Continuation from the previous 121 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
First of all, I would love to express deep gratitude to Vassilis Papadimos (Software Engineer @ Microsoft) and Joe Sack (Principal Program Manager @ Microsoft) for helping me out with some of the details on the wait types.
If there are any errors in the information below – they are fully mine and have to do with the interpretation of the information.
If there are missing wait types (I do not pretend to have a complete list here), please indicate and I will investigate and add them to this post.
This post was originally scheduled to be published in 2016 and I had a draft written, but then Paul Randal announced that he was creating and maintaining the Wait Types Library, where his intention is to keep it up to date as possible. I decided to back off, but given that the number of questions that I received does not get lower with the time, I decided to provide my own point of reference, that I can share with everyone interested in this matter.
These are the wait types that are known to me (some of them are available since SQL Server 2012, some are from SQL Server 2014 and some are really late bloomers – they are to be found in SQL Server 2016 and later versions):
HTBUILD
HTDELETE
HTMEMO
HTREINIT
HTREPARTITION
BPSORT
PWAIT_QRY_BPMEMORY
ROWGROUP_VERSION
ROWGROUP_OP_STATS
SHARED_DELTASTORE_CREATION
COLUMNSTORE_BUILD_THROTTLE
COLUMNSTORE_MIGRATION_BACKGROUND_TASK
COLUMNSTORE_COLUMNDATASET_SESSION_LIST
I split the known wait types into the following distinct groups:
– Batch Execution Mode (HTBUILD, HTDELETE, HTMEMO, HTREINIT, HTREPARTITION, PWAIT_QRY_BPMEMORY, BPSORT)
– Columnstore Indexes (ROWGROUP_VERSION, ROWGROUP_OP_STATS, SHARED_DELTASTORE_CREATION, COLUMNSTORE_BUILD_THROTTLE, COLUMNSTORE_MIGRATION_BACKGROUND_TASK, COLUMNSTORE_COLUMNDATASET_SESSION_LIST)
With an appearance in the next SQL Server version of the Batch Execution Mode for the RowStore Indexes, the first group of the waits will suddenly be becoming more important for every single SQL Server user and mixing it together with the Wait Types specific to the internal structures and functions of the Columnstore Indexes makes no sense.
I will try to go into the details of each of the Wait Types, reproducing scenarios where possible.
SETUP
Once again I took the good old ContosoRetailDW free database from Microsoft
My Data & Log files are configured to be restored to the following path on this test instance: c:\Data\, with the Backup file to be found at C:\Install folder:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\SQL16\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\SQL16\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Now, let’s go the things that really matter in this blog post – the Wait Types for the Columnstore Indexes and the Batch Execution Mode:
HTBUILD
Type: Batch Mode
Since: SQL Server 2012
This wait type is related to the process of the building of the Hash Table, which takes place during the hash operations (Hash Joins, Hash Aggregate, …). The time that is spent on building and making available for every thread of the Hash Table is set as wait time for all of the other threads. This type of wait will be a regular companion of any execution plans that involves hashing operation and more threads you have, the more time your wait stats will record.
In SQL Server 2012, each of the threads has its own copy of the hash table, which was great for the performance, but ultimately was blowing the amount of required and used operational memory. In SQL Server 2014 this was changed and so now we have one single table that is shared between all working threads, which improves memory usage by lowering the overall consumption by the cost of introducing a small delay.
Look at this operation as an exposure of what is going on internally, but this wait type is not something that you can truly influence, besides working on the distribution of the rows between the threads in the execution plan. This wait will show you how much skew there was between threads in the execution plan and you might be able to see lower numbers for the waits (and most probably for the overall execution time as well), if you lower the DOP (degree of parallelism).
One of the simplest example would be a simple query I ran agains the FactOnlineSales table in the ContosoRetailDW database (Notice that I have Threshold for Parallelism set on 5):
SELECT StoreKey, SUM(t1.UnitCost - t1.UnitPrice) *- 1.23 FROM [dbo].FactOnlineSales t1 GROUP BY StoreKey;
Here is the parallel execution plan that I have received:

 And lucky me, the only wait type I have got was HTBUILD with the details you can see on the picture on the left. The wait time in insignificant – just 44 Milliseconds but you will not have exact details in which iterators it took place and how it was distributed. What you can do is guessing that because there were 14 wait counts, they were distributed between 2 iterators with each one having 7 out of 8 threads waiting.
