Continuation from the previous 99 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
In Data Warehousing one will not be shocked to find a number of tables using IDENTITY property on a column, a lot of times to create automatic incremental values for the surrogate keys.
What about the Columnstore Indexes ? Should one use IDENTITY for the tables with Clustered Columnstore Indexes ?
This blog post will try to respond this question from the perspective of the data loading performance.
For this research I decided to pick 3 distinct scenarios to investigate, which refer to different ways to approach the solution:
– a CCI table with an Identity column
– a CCI table with a Sequence as a default value
– a CCI table without Identity
Still so useful for the smaller demos is the old time favourite free database ContosoRetailDW will be used for the tests (with the original backup being stored in C:\Install\ folder):
Let’s restore it on the SQL Server 2016 SP1 and create
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Let’s create staging table FactOnlineSales_Stage with 2 million rows from the FactOnlineSales. This staging table shall be used as a source for data loading procedures.
use ContosoRetailDW; DROP TABLE IF EXISTS [dbo].[FactOnlineSales_Stage]; CREATE TABLE [dbo].[FactOnlineSales_Stage]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [numeric](18, 3) NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [CCI_FactOnlineSales_Stage] ON [dbo].[FactOnlineSales_Stage]; GO INSERT INTO dbo.FactOnlineSales_Stage WITH (TABLOCK) ( OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT TOP 2000000 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales;
CCI Table with an Identity column
The most common scenario to find in the wild and to consider is the one where we simply put an IDENTITY property on one of our columns in the table, so here is the script to set it up:
DROP TABLE [dbo].[FactOnlineSales_Identity]; CREATE TABLE [dbo].[FactOnlineSales_Identity]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [numeric](18, 3) NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [CCI_FactOnlineSales_Identity] ON [dbo].[FactOnlineSales_Identity]; GO
Let’s load the data from our staging table FactOnlineSales_Stage into our newly created table, with the following script:
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_Identity; INSERT INTO dbo.FactOnlineSales_Identity --WITH (TABLOCK) ( /*OnlineSalesKey, */ DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_STAGE;
If you have paid attention when using IDENTITY with the Rowstore Indexes work, you might already expect the result. :)
This process took over 11 seconds with a very similar amount of time (around 10.5 seconds on average for the CPU time spent). This result is far from being good or exciting.

Looking at the execution plan exposes that it is being executed single-threadedly, with no advantages of running this workload on the enterprise edition – which is truly disappointing. The reason behind this is our IDENTITY column, which in order to be generated needs to be executed single-threadedly and this invalidates the potential parallelism, even though our estimated cost is above 250. This was so bad, that even reading the data out of the Clustered Columnstore Index was limited to be a single-threaded process.
In SQL Server 2016 there were some significant changes for the data loading process and in Columnstore Indexes – part 63 (“Parallel Data Insertion”) I blogged about it, showing that TABLOCK hint on the destination table might help you getting parallel data insertion (it will not work if you are loading data from a different server).
Let’s add a TABLOCK hint to our dbo.FactOnlineSales_Identity table and see if we can get any improvements:
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_Identity; INSERT INTO dbo.FactOnlineSales_Identity WITH (TABLOCK) ( /*OnlineSalesKey, */ DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_STAGE;
You might be shocked or surprised, but hey – there are no changes in the execution plan (well, besides the overall estimated costs lowering down to 170 from 250), but the execution is still single-threaded and the differences in the execution time and CPU time are non-existent.
These are not very good news for a lot of people who would expect right from the start.
I wish that Microsoft would invest some time in improving IDENTITY performance.
CCI Table with a default SEQUENCE
The SEQUENCE Objects were added in SQL Server 2012 but for strange reasons they are still not popular with the developers. The Sequences can substitute the IDENTITY and give you much more with possibility of the multiple columns in the same table, automated looping and restarting and so much more.
To create a Sequence in SQL Server you can use the SQL Server Management Studio or t-sql (and notice that I have set the Cache to 100.000 values, so it might perform a little bit better than Identity, which is cached to 1.000 values by default:
CREATE SEQUENCE [dbo].[S1] AS [int] START WITH 1 INCREMENT BY 1 MINVALUE -2147483648 MAXVALUE 2147483647 CACHE 100000 GO
Let’s create another test table where we shall use the default value for our Sequence for the OnlineSalesKey column:
DROP TABLE IF EXISTS [dbo].[FactOnlineSales_Sequence]; CREATE TABLE [dbo].[FactOnlineSales_Sequence]( [OnlineSalesKey] [int] NOT NULL DEFAULT (NEXT VALUE FOR dbo.S1), [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [numeric](18, 3) NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [FactOnlineSales_Sequence] ON [dbo].[FactOnlineSales_Sequence]; GO
Now back to our loading process, let’s load data and measure the performance:
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_Sequence; INSERT INTO dbo.FactOnlineSales_Sequence ( /*OnlineSalesKey, */ DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_Stage;
I have received the identical execution plan as in the case with IDENTITY and the performance was virtually identical:

