Continuation from the previous 103 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post is a logical continuation of the blog post that I have published in December 2016 – Columnstore Indexes – part 93 (“Batch Mode Adaptive Memory Grant Feedback”), but this time I will be focusing on the most recent addition to the SQL Server Query Optimiser in freshly announced SQL Server 2017: Batch Mode Adaptive Joins.
Lead by the incredibly clever and insanely nice Joe Sack, this is another feature that will lead SQL Server into conquering into the field of the automated query execution improvement, by allowing to take corrective action without changing (recompiling or rebuilding) the execution plan of the query.
One of traditional ways of getting the query doing a more correct choice for the execution plan is to recompile it – thus avoiding the parameter sniffing.
Another way would be clearing the stuck execution plan from the memory (for a system with a lot of such situations, it would be a huge pain).
A third way is to solve the wrong join with the hint (HASH JOIN, etc), but it might be quite possible, that this fix will get forgotten – until a bigger problem will arise because of it’s existence.
The worst kind of situation is when we have a query that is constantly requiring the data around the Tipping Point (the point where the optimal change would change from one type of join to another) – unless we find a safe middle ground or fix it with a hint or some other methods, we shall need to throw more resources to tackle the problem.
Enters Batch Mode Adaptive Join operator, the execution plan operator that will allow automated choice between the Hash Join and the Nested Loop Join during the query execution. The decision will be delayed/deferred until after the right side (upper) of the join is processed/scanned.
The Batch Mode Adaptive Join operator will contain a certain threshold for the decision which subtree execution will be used, based on the overall cost of the plan.
To my understanding this sounds deliciously cool – this is very understandable, simple and should be reasonably safe in the most situations.
Without too much hype (haha, you might think – you hipster writing that …), I also consider that it might bring the danger of choosing the wrong plan when it will bring down the performance of already great performing query, and I am confident that there will be a number of such cases, when the adaptive decision even though the best for the query itself will influence the overall status of the system, slowing it down in the eyes of the Database Administrator, Developer or the final user. This system will not be perfect, but it will bring the incredible improvement that would not be possible at all in the previous versions.
Yes, there will need to be an option for controlling it, but I guess this is my instinctive reaction to any new feature in the SQL Server – I want to be able to disable it, if needed; but overall I am expecting an extremely happy future and even in the couple of years people wondering how it was before Adaptive Query Optimiser in the SQL Server world …
But let us get to the test and for that, I will use my own generated copy of the TPCH database (10GB version), that I have done with the help of the HammerDB (free software).
/*
* This script restores backup of the TPC-H Database from the C:\Install
*/
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1gb_new.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
-- SQL Server 2017
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 140
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
After restoring the generated TPCH database and setting the compatibility level to 140 (SQL Server 2017), I will create a copy of the dbo.lineitem table, that will be called dbo.lineitem_cci, and which will contain 60 million rows – the same data as the original one:
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
GO
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
Now, let’s consider a reasonable safe query to run, where we select all discount values out of the line item_cci table, based on the shipping date, while joining with the supplier table, with which we do not have a foreign key defined.