And lucky me, the only wait type I have got was HTBUILD with the details you can see on the picture on the left. The wait time in insignificant – just 44 Milliseconds but you will not have exact details in which iterators it took place and how it was distributed. What you can do is guessing that because there were 14 wait counts, they were distributed between 2 iterators with each one having 7 out of 8 threads waiting.
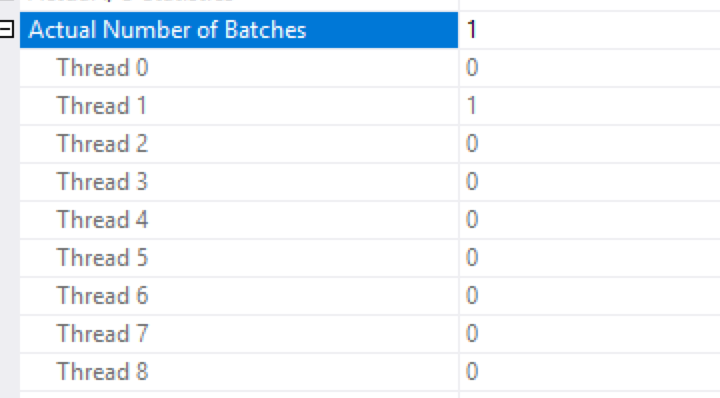 To confirm this suspicion, on the right side of this text you can see the distribution of the rows between the threads and how it causes is easy to guess & confirm.
To confirm this suspicion, on the right side of this text you can see the distribution of the rows between the threads and how it causes is easy to guess & confirm.
HTDELETE
Type: Batch Mode
Since: SQL Server 2014
This wait type is related to the process of the removing of the Hash Table, which takes place at the end of the hash operations (Hash Joins, Hash Aggregate, …). The time that is spent on removing the shared hash table while every thread is waiting for the operation end is marked as wait time. This type of wait will be a regular companion of any execution plans that involves hashing operation and more threads and skew between their work you have, the more time your wait stats will record.
If there is a big skew between the number of the rows of the threads, the threads with lower number of rows will finish their work first, waiting for the threads with bigger work to finalise and to remove the respective shared Hash Table. This time is recorded as the HTDELETE, the amount of time that the threads are waiting for the whole task to finish.
Keeping your statistics up to date, keeping all delta-stores closed and compress them to the compressed Row Groups, helping query optimiser to find a better execution plan are some of the techniques that can be applied in order to get the rows.
I am also expecting Microsoft to get some improvements in the Query Optimiser in the next versions, the parallelism in the Columnstore Indexes and the Batch Execution Mode is one of the places where the improvement are very welcome. :)
For the demo here is a simple Query, which counts the number of the Sales Entries that have SalesAmount below average for the FactOnlineSales table:
SELECT COUNT(*) FROM [dbo].FactOnlineSales t1 WHERE SalesAmount < (SELECT AVG(t2.SalesAmount) FROM dbo.FactOnlineSales t2);
The actual execution plan can be found below:

 And you can see that besides the already known suspect, the HTBUILD wait type we have the HTDELETE and also one of the below mentioned wait type - PWAIT_QRY_BPMEMORY. In my experience, most of the time if we have a huge number of entries in the hash table, the HTDELETE will be by far the biggest of the Batch Mode Waits and there is not really much what can be done against it.
And you can see that besides the already known suspect, the HTBUILD wait type we have the HTDELETE and also one of the below mentioned wait type - PWAIT_QRY_BPMEMORY. In my experience, most of the time if we have a huge number of entries in the hash table, the HTDELETE will be by far the biggest of the Batch Mode Waits and there is not really much what can be done against it.
