Continuation from the previous 106 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
I would like to thank Sunil Agarwal (Program Manager) & Vassilis Papadimos (Software Engineer) for all their patience and explanations, helping me to get to the bottom of the faced issues and delivering me a precise explanation.
From a recent experience at a customer, I had an opportunity to dive into the details of the Columnstore Indexes Dictionaries. I have to admit that my understanding of them was pretty low, from what I have learned in the recent days, and I would like to share what I have learned with everyone.
These are some of the key findings that I have discovered:
– The local dictionaries are not exclusively connected with just 1 Row Group, but with multiple ones;
– The dictionaries within Columnstore Indexes are compressed in a different way, depending on the type of the compression applied (Columnstore vs Columnstore Archival);
and let us dive into each one of them:
Local Dictionaries
Let us step back into SQL Server 2012, where the dictionaries had different names, where global dictionaries were called primary dictionaries and the local dictionaries were called secondary dictionaries. This week I came to realisation that the change was not perfect after all, because in reality the local dictionaries are not exclusively to the Row Groups.
This means that a given local dictionary can be used in more than 1 row group and for me, this means that the local dictionaries are not very local. :) Well, in practice they won’t be shared between some random Row Groups, but they will be shared between the Row Groups that are compressed at the same time by the very same thread.
For testing this, I have decided to restore my standard basic test database ContosoRetailDW and run a couple of tests on it:
/*
* Queries for testing Columnstore Indexes
* by Niko Neugebauer (https://www.nikoport.com)
* These queries are to be run on a Contoso BI Database (http://www.microsoft.com/en-us/download/details.aspx?displaylang=en&id=18279)
*
* Restores ContosoRetailDW database from the source, which should be placed in C:\Install\
*
*/
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\SQL16\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\SQL16\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 1;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales
After executing that simple & standard restore script, that also creates a Clustered Columnstore Index, I will execute a simply query, that will count the repetitive usage of the very same local dictionary within different Row Groups
SELECT column_id as [ColumnId], secondary_dictionary_id as [SecondaryDictionary], COUNT(*) as [RowGroupsCount] FROM sys.column_store_segments segs WHERE secondary_dictionary_id >= 0 GROUP BY column_id, secondary_dictionary_id HAVING COUNT(*) > 1 ORDER BY column_id, secondary_dictionary_id;
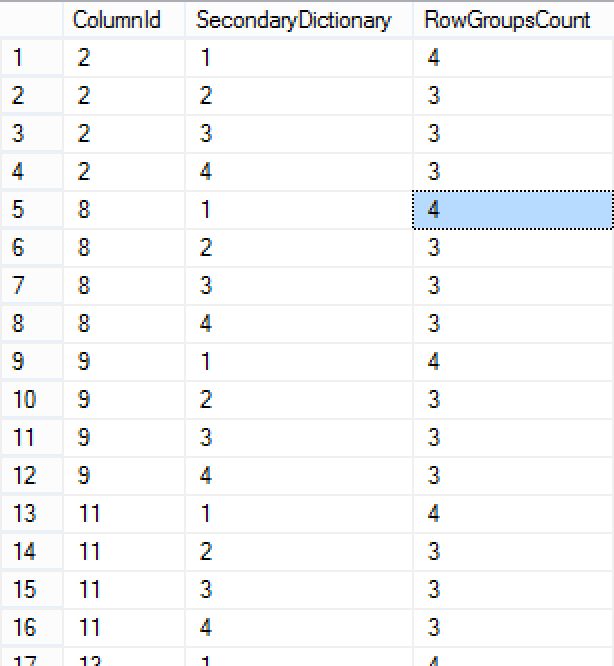 You can see that a big number of columns with dictionaries are actually being reused between different Row Groups, and what you should notice that the maximum value presented below is 4, which in reality corresponds to the number of CPU cores available and configured for SQL Server. This lead to wonder wether the maximum number of the CPU cores influences the number of the available will influence re-usage of the local dictionaries in the Row Groups and that lowering the total number of cores available for the process (by the means of applying the hint MAXDOP = 1) will increase the re-usage of the dictionaries.
You can see that a big number of columns with dictionaries are actually being reused between different Row Groups, and what you should notice that the maximum value presented below is 4, which in reality corresponds to the number of CPU cores available and configured for SQL Server. This lead to wonder wether the maximum number of the CPU cores influences the number of the available will influence re-usage of the local dictionaries in the Row Groups and that lowering the total number of cores available for the process (by the means of applying the hint MAXDOP = 1) will increase the re-usage of the dictionaries.