As a parameter, I have defined the 1st of January of 1998:
declare @discount money; select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = '1998-01-01'
You can find the execution plan below, together with the newest element in the Execution Plan family – the Adaptive Join, which will take not 1, not 2 but whole 3 Inputs:
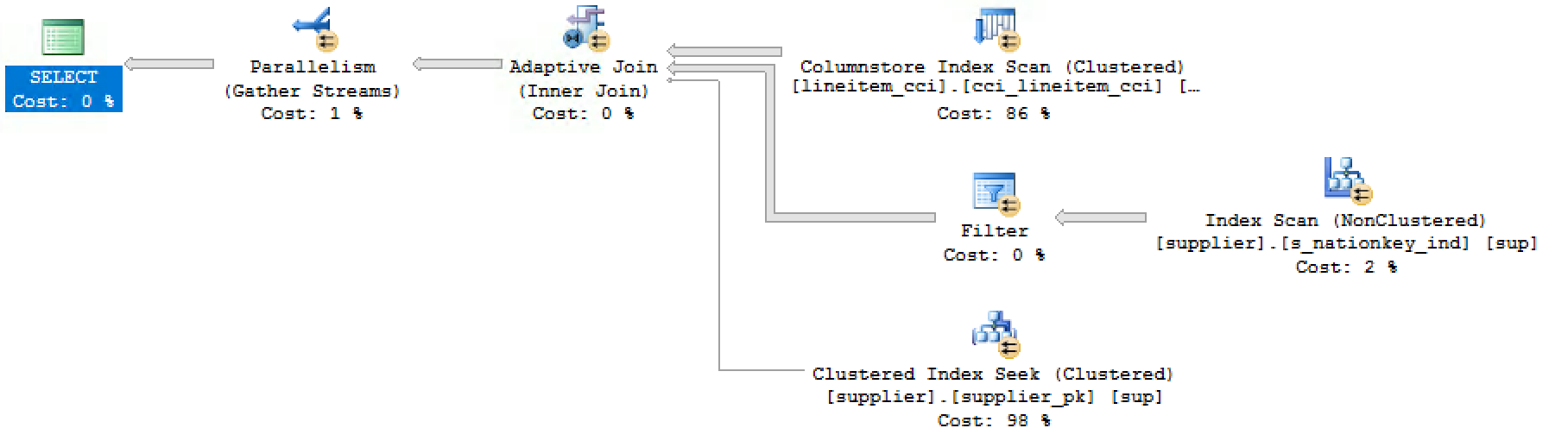
The 1st input is obvious – the Columnstore Index Scan of the LineItem_CCI table, the results (number of rows) from which will allow make the decision on the path to follow.
The 2nd input is the result of the Index Scan on the Supplier table and the following filter iterator. This subtree shall be executed if we have enough rows from the Input 1 to make an effective Hash Join. For scanning the Supplier table we shall be using [s_nationkey_ind] index.
The 3rd input is the new pony on the block(TM) – it represents the scenario when there are just a few rows coming through the 1st input and there is no need to scan the whole index, but we can safely seek the data out of the clustered index (primary key): supplier_pk.
As you can see the fat arrow sending the data into the Adaptive Join, you will easily understand that it has chosen to use the 2nd Input for the query processing, thus enabling the Hash Join strategy.
A little trick needs to be mentioned – unless you are running a special version of the SSMS 2017, you might not be able to be see this execution plan element and even more – enabling the actual execution plan might produce you the following error:
An error occurred while executing batch. Error message is: Error processing execution plan results. The error message is: There is an error in XML document (1, 6889). Instance validation error: 'Adaptive Join' is not a valid value for PhysicalOpType.
To solve that in part, execute the following statement, which shall allow you to see the execution plan in the good old traditional style:
SET SHOWPLAN_TEXT ON
Re-execute our test query again and you will be faced with a similar output:

Here you can see how the query will be processed, naturally without the important details of which way was actually selected, but until there is a stable SSMS version, this might provide you with some basics.
Please, do not forget to reset the ShowPlan Text property back, before continuing:
SET SHOWPLAN_TEXT OFF
UPDATED ON 23.04.2017
After great suggestion given by Antony in the comments, I decided to update this blog post with the information that in order to see the chosen path within elder SSMS version, you can set the statistics profile, with the help of the following statement: SET STATISTICS PROFILE ON:
SET STATISTICS PROFILE ON declare @discount money; select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = '1998-01-01'; SET STATISTICS PROFILE OFF
 You can see on the picture on the right side, that the chosen execution path is easily identifiable through the number of the executes (the second column).
You can see on the picture on the right side, that the chosen execution path is easily identifiable through the number of the executes (the second column).