HTMEMO
Type: Batch Mode
Since: SQL Server 2014
This wait type is related to the synchronization point used before scanning a Hash Table to output found matching or non-matching rows.
This is the type that you will see in a lot of execution plans with Batch Mode that are using hashing functionality (Hash Joins, Hash Aggregate, …), but besides rather simple observation there are not many things that can be done. In my experience I have not faced an high values with this wait type and I would expect only implementation problems to cause a really high number of this wait type.
HTREINIT
Type: Batch Mode
Since: SQL Server 2014
This wait type is related to the process of the synchronization point used during or at the end of scanning Hash Table to output found matching or non-matching rows.
Since this is an implementation-specific wait type and its functionality is not really available for the outside influence, this is one of the wait types that we can observe and it might tell us how efficient the used algorithm is, but it does not look like something that can be easily influenced.
HTREPARTITION
Type: Batch Mode
Since: SQL Server 2012
This wait type is related to the time, accumulated during synchronization point, used after build side re-partitioning in the Hash Match (Aggregate) iterator. The build side is the part of the process where we build shared Hash Table, the part of the process where we compare the data with the one stored in the hash table is called the probe.
I am thinking about this wait type in the terms of the Streams Repartitioning as in the execution plans. The synchronisation process is something that will most probably never made public and it is not the type of wait that you will care about, unless there is a huge bug - and your solution will be to patch SQL Server.
Again, being an internal synchronisation process, there is not much that can be done.
An understandable example is below, where I first remove the Foreign Key between FactOnlineSales and the DimPromotion tables:
ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]
Lets count the distinct CustomerKey that are stored in the FactOnlineSales table with a correct connection to the DimPromotion dimension:
SELECT CustomerKey, COUNT(*) FROM [dbo].FactOnlineSales t1 INNER JOIN dbo.DimPromotion prom ON t1.PromotionKey = prom.PromotionKey GROUP BY t1.CustomerKey ORDER BY t1.CustomerKey;
The execution plan is presented below:

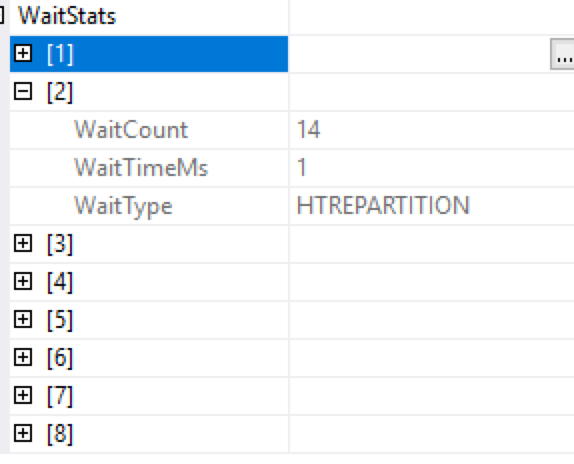 You can see that there were 2 iterators (there are 14 Wait Counts that are split between 2 iterators with 7 waiting threads in each case) and that we have 2 Hash Math Aggregate iterators), that have caused the wait time through the usage of the synchronisation point.
You can see that there were 2 iterators (there are 14 Wait Counts that are split between 2 iterators with 7 waiting threads in each case) and that we have 2 Hash Math Aggregate iterators), that have caused the wait time through the usage of the synchronisation point.
In the end, please add the Foreign Key back to the FactOnlineSales table, so that the other demos would continue functioning correctly:
ALTER TABLE [dbo].[FactOnlineSales] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSales_DimPromotion] FOREIGN KEY([PromotionKey]) REFERENCES [dbo].[DimPromotion] ([PromotionKey]) GO ALTER TABLE [dbo].[FactOnlineSales] CHECK CONSTRAINT [FK_FactOnlineSales_DimPromotion] GO
BPSORT
Type: Batch Mode
Since: SQL Server 2016
This wait type is related to the Batch Mode Sort operations, available as Full Sort or Top Sort iterators. This wait type takes place when the output stream is waiting for the sorting streams to deliver the result of their work, and as with the most Batch Mode wait types, it will have to do with with row skew between the worker threads - thus unbalanced work distribution can have a more detailed pinpoint to the specific place in the execution plan - the sort iterator.
