existence of the object on the other side of the relationship, the constraints should be able to spare up this work by simply trusting the edge constraint, defined between the respective tables.
The other thing that might happen to you, is that some of the queries that make no sense logically will deliver no results and will do that in a very efficient way – consider the following example of Cities and Countries, where a City is a part of a Country, but not other way around:
DROP TABLE IF EXISTS dbo.IsPartOf;
DROP TABLE IF EXISTS dbo.City;
DROP TABLE IF EXISTS dbo.Country;
CREATE TABLE dbo.City
(
Id INT NOT NULL identity(1,1) primary key,
CityName NVARCHAR(75) NOT NULL,
) AS NODE;
CREATE TABLE dbo.Country
(
Id INT NOT NULL identity(1,1) primary key,
CountryName NVARCHAR(75) NOT NULL
) AS NODE;
CREATE TABLE dbo.IsPartOf(
CONSTRAINT EDG_City_IsPartOf_Country CONNECTION (City TO Country)
) AS EDGE;
INSERT INTO dbo.City
VALUES ('Lisbon'),('Porto'),('Paris'),('London'),('Seattle'),('Lyon');
INSERT INTO dbo.Country
VALUES ('Portugal'),('England'),('France'),('USA');
INSERT INTO dbo.IsPartOf
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Country p2 WHERE CountryName = 'Portugal')
FROM dbo.City p1
WHERE CityName in ('Lisbon','Porto');
INSERT INTO dbo.IsPartOf
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Country p2 WHERE CountryName = 'England')
FROM dbo.City p1
WHERE CityName in ('London');
INSERT INTO dbo.IsPartOf
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Country p2 WHERE CountryName = 'France')
FROM dbo.City p1
WHERE CityName in ('Paris','Lyon');
INSERT INTO dbo.IsPartOf
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Country p2 WHERE CountryName = 'USA')
FROM dbo.City p1
WHERE CityName in ('Seattle');
Counting the number of cities in a given country is an easy task to write in T-SQL for the Graph engine:
SELECT p2.CountryName, COUNT(*) as CitiesCount FROM dbo.City p1, dbo.IsPartOf partOf, dbo.Country p2 WHERE MATCH(p1-(partOf)->p2) GROUP BY p2.CountryName ORDER BY CitiesCount DESC;

That query delivers good results and everything is fine, but if for some reasons (someone is Googling StackOverflow or copypasting with no thinking involved) some query, the logic might get pretty much broken and the request will ask how many cities a country makes part of:
SELECT p2.CityName, COUNT(*) as CitiesCount FROM dbo.Country p1, dbo.IsPartOf partOf, dbo.City p2 WHERE MATCH(p1-(partOf)->p2) GROUP BY p2.CityName ORDER BY CitiesCount DESC;
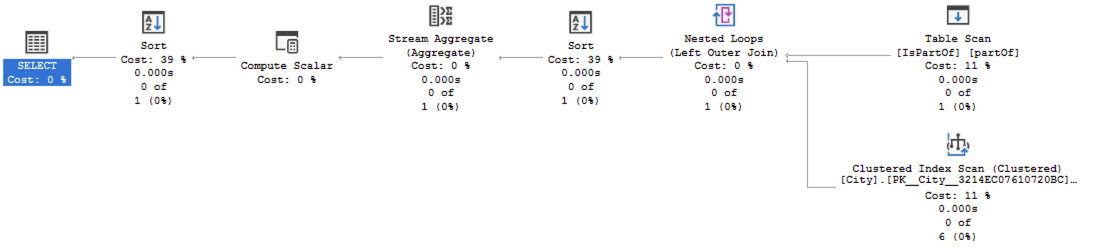
 The answer is pretty logical with no connection available at all, and instead of scanning the tables in the reality and while generating a full blown execution plan, it will use some the object_id of the destination table (dbo.City in my case) and shall produce no rows that will result the execution query to come very fast to an end. This is not the most efficient execution plan, because if we would have millions of the connections and their types, we might have to do a full blown scan in order to determine something that produces no output rows.
The answer is pretty logical with no connection available at all, and instead of scanning the tables in the reality and while generating a full blown execution plan, it will use some the object_id of the destination table (dbo.City in my case) and shall produce no rows that will result the execution query to come very fast to an end. This is not the most efficient execution plan, because if we would have millions of the connections and their types, we might have to do a full blown scan in order to determine something that produces no output rows.
I would like to see some simplification rule that will clearly show that the condition simply disabled the necessity of the running the full execution plan in the future. I mean Query Optimiser can simply scan the Edge Constraints and see if it can quit early, when the query makes no sense.
