Continuation from the previous 109 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
In this blog post I wanted to share my thoughts & my script that I am using for picking the best column for achieving the best possible Segment Elimination for the queries with predicates against the tables with Columnstore Indexes.
Given that I constantly blog on the matter of the Segment Elimination (Columnstore Indexes – part 34 (“Deleted Segments Elimination”), Columnstore Indexes – part 29 (“Data Loading for Better Segment Elimination”), Columnstore Indexes – part 36 (“Maintenance Solutions for Columnstore”) & of course Columnstore Indexes – part 57 (“Segment Alignment Maintenance”)), I thought that the next step in automation of the decision is needed and this blog post is about this functionality that is already a part of the upcoming CISL release 1.5.0. While it is disabled by default (you will not want to scan a TB of the memory every time you check on the ), you can and you should run it during the maintenance windows, in order to understand how can you get even a better performance.
There are 3 important factors that I use for the determination of the column that is really good for the Segment Elimination and hence the Segment Alignment:
– The support for the Segment Elimination (and then for the Predicate Pushdown). If the data type does not support Segment Elimination, than why would someone optimise for it ?
– The frequency with which the column is used in the predicates (not in the joins, because this is where generally the Segment Elimination/Predicate Pushdown does not function because of the way too generous overlapping of the values)
– The number of the distinct values within a table/partition (if we have more Segments than distinct values, it is not a very good sign generally: example – 10 million rows with 5 distinct values)
Based on this factors, the the algorithm that I am using is using the following logic:
– Identify each column if it supports the Segment Elimination
– Discover the number of distinct values for each of the columns in the table/partition and assign the values between 1 & 100, based on the percentage of the distinct values to the total number of values.
– Scan the execution plans in the SQL Server memory, determining the used predicates against Columnstore tables and the frequency that this column is being used.
– Based on the achieved frequency of the predicates, the ranking between 1 and 100 will be distributed between all columns of the table/partition.
– The final score is a sum of the Segment Elimination support (-1000. if it is not supported), Percentage of the Distinct Values and the Frequency of the Memory Scans. There are some other smaller improvements in the formula, but the basics is this one.
Now, as I am writing the blog post, the script for every single factor is already live at the CISL getAlignment function.
The new parameters in the cstore_GetAlignment stored procedure are:
@showSegmentAnalysis BIT = 0, — Allows showing the overall recommendation for aligning order for each table/partition
@countDistinctValues BIT = 0, — Allows showing the number of distinct values within the segments, the percentage related to the total number of the rows within table/partition (@countDistinctValues)
@scanExecutionPlans BIT = 0, — Allows showing the frequency of the column usage as predicates during querying (@scanExecutionPlans), which results is included in the overall recommendation for segment elimination
The default returned columns of the stored procedure suffered just 1 major change and a smaller change from the 1.4.x version, with a new column representing the support of the Predicate Pushdown support and the [Segment Elimination]Â column has a shorter description from “Segment Elimination is not supported” to simply “not supported”.