If this wait type is causing you huge problems, consider using Trace Flags 4199, 9347 and 9349, but under the risk of not having Batch Mode advantages. The ever interesting Trace Flag 9358 will provide you with additional memory, but there has been some side effects I guess, that this Trace Flag still did not made into the default configuration or user hint table.
Statistics is one of your best friends to battle this kind of problems, or helping Query Optimiser to find a more effective execution plan is one of the alternative paths that you can follow.
Here is a simple query joining table FactOnlineSales with DimPromotion table and sorting the results on the PromotionCategory
SELECT prom.PromotionCategory, COUNT(*) FROM [dbo].FactOnlineSales t1 INNER JOIN dbo.DimPromotion prom ON t1.PromotionKey = prom.PromotionKey GROUP BY prom.PromotionCategory ORDER BY prom.PromotionCategory;

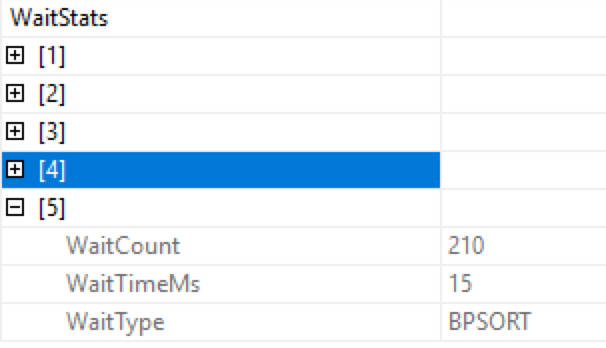 The details of the sort iterator can be pretty important and in this concrete case we see 210 ms of the wait time, but in some cases this value might jump to quite high numbers - when the skewing of the rows between the threads are extremely different, so you better watch out. :)
The details of the sort iterator can be pretty important and in this concrete case we see 210 ms of the wait time, but in some cases this value might jump to quite high numbers - when the skewing of the rows between the threads are extremely different, so you better watch out. :)
PWAIT_QRY_BPMEMORY
Type: Batch Mode
Since: SQL Server 2012
This wait type is related to the Batch Mode memory operations. To my current understanding it reflects the amount of time that the query waits until the Memory is given to the Batch Mode operations.
ROWGROUP_VERSION
Type: Columnstore Indexes
Since: 2016
The ROWGROUP_VERSION wait type is about coordinating access to previous versions of columnstore Row Groups (e.g. when a deltastore gets compressed while a snapshot transaction is active, subsequent queries in that transaction need to keep accessing the Delta-Store, not the compressed Row Group).
This wait type is observable when we deal a lot of with a trickle loading (non Bulk-Load API) while using Snapshot Isolation level. Always On Availability Groups Secondary Replicas is one of the candidates to observe this type of wait, because this is where the isolation level is mapped to the Snapshot automatically.
Avoiding using the Snapshot Isolation Level where possible, or using Bulk Load API are some of the ways to solve this wait type.
ROWGROUP_OP_STATS
Type: Columnstore Indexes
Since: 2014
This wait type is associated with looking up row group metadata stats given a Row Group id. It accumulates the value for different lock types (acquiring read and write lock for stats – either just to read or read/write).
This is one of the most insignificant wait types for the typical users and it will appear mostly in the very busy environments or in the tables with billions of rows, where the Row Groups are in the largest thousands. This is another wait type which is useful for the developers but can't really help those ones who are trying to tune performance - because it simply exposes the way of the current implementation.
SHARED_DELTASTORE_CREATION
Type: Columnstore Indexes
Since: 2016
This wait is related to the waiting time of the new shared Delta-Store creation. Sometimes multiple threads will be a helping each other and once one thread has created a Delta-Store and the other thread can take advantage of it, the time that the non-creative thread spent waiting for the creator-thread to create the Delta-Store is recorded as the SHARED_DELTASTORE_CREATION wait type.