Now, let’s see what execution plan we shall able to observe if we put the 1st of January of 1999 as the parameter to our query:
declare @discount money; select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = '1999-01-01'
The actual execution plan is included below:
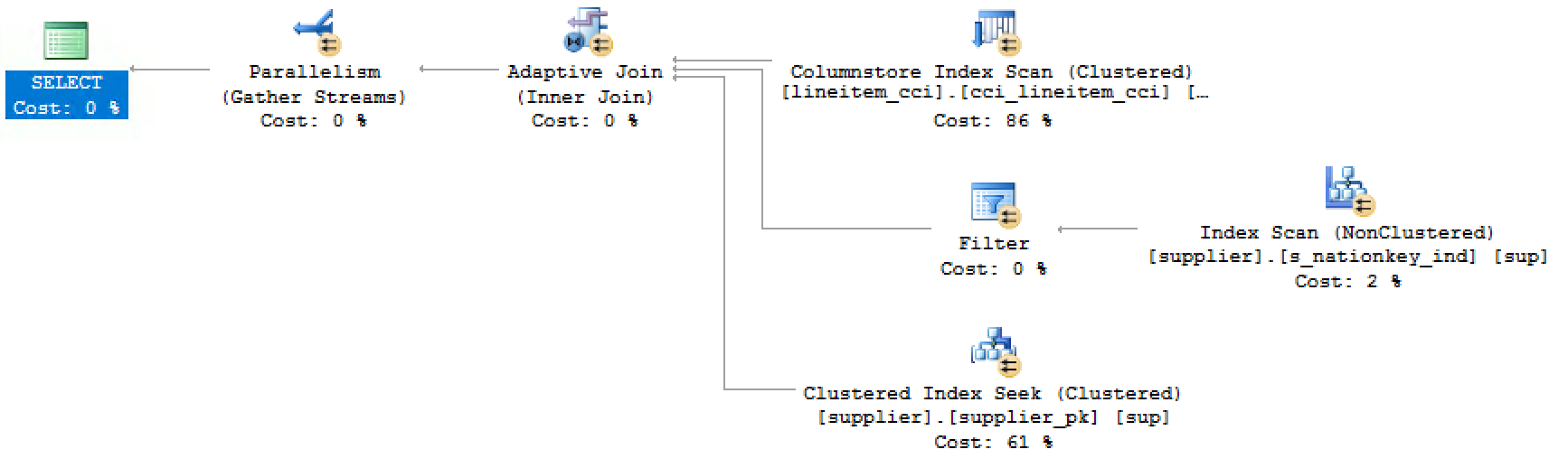
You can clearly notice that because there are no rows flowing out of the Input 1 (Columnstore Index Scan on the lineitem_cci table), the Adaptive Join is turning it’s attention to the Input 3 in this case (Clustered Index Seek).
The same plan ? Really? Prove it!
I have heard a voice in my head saying “Yeah, I can see, you are running 2 queries, which generate 2 distinct plan hashes and selling them as the same ones!”
I know that I need to show a better proof that the very same plan can adjust itself, and here it is, where the same query will be packed into a Stored Procedure TestDiscount:
create or alter procedure dbo.TestDiscount ( @shipdate date ) as BEGIN declare @discount money; select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = @shipdate; END
We should reset the Procedure Cache,
DBCC FREEPROCCACHE;
before being executed with 2 distinct parameters, corresponding to the same values I have used previously:
Exec dbo.TestDiscount '1998-01-01'; Exec dbo.TestDiscount '1999-01-01';
and the final proof will come in the form of the following DMV query:
SELECT * FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) pl
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) txt
WHERE txt.dbid = DB_ID()
AND txt.objectid = OBJECT_ID('dbo.TestDiscount');
with the results being presented below on the picture:
![]()
Notice that I have already executed the stored procedure 4 times, (the invocation script executed twice, and that is why I have 4 as the usercounts value for the number of invocations).
Execution Plan Adaptive Join iterator Properties
 There are a number of new properties that the Adaptive Join iterator is getting. To my understanding, the most of them are already present in the CTP 2.0 of the SQL Server 2017, but the most important one is still missing and should be coming before the RTM.
There are a number of new properties that the Adaptive Join iterator is getting. To my understanding, the most of them are already present in the CTP 2.0 of the SQL Server 2017, but the most important one is still missing and should be coming before the RTM.
We can see if the join is adaptive (IsAdaptive), the number of rows that will trigger change from the hash join to the nested loop join (AdaptiveThresholdRows), the estimated join type (EstimatedJoinType).