Let’s test it:
create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales with (drop_existing = on, maxdop = 1);
Let us re-run our analysing statement:
SELECT column_id as [ColumnId], secondary_dictionary_id as [SecondaryDictionary], COUNT(*) as [RowGroupsCount] FROM sys.column_store_segments segs WHERE secondary_dictionary_id >= 0 GROUP BY column_id, secondary_dictionary_id HAVING COUNT(*) > 1 ORDER BY column_id, secondary_dictionary_id;
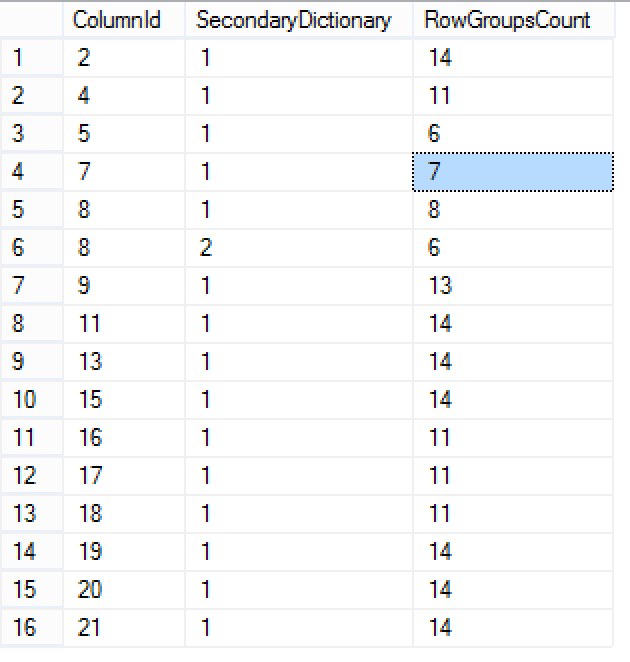 The results are very different this time, we do not have 38 rows returned, but just 16 in total, meaning that there are less dictionaries and that most probably grew bigger. At the same time, the frequency of their repetitive usage between different Row Groups sky-rocketed: with just 14 Row Groups (use the DMV sys.column_row_groups to verify that) we can easily see that some local dictionaries were re-used in every single one of them. This means that the single thread is capable to re-use those dictionaries for all the row groups that are within it’s reach and this is a very important information for those who are tuning their Columnstore Indexes.
The results are very different this time, we do not have 38 rows returned, but just 16 in total, meaning that there are less dictionaries and that most probably grew bigger. At the same time, the frequency of their repetitive usage between different Row Groups sky-rocketed: with just 14 Row Groups (use the DMV sys.column_row_groups to verify that) we can easily see that some local dictionaries were re-used in every single one of them. This means that the single thread is capable to re-use those dictionaries for all the row groups that are within it’s reach and this is a very important information for those who are tuning their Columnstore Indexes.
Focusing on the Delta-Stores, think about them as the good way of loading the data, that most of the time will not be trimmed because of the existing local dictionaries.
Let us consider the following example, where I shall create a new table FactOnlineSales_Delta with a Clustered Columnstore Index:
USE [ContosoRetailDW] GO CREATE TABLE [dbo].[FactOnlineSales_Delta]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, INDEX CCI_FactOnlineSales_Delta CLUSTERED COLUMNSTORE );