This wait type is observable when we deal a lot of with a trickle loading (non Bulk-Load API), and most typically Nonclustered Columnstore Indexes will be the ones that will cause it - they are the secondary indexes and their functionality will be more frequently associated with this type of data loading.
COLUMNSTORE_BUILD_THROTTLE
Type: Columnstore Indexes
Since: 2014
This wait type takes place during Columnstore Index build/rebuild process, mainly because the first thread will determine the amount of memory and possible respective number of threads that will be working on the index building. All requested threads will be waiting for the first thread to finish and that’s first part of the wait. If there is not enough memory available, then the number of threads will be reduced and the other threads will be also contributing to the sum of the wait time.
Think about this wait type and correlating Extended Event - column_store_index_build_throttle, on which you can find detailed information at the Columnstore Indexes – part 47 ("Practical Monitoring with Extended Events") blogpost.
This wait will kick in when either Memory Pressure or Dictionary Pressure take place.
Increasing the amount of the available memory (through Resource Governor or adding to the instance and avoiding usage of the String columns are the good ways to improve the overall performance and getting rid of this wait type).
To test the example, let's create a table that will suffer from the dictionary pressure and which Row Groups will be trimmed quite significantly (under 90.000 rows as a matter of fact):
DROP TABLE IF EXISTS dbo.t_colstore;
CREATE TABLE dbo.t_colstore (
c1 int NOT NULL,
c2 INT NOT NULL,
c3 char(40) NOT NULL,
c4 char(800) NOT NULL
);
set nocount on
declare @outerloop int = 0
declare @i int = 0
while (@outerloop < 1100000)
begin
Select @i = 0
begin tran
while (@i < 2000)
begin
insert t_colstore values (@i + @outerloop, @i + @outerloop, 'a',
concat (CONVERT(varchar, @i + @outerloop), (replicate ('b', 750))))
set @i += 1;
end
commit
set @outerloop = @outerloop + @i
set @i = 0
end
go
As the next step, enable the actual execution plan and create the Clustered Columnstore Index:
-- Creates Clustered Columnstore Index CREATE CLUSTERED COLUMNSTORE INDEX t_colstore_cci ON dbo.t_colstore;

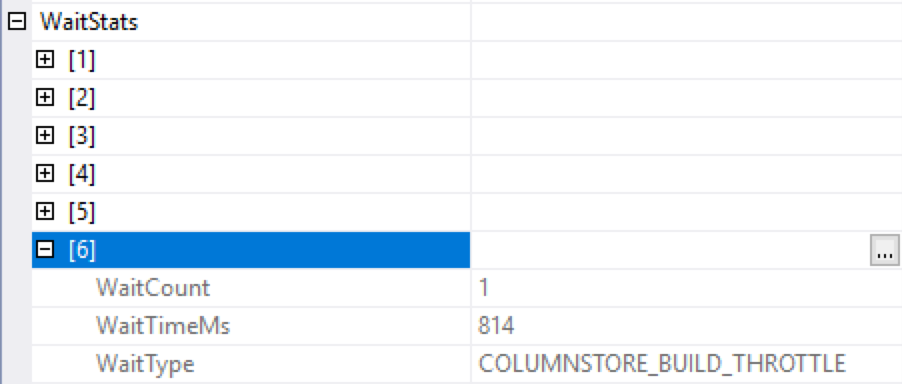 After selecting the execution plan properties (or selecting the INSERT iterator and right clicking on the Properties), you should be able to navigate to the WaitStats property (if you are running SQL Server version that supports it) and see that one of the available Wait Types is COLUMNSTORE_BUILD_THROTTLE, meaning that in my particular case around 0.8 seconds were spend waiting for the trimming operation that is decided by the first thread. There are not many things that one can do in this case, besides redesigning the table and taking out the String column out of the destination table.
After selecting the execution plan properties (or selecting the INSERT iterator and right clicking on the Properties), you should be able to navigate to the WaitStats property (if you are running SQL Server version that supports it) and see that one of the available Wait Types is COLUMNSTORE_BUILD_THROTTLE, meaning that in my particular case around 0.8 seconds were spend waiting for the trimming operation that is decided by the first thread. There are not many things that one can do in this case, besides redesigning the table and taking out the String column out of the destination table.
For the Memory Pressure the proceeding are similar, you will get to observe the results with the COLUMNSTORE_BUILD_THROTTLE result,
and for this purpose I have forced the Resource Governor into a significant suffering, by cutting the amount of the available memory 10 times to just 10%,
and PLEASE JUST DO SUCH TEST AT THE DEVELOPMENT MACHINE:
ALTER RESOURCE POOL [default] WITH( max_memory_percent=10, AFFINITY SCHEDULER = AUTO ); GO ALTER RESOURCE GOVERNOR RECONFIGURE; GO
Now, let's rebuild a FactOnlineSales table from the ContosoRetailDW demo database (notice that originally I have had 14GB set for my SQL Server 2017 instance):
USE ContosoRetailDW; alter table dbo.FactOnlineSales rebuild;

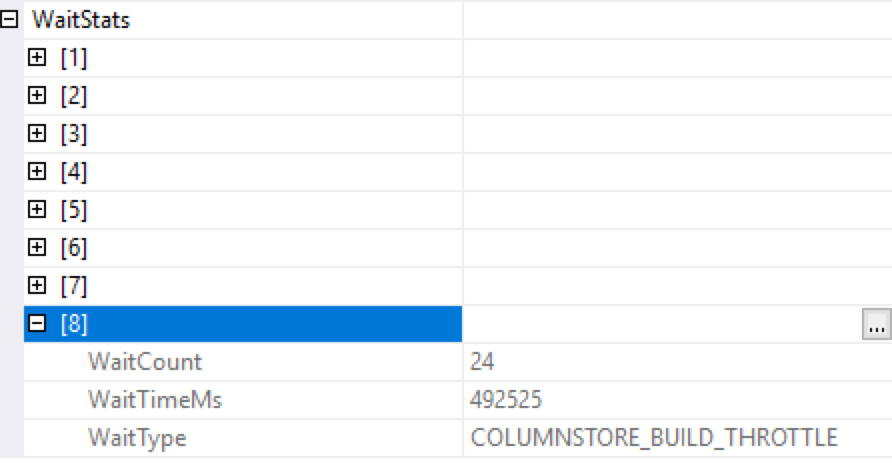 In this case the amount of wasted time was significantly bigger - we have whole 492 seconds (that in the end should be divided between 8 cores I have assigned to this VM), but still you will find this number extremely high and that's what definitely should be worked on in this case - the amount of available memory.
In this case the amount of wasted time was significantly bigger - we have whole 492 seconds (that in the end should be divided between 8 cores I have assigned to this VM), but still you will find this number extremely high and that's what definitely should be worked on in this case - the amount of available memory.
In the end, do not forget to reset the default group max memory percent back to where it was (in my case 100%):
ALTER RESOURCE POOL [default] WITH( max_memory_percent=100, AFFINITY SCHEDULER = AUTO ); GO ALTER RESOURCE GOVERNOR RECONFIGURE; GO
COLUMNSTORE_MIGRATION_BACKGROUND_TASK
Type: Columnstore Indexes
Since: 2016
This wait type is related to the Tuple Mover and calculates some of the metrics related to this background process functioning (Row Group Migration process that will be from Delta-Store to Row Group and from logically fragmented or small compressed Row Group to a self-merge or intergroup merge operations).
You will not find this wait type for your query execution but it will be available on the server (on the database in the Azure SQL Database) level.
This wait type is useful to determine if the Tuple Mover should be disabled (Trace Flag 634).
COLUMNSTORE_COLUMNDATASET_SESSION_LIST
Type: Columnstore Indexes
Since: 2016
This wait type is a unicorn - it exists on the list of the types, but apparently nobody has seen it in the wild.
This might be one of those features that were worked on and then abandoned for the time being.
Final Thoughts
This is most probably by far not a complete list of the Columnstore Indexes & Batch Mode wait types, but it should provide you with a good start. :)
to be continued with Columnstore Indexes – part 123 ("Clustered Columnstore Index Online Rebuild")