The currently missing item is the actual type of join that was executed (ActualJoinType).
Extended Events
At the moment of the CTP 2.0, the only Extended Event I can possibly find is the AdaptiveThresholdRows, which is confirmed by Joe Sack in the original article, which I believe is a miss – we definitely need a tool to track Adaptive Joins happening on our systems, and especially the threshold filtering would be an interesting task to automate.
Let’s find all the executions that went into the nested loops, because the Threshold is still too high – what is the Extended Event to be used for that ?
I hope that there is still time to include such information into the SQL Server 2017 before the RTM.
Limitations
There are enough limitations to the Adaptive Join in its first iteration – the query plans should be using INNER LOOPS or HASH JOIN combination, the hash join will need to be executed with the Batch Execution Mode, the generated alternative solutions of the nested loop join and hash join should have the same first child,
and of course – the compatibility level will need to be set to 140.
Mixing Adaptive Query Processing
The Adaptive Query Processing improvements are not mutually exclusive, and the very same query we have been using is the best example of it.
To test it, enable the actual execution plan and run the following workload, clearing out the procedure cache and running our query 2 times with the same parameter for the nested loop join – 1999-01-01:
DBCC FREEPROCCACHE; declare @discount money; select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = '1999-01-01' select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = '1999-01-01'
The memory grants for both executions are shown below:
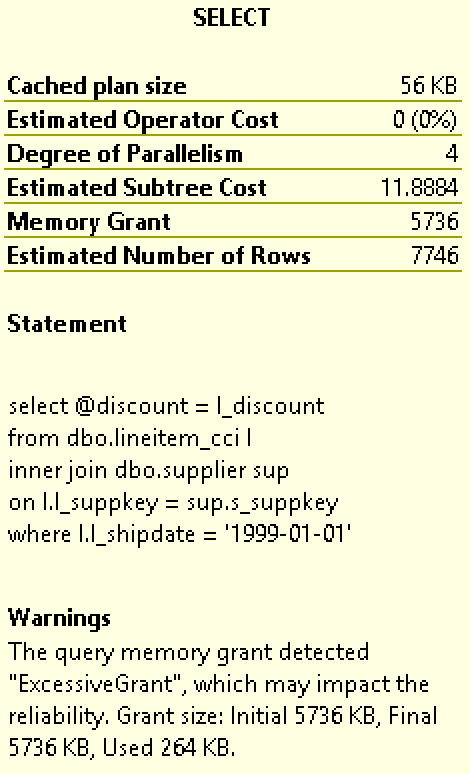

You can see that the amount of memory for the first execution of the nested loops was found to be excessive (and this might be a huge problem in the real life, because of the one potential exception that will drive everyone nuts why nested loops are eating memory like never before), and so as described in Columnstore Indexes – part 93 (“Batch Mode Adaptive Memory Grant Feedback”), the memory grant will be lowered for the consecutive executions from 5.736 MB to 5.192 MB.
I love the fact that these improvements are not killing each other, but the complexity here can start becoming quite an item in couple of years and good tracing tools (Extended Events) will be the of the highest importance.
Some Final Thoughts
Love it, Love it, Love it !
This might help a number of workloads and I am eager to start working on a project of taking this item into production.
Even though we have a tool for disabling the joins, by setting the compatibility level of the database …
to be continued with Columnstore Indexes – part 105 (“Performance Counters”)
> The worst kind of situation is when we have a query that is constantly requiring the data around the Tipping Point
That’s actually the best point because the choice does not matter! What you meant, I think, was a query that oscillates between the two extremes.
You should make it a habit to diff the execution plan schema XML file when a new SSMS version comes out. I wonder what kinds of new features one would find there before the announcement.
Hi tobi,
Good Point!
Well, unless you are running point-lookups and your memory is instantly blown to the max, while you are still running Nested Loops.
Best regards,
Niko
When running the older SSMS, rather than SHOWPLAN_TEXT, try STATISTICS PROFILE. This shows you the text plan with actual executes/rowcounts, so you can see which branch was actually picked from the adaptive join.
Thank you, Antony !
A very good catch! I will update the article with this suggestion.
Best regards,
Niko