Lets load a complete copy of the FactOnlineSales table, by loading the data directly into our new table, making sure it will land directly into the Delta-Stores:
insert into dbo.FactOnlineSales_Delta WITH (TABLOCK) (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) SELECT OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales;
Let’s check the current state of the shared dictionaries and store the data into the ‘dbo. dbo.DictionariesSnapshot’ table:
DROP TABLE IF EXISTS dbo.DictionariesSnapshot;
SELECT column_id as [ColumnId],
secondary_dictionary_id as [SecondaryDictionary],
COUNT(*) as [RowGroupsCount]
INTO dbo.DictionariesSnapshot
FROM sys.column_store_segments segs
inner join sys.partitions part
ON segs.hobt_id = part.hobt_id AND segs.partition_id = part.partition_id
WHERE secondary_dictionary_id >= 0
and object_id = object_id ('FactOnlineSales_Delta')
GROUP BY column_id, secondary_dictionary_id
HAVING COUNT(*) > 1
Now, I will load 4.4 Million Rows in a bathes loop with a single batch occupying 100.000 rows:
SET NOCOUNT ON; declare @i as int; set @i = 1; begin tran while @i <= 44 begin insert into dbo.FactOnlineSales_Delta (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) SELECT TOP 100000 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales; set @i = @i + 1; end; commit; CHECKPOINT alter index CCI_FactOnlineSales_Delta on dbo.FactOnlineSales_Delta REORGANIZE;
Invoking ALTER INDEX .. REORGANIZE at the end will compress all closed Delta-Stores and thus we shall see if there are any changes to the currently re-used local dictionaries by checking the current state and comparing with the data that we have stored within 'dbo.DictionariesSnapshot' table:
SELECT column_id as [ColumnId],
secondary_dictionary_id as [SecondaryDictionary],
COUNT(*) as [RowGroupsCount]
FROM sys.column_store_segments segs
inner join sys.partitions part
ON segs.hobt_id = part.hobt_id AND segs.partition_id = part.partition_id
WHERE secondary_dictionary_id >= 0
and object_id = object_id ('FactOnlineSales_Delta')
GROUP BY column_id, secondary_dictionary_id
HAVING COUNT(*) > 1
EXCEPT
SELECT * FROM dbo.DictionariesSnapshot;
The query above delivers no results in my case, meaning that no local dictionary was re-used for the new Row Groups, compressed by Tuple Mover. Do not think about this method as a silver bullet, because as I have shown in Columnstore Indexes – part 68 ("Data Loading, Delta-Stores & Vertipaq Compression Optimisation"), having secondary Nonclustered Rowstore Indexes over Clustered Columnstore Index and loading data with Tuple Mover will disable the Vertipaq optimisations, which will have a definitive impact over your overall size of the table.