Improving Data Quality
Inserting data that has no referential source will result in a error message, as expected (and in the example below I am inserting an inverted Country->City relationship:
INSERT INTO dbo.IsPartOf
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.City p2 WHERE CityName in ('London') )
FROM dbo.Country p1
WHERE CountryName = 'England';
The error message will deliver us an understandable statement, referring to the Edge Connection Constraint, that is a part of the dbo.IsPartOf table:
Msg 547, Level 16, State 0, Line 1 The INSERT statement conflicted with the EDGE constraint "EDG_City_IsPartOf_Country". The conflict occurred in database "Test", table "dbo.IsPartOf". The statement has been terminated.
Like with any relational schema we have a full control & responsibility of how data will look like and what it will mean.
Improving Consistency
Like with any other constraints, the existence of the Edge Constraint will prevent the source table(node) to get truncated:
TRUNCATE TABLE dbo.Person;
Will generate the following error message:
Msg 13944, Level 16, State 1, Line 1 Cannot truncate table 'dbo.Person' because it is being referenced by an EDGE constraint.
And an attempt to delete a node that is connected with a different node through the Edge Constraint will result in an error message as well:
DELETE FROM dbo.City WHERE CityName = 'Lyon'

Msg 547, Level 16, State 0, Line 4 The DELETE statement conflicted with the EDGE REFERENCE constraint "EDG_City_IsPartOf_Country". The conflict occurred in database "Test", table "dbo.IsPartOf". The statement has been terminated.
SSMS and Dependencies
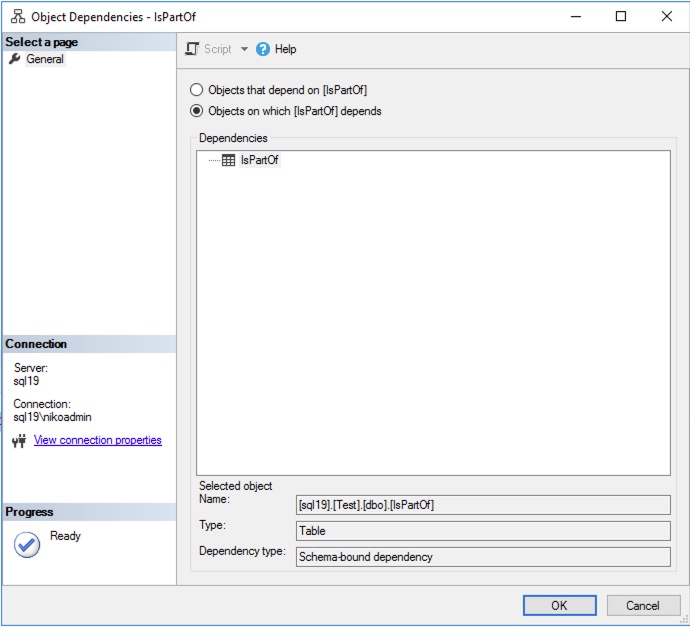 I understand that this is an early public CTP (2.0) of the SQL Server 2019, but the lack of the dependencies that are shown in SQL Server Management Studio is a bit that I definitely would love to see fixed before the RTM (final release). A lot of people I know are using this and I can only assume that the development team simply has not had a chance to add the edge constraints to the respective DMVs. This is a very needed area, because for the application that are doing a lot with an automation, a central piece to discover all dependencies is essential.
I understand that this is an early public CTP (2.0) of the SQL Server 2019, but the lack of the dependencies that are shown in SQL Server Management Studio is a bit that I definitely would love to see fixed before the RTM (final release). A lot of people I know are using this and I can only assume that the development team simply has not had a chance to add the edge constraints to the respective DMVs. This is a very needed area, because for the application that are doing a lot with an automation, a central piece to discover all dependencies is essential.
Final Thoughts
More, we need more improvements – the graph engine is starting to look more promising, but there is a need for the high quality improvements that will enable people to run some graph analysis within a couple of easy-writable statements!
I love constraints – guaranteeing the rules of the business will solve and avoid so many unwanted consequences!
Even artistically speaking, the Constraints existence inspires us to go further and to challenge the status quo.
Unfortunately many other engines that do not understand the principles of the data quality simply ignore the importance of the good data. This is one of the location where I see Graph within SQL Server and Azure SQL Database can establish its space in the future.
There is also a lot of space for the Query Optimiser improvements in the execution plans in order to distinguish itself from the concurrence.
to be continued …
Hi Niko,
Lovely series on graphs!
Regarding the clause number in this article, when you define multiple from, to pairs on a single edge constraint, like for instance in:
CREATE TABLE dbo.FriendsWith(
YearsOfFriendship TINYINT NULL,
CONSTRAINT EDG_Friends CONNECTION (Person TO Person, Person To Pet)
)
AS EDGE;
Then the metadata query will return two rows for the same edge with clause_number 1 and 2