What about the TABLOCK and the parallel loading, will it work with the SEQUENCES as default values, let us try it out:
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_Sequence; INSERT INTO dbo.FactOnlineSales_Sequence WITH (TABLOCK) ( /*OnlineSalesKey, */ DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_Stage;
This time we we shall get a parallel insertion into our table, as you can see on the execution plan below:
![]()
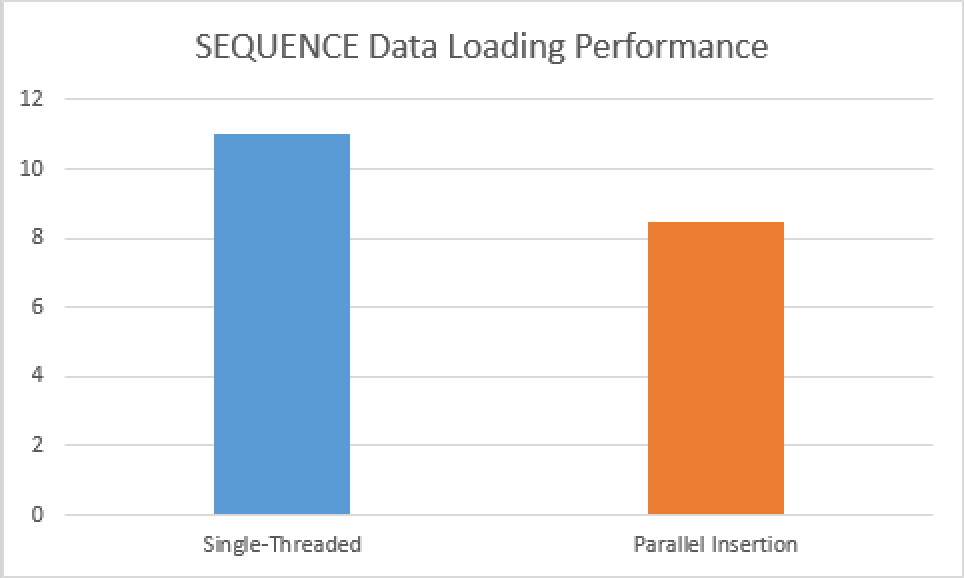 We have spent 8.5 seconds on this query and 21.5 seconds of the CPU time was spent, of course, we still did not receive the parallel reading from the staging table, but the positive impact is very visible – we get over 20% improvement in the performance!
We have spent 8.5 seconds on this query and 21.5 seconds of the CPU time was spent, of course, we still did not receive the parallel reading from the staging table, but the positive impact is very visible – we get over 20% improvement in the performance!
The Compute Scalar iterator is doing the following operation Scalar Operator(GetSequenceNext(dbo.S1)), basically calculating the values for the SEQUENCE next values and this is the operation that is preventing the Columnstore Index Scan iterator from going Parallel, because what one expects is that the values in the sequence shall be generated without any gaps and this part is not exactly easy with parallel processes.
CCI table without Identity
For comparison, let us use the same table, but without any IDENTITY or the SEQUENCE usage, and so here is the setup script for it:
DROP TABLE IF EXISTS [dbo].[FactOnlineSales_NoIdentity]; CREATE TABLE [dbo].[FactOnlineSales_NoIdentity]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [numeric](18, 3) NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [CCI_FactOnlineSales_NoIdentity] ON [dbo].[FactOnlineSales_NoIdentity]; GO
Loading the data into the FactOnlineSales_NoIdentity table in the same way as we did before:
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_NoIdentity; INSERT INTO dbo.FactOnlineSales_NoIdentity ( OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_Stage;

You see that we have almost the same execution plan as for the other serially executed queries, with the only visible difference is the absence of the Compute Scalar iterator. I have not registered any reasonably measurable performance improvement in this case.
Let’s try out loading the data with the parallel loading process in SQL Server 2016:
TRUNCATE TABLE dbo.FactOnlineSales_NoIdentity; INSERT INTO dbo.FactOnlineSales_NoIdentity WITH (TABLOCK) ( OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_Stage;