In the end, think about the current system in the following way: when a local dictionary gets full, it will trim all Row Groups that are applying it.
Row Group Trimming & Compression
Another very interesting aspect that I have observed recently was the effect of the applied overall compression on the Columnstore Indexes over the Row Group trimming. Yes, you read it right - the type of the compression (Columnstore Default vs Columnstore Archival) will bring you actually different sizes for your Row Groups, if you are facing dictionary pressure, and if you have some strings columns in your table with the size of 10 characters or superior, it is most probable that you do.
Let us take a simple table with a lot of characters to be inserted (800 to be precise), and generate a sequence of the similar values, that will successfully trigger dictionary pressure if we create Clustered Columnstore index after loading the data - 1.05 Million Rows.
DROP TABLE IF EXISTS dbo.DictionaryTest;
CREATE TABLE dbo.DictionaryTest (
c1 char(800) NOT NULL
);
set nocount on
declare @outerloop int = 0
declare @i int = 0
while (@outerloop < 1050000)
begin
SET @i = 0
begin tran
while (@i < 2000)
begin
insert into DictionaryTest
values ( concat( NEWID(), (REPLICATE ('A', 750)) ) );
set @i += 1;
end
commit
set @outerloop = @outerloop + @i
set @i = 0
end
-- Creates Clustered Columnstore Index
CREATE CLUSTERED COLUMNSTORE INDEX CCI_DictionaryTest ON dbo.DictionaryTest;
To see the current state of the Row Groups can be observed by issuing queries against the sys.dm_db_column_store_row_group_physical_stats DMV, but I will be using my open-source free library CISL function dbo.cstore_GetRowGroupsDetails for that:
select total_rows
from sys.dm_db_column_store_row_group_physical_stats
where object_id = object_id('dbo.DictionaryTest');
exec dbo.cstore_GetRowGroupsDetails @tableName = 'DictionaryTest', @showTrimmedGroupsOnly = 1;
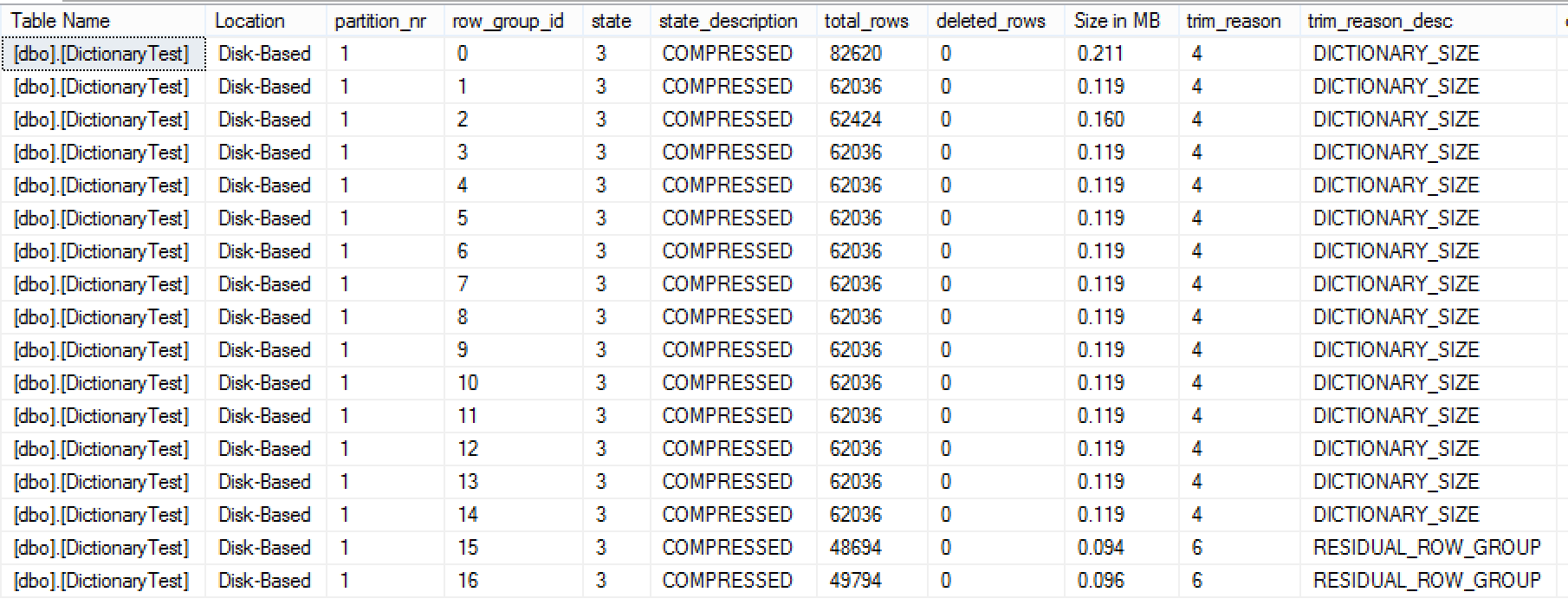 For the default compression we have 17 Row Groups overall, with the most of the Row Groups having just 62036 rows. Let's rebuild our table, but this time forcing Columnstore Archival compression on our Clustered Columnstore Index:
For the default compression we have 17 Row Groups overall, with the most of the Row Groups having just 62036 rows. Let's rebuild our table, but this time forcing Columnstore Archival compression on our Clustered Columnstore Index:
CREATE CLUSTERED COLUMNSTORE INDEX CCI_DictionaryTest ON dbo.DictionaryTest WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE, DROP_EXISTING = ON);
Going back to verify the current state of the Row Groups
select total_rows
from sys.dm_db_column_store_row_group_physical_stats
where object_id = object_id('dbo.DictionaryTest');
exec dbo.cstore_GetRowGroupsDetails @tableName = 'DictionaryTest', @showTrimmedGroupsOnly = 1;
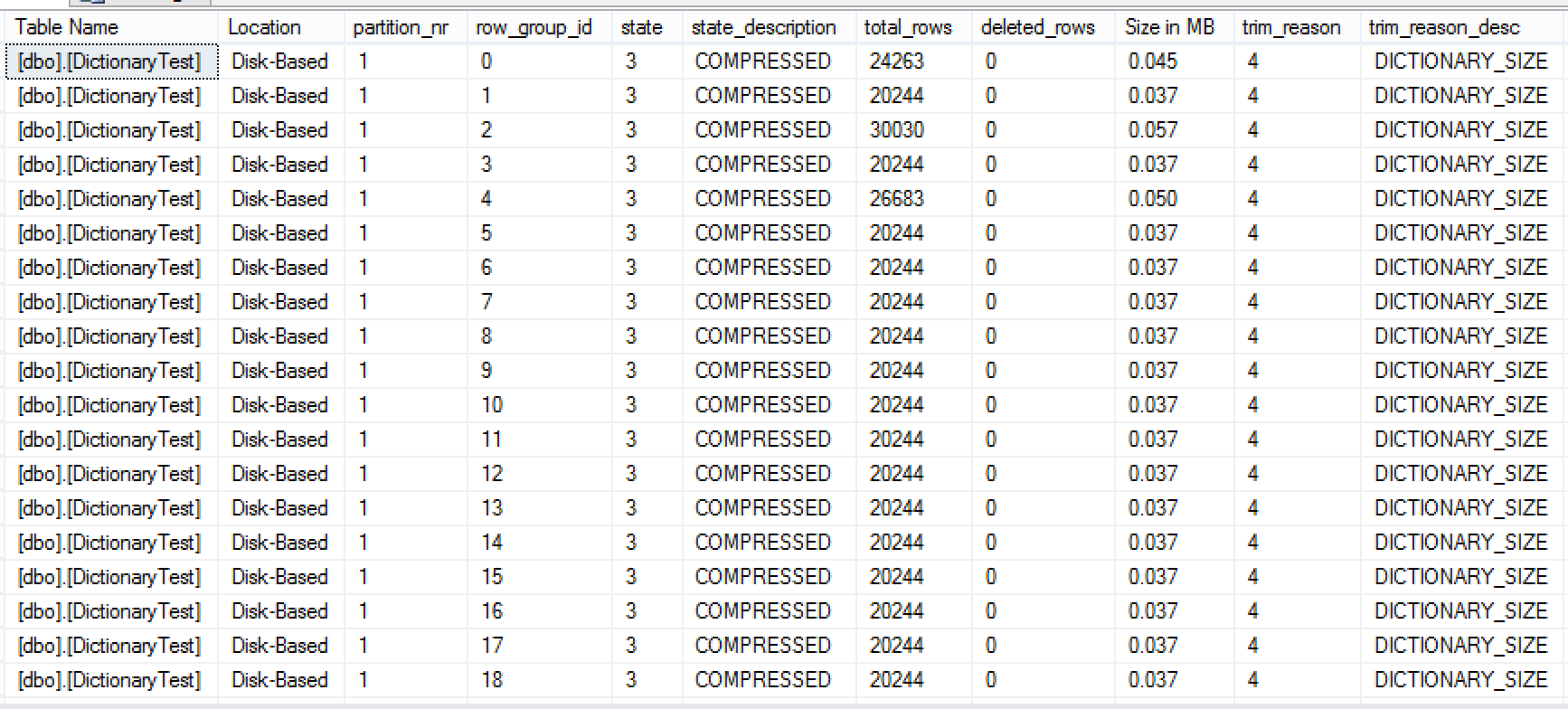 This time with the Columnstore Archival compression we have received 52 Row Groups with the most of them containing around 1/3 of the rows, that a Row Group for the default Columnstore compression contains - around 20K. This is really a huge difference but what about the overall size ?
This time with the Columnstore Archival compression we have received 52 Row Groups with the most of them containing around 1/3 of the rows, that a Row Group for the default Columnstore compression contains - around 20K. This is really a huge difference but what about the overall size ?
you can see the comparisons on the pictures below:
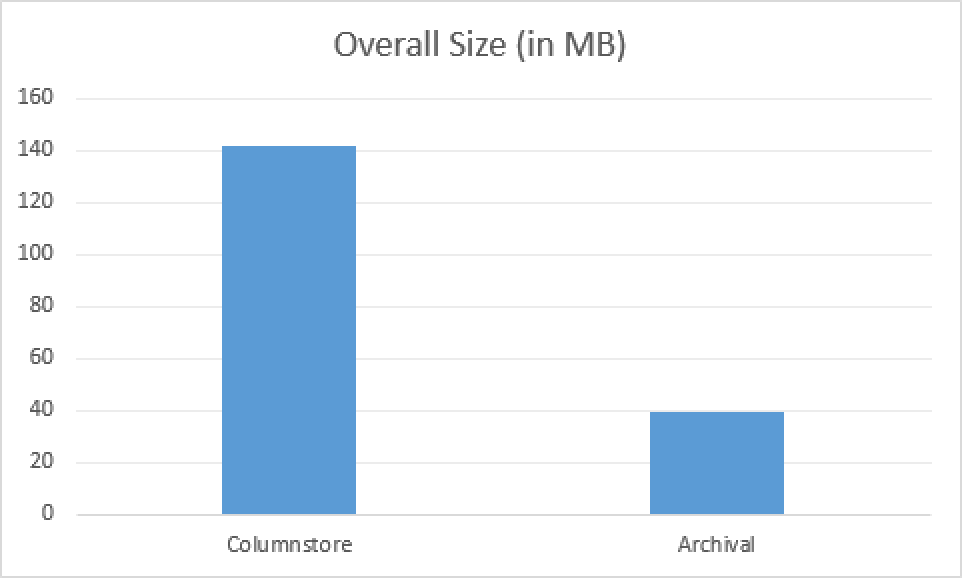
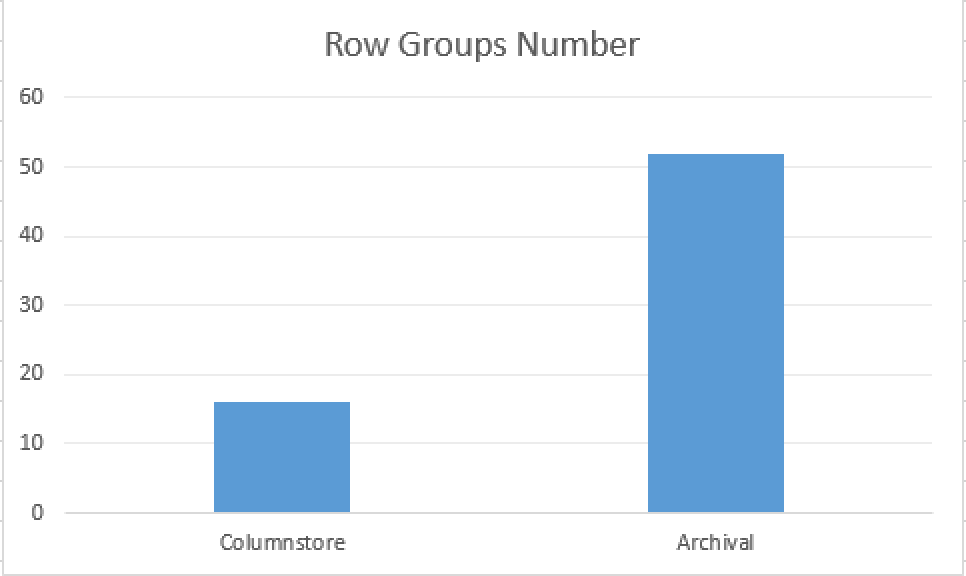
While definitively the number of Row Groups has increased and the overall size of the Row Group has decreased 3 times, the overall size of the table has decreased 3.5 times with the Columnstore Archival compression!!!
We need to watch out, because with the small Row Groups will disable the advantages of the perfecting, that I have described in Columnstore Indexes – part 50 ("Columnstore IO").
But let's dive a little bit into the actual dictionary sizes for both of the scenarios - for the default Columnstore and for the Columnstore Archival compression.
We can observe the dictionaries with ease when using the CISL cstore_getDictionaries function:
exec dbo.cstore_GetDictionaries @tableName = 'DictionaryTest';