The interesting things will start happening once we start using those parameters and for this purpose I will use freshly restored ContosoRetailDW database on the RC1 of the SQL Server 2017:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
After successfully installing the latest & the greatest 1.5.0 (pre-release) version of the SQL Server 2017 cstore_getAlignment function, I will be able to execute it, using the brand new (1.5 branch) parameter @preciseSearch, that will allow me to identify the table exactly by its name (without like ‘%’ + @tableName + ‘%’ search):
exec dbo.cstore_GetAlignment @tableName = 'FactOnlineSales', @preciseSearch = 1;
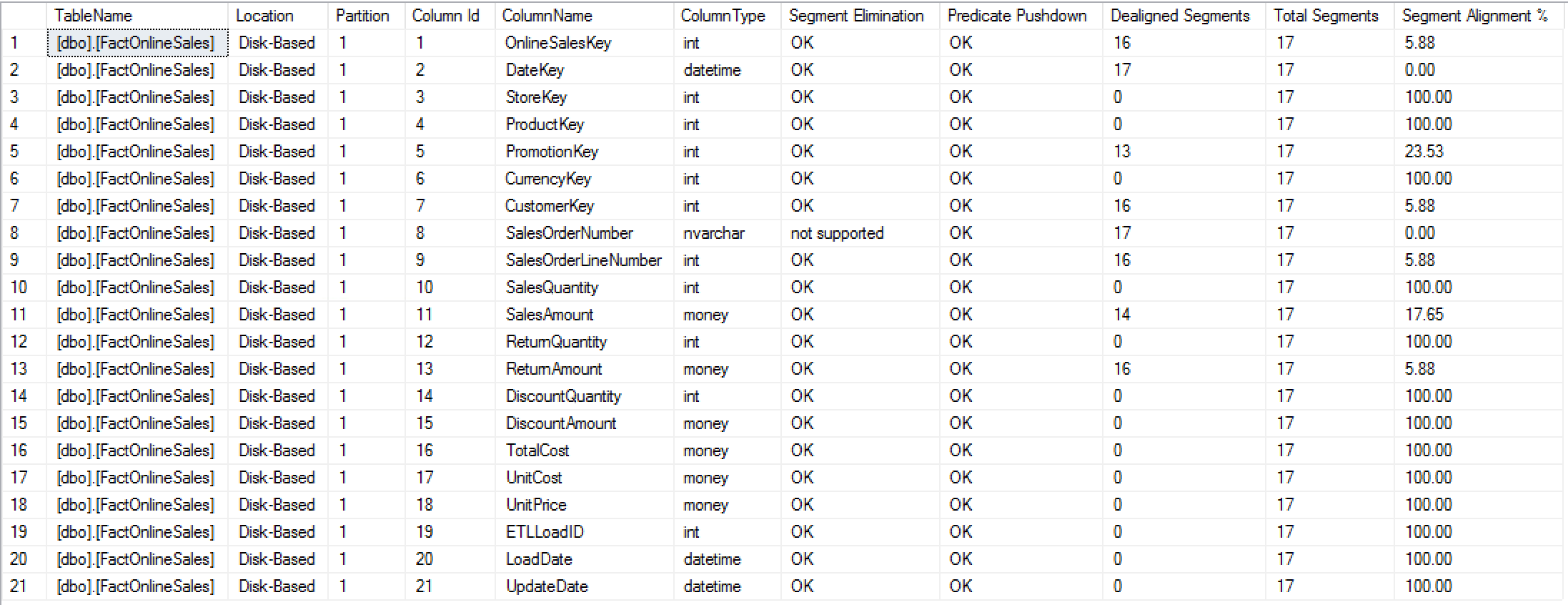
With the default output you can see the information about all columns alignment like before, but in the current version you can also see the information on the [Predicate Pushdown]Â support.
Distinct Counts
If we want to discover the number of distinct values within our table/partition, we need to activate the @showSegmentAnalysis parameter together with the @countDistinctValues parameter:
exec dbo.cstore_GetAlignment @tableName = 'FactOnlineSales', @preciseSearch = 1,
@showSegmentAnalysis = 1, @countDistinctValues = 1;
BE VERY CAREFUL HERE! This will auto-generate code for counting the distinct values for each of the columns of the table, in 1 single statement, firing it immediately against every single searched table (and all of the columnstore tables if nothing is specified for the @tableName parameter):
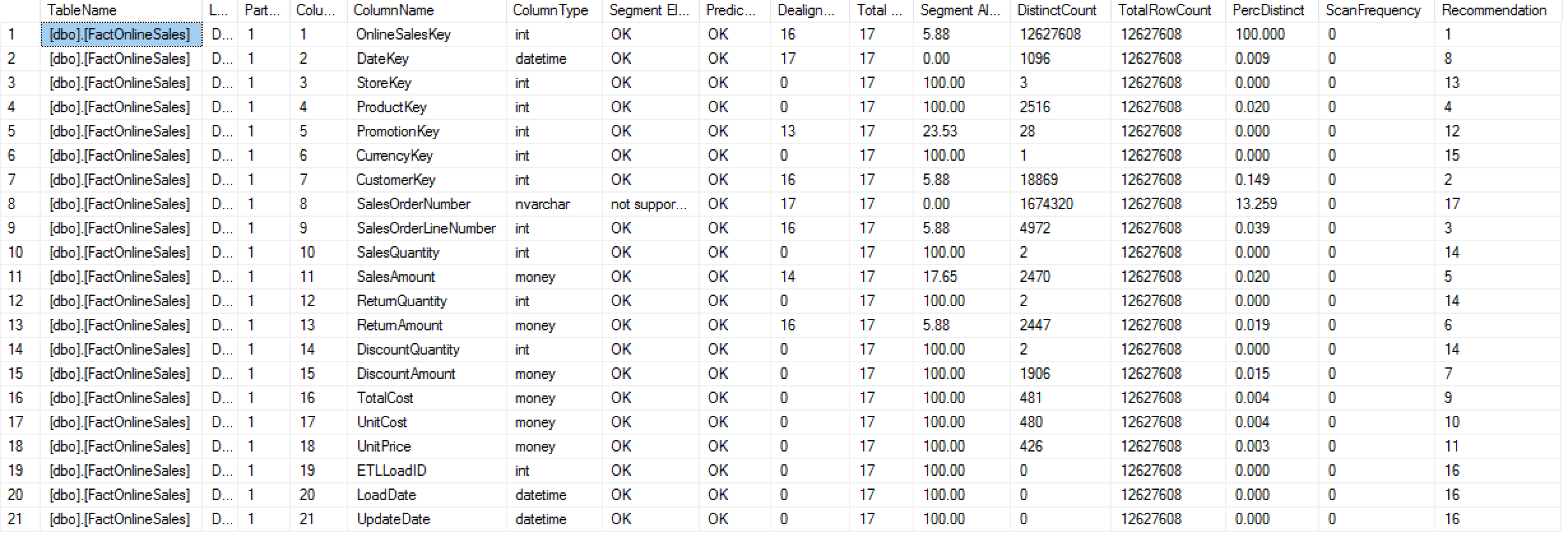
As you can see on the image above, after the regular columns ending with [Segment Alignment], we have 5 new columns:
– [Distinct Count] with the distinct count for the values of the respective column
– [Total Row Count] with the total number of rows within a table/partition
– [Perc Distinct]Â with the percentage that the distinct values represent in the relation to the total number of rows within a table/partition
– [Scan Frequency] – let us ignore this one for the time being
– [Recomemndation]Â – the order of the recommendation for the column for the table/partition based on the sampled information and the parameters
Based on the current test results, you can see that the column with the most distinct values is the [OnlineSalesKey], followed by the [SalesOrderNumber], but the respective recommendations for each of them represent [1] and [17] positions because as the matter of the fact, the [SalesOrderNumber]Â consists of the data type NVARCHAR, which does not support Segment Elimination and hence was automatically downrated even though it contains the second most distinct number of values.
I want to stress that using this functionality on the tables with billions of rows and hundreds of the columns (Fact Tables for example), might take a lot of time (especially since the values will be calculated and aggregated on the partition basis) – and you better run this script during the maintenance window, when no user will get affected.
Execution Plan Predicates Scan
Now, there is another parameter that have not been used previously, which is @scanExecutionPlans – when activating this parameter together with the @showSegmentAnalysis (which is required for using of the analytical & suggestions capabilities of the store_getAlignement Stored Procedure).
Before running it against our ‘FactOnlineSales’ table let’s execute a couple of queries, generating the 2 predicate searches for the [SalesQuantity] column and 1 predicate search for the [DisctounQuantity] column:
SELECT SUM(SalesAmount) FROM dbo.FactOnlineSales WHERE SalesQuantity < 10; SELECT SUM(SalesAmount) FROM dbo.FactOnlineSales WHERE DiscountQuantity < 10 AND SalesQuantity < 10;
Now, let's execute the script searching within the execution plans for the recommendation on the column usage for our table:
exec dbo.cstore_GetAlignment @tableName = 'FactOnlineSales', @preciseSearch = 1,
@showSegmentAnalysis = 1, @scanExecutionPlans = 1;
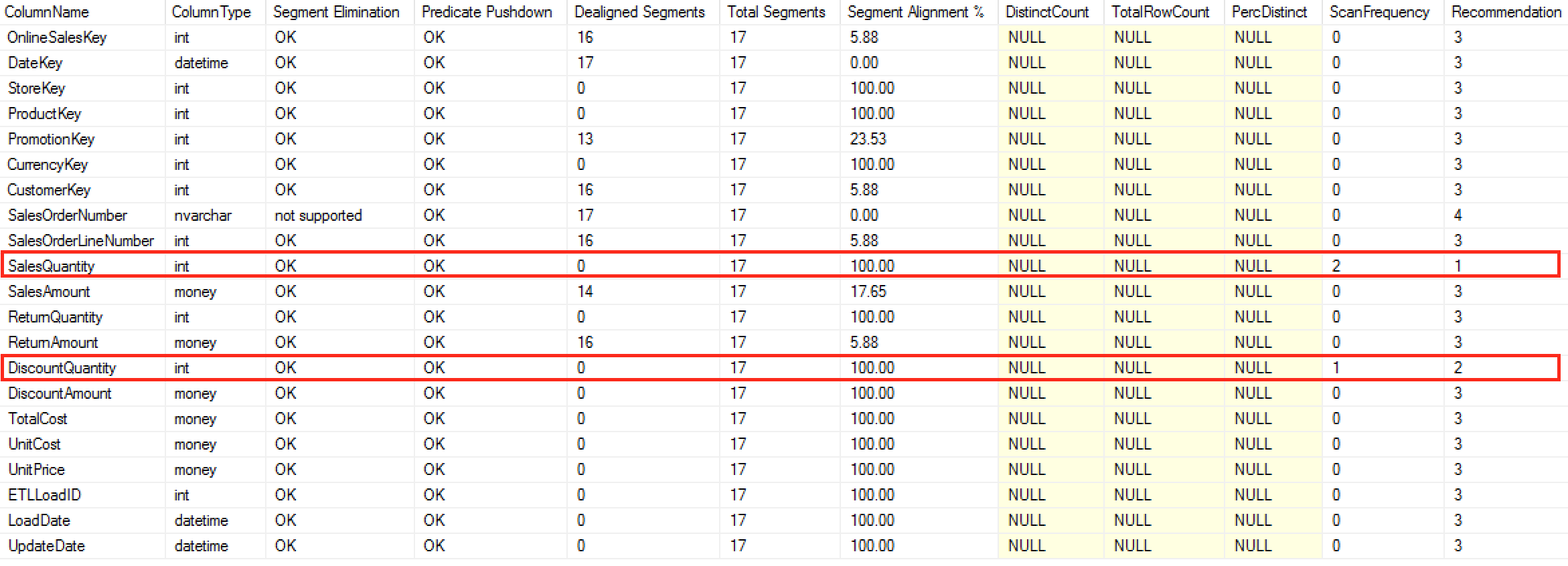
On the results screen you can see both of the columns used for the predicates, marked with red rectangles, that will help to identify the number 1 and the number 2 recommendations for the Segment Alignment.
With this execution we focus only on the executions, totally ignoring the diversity of the values within our table/partition.
Notice that depending on the amount of available memory and the number & complexity of the execution plans, the search might take a significant time. Once again, please use it against the Test/Q&A instances first, before advancing to the Production and run this script during the maintenance window, so that the users won't be affected.
All together
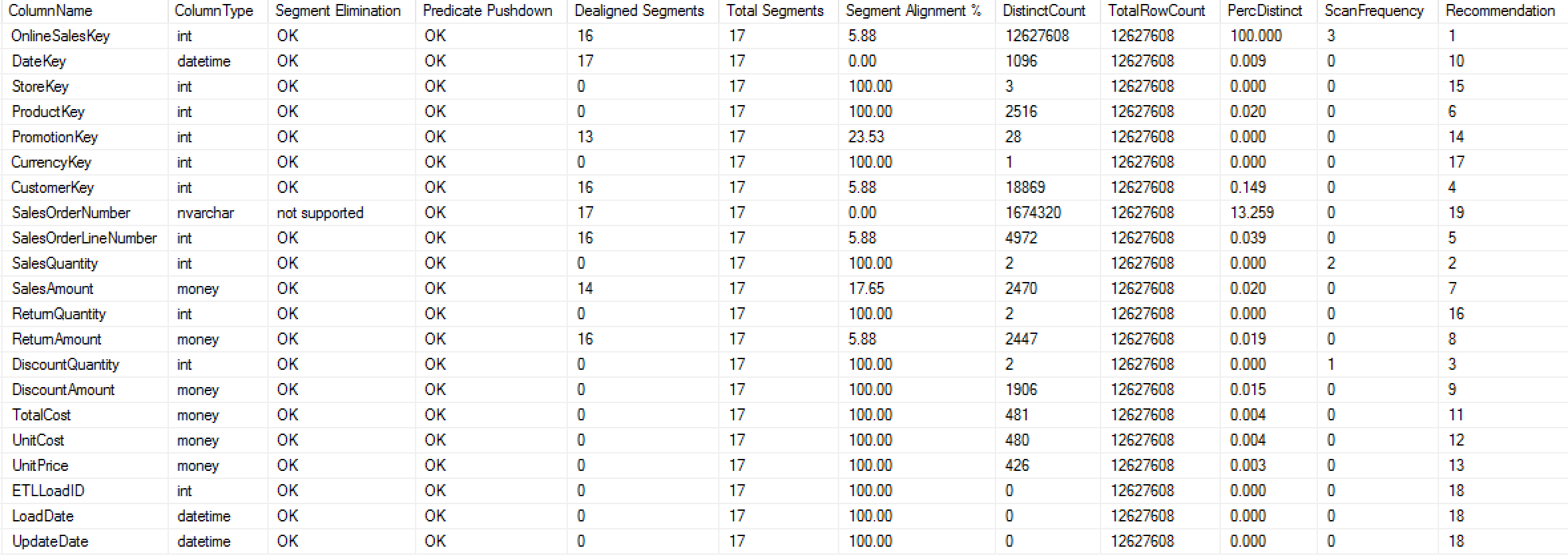
Running all the options at once, requires all 3 new parameters to be set to active:
exec dbo.cstore_GetAlignment @tableName = 'FactOnlineSales', @preciseSearch = 1,
@showSegmentAnalysis = 1, @countDistinctValues = 1, @scanExecutionPlans = 1;
The results in a real environment will be significantly more complex than on the picture below (think per-partition, hundreds of columns, hundreds of tables), but this might give you a first idea about the direction and even though sometimes the recommendations will fail, it will provide you, the specialist the important and easy to use tool to prepare the optimisation for the Segment Alignment.
SQL Server 2016+
This script extension is mainly developed, optimised and tested for the SQL Server 2016 and posterior versions (naturally supporting Azure SQL Database). The further optimisations & enhancements will be coming to this script as soon as I start collecting real feedback on it.
SQL Server 2014 & SQL Server 2012
Currently I have implemented the same functionality without any regard for the specifics of the previous SQL Server versions (lack of the support for the multiple distinct count operations with Batch Execution Mode), and I am thinking about improving the speed of the queries in the future, this is by far not the highest priority for my library right now.
I do not expect this solution to be perfect, but I expect in the months to come to improve the formula based on the feedback I will be getting and to automatise the Columnstore Indexes maintenance completely for the CISL cstore_doMaintenance function.
Grab the cstore_GetAlignment function for any of the supported SQL Server versions now (2012, 2014, 2016, 2017 & Azure SQLDatabase) and give it a spin, while helping me to tune the results.
to be continued with
Columnstore Indexes – part 111 ("Row Group Elimination – Pain Points")