The results for the both scenarios are quite impressive - while the maximum local dictionary for the default compression rounds about 7-8 MB (and this is where the real dictionary pressure starts in my experience), for the Columnstore Archival compression the size that we can see is that the biggest local dictionary is around 0.7 MB !
![]()
![]()
How can it be that while Microsoft says that the dictionary pressure arises for the 16 MB and we have here dictionary pressure for the dictionary that is not even 1MB big ?
This has to do with the fact that the dictionaries themselves are compressed and depending on the overall compression of the Columnstore Index, the different compression will be applied on the dictionary itself. This is the reasons that for the years I have been observing the dictionary pressure starting to show around 7-8 MB, this was happening because I could only observe the compressed size of the dictionaries.
This brings us to the stand that the dictionaries DMV should expose the uncompressed size of the dictionary, because this would allow us to determine when the pressure starts to arise in advance or at least to confirm the expected situation.
Which column caused the Dictionary compression?
Another thing that is really missing from the engine is when we have a huge fact table with hundreds of columns and dozens of string columns, should we determine that our Row Groups are trimmed because of the dictionary pressure, how can we determine which exact column has caused the pressure to trim ? In order to start removing or re-engineering this column we need to determine it, and playing with all of them on the huge tables is not a real option.
Right now there is no way to determine it, because no DMVs or Extended Events will deliver this information, but I will be opening a Connect item for Microsoft to include this information in the future (and hopefully at least SQL Server 2016) releases.
Final Thoughts
It is fascinating to discover all different aspects and situation how Columnstore Indexes are functioning, we need to watch over our indexes in order to get the best efficiency out of them, because leaving them alone, might lead us to low and inefficient performance.
What I would like to have in the future?
- Connect Item for identifying the Column that causes dictionary trimming
- Connect Item for exposing the real/uncompressed size of the dictionaries
to be continued with Columnstore Indexes – part 108 ("Computed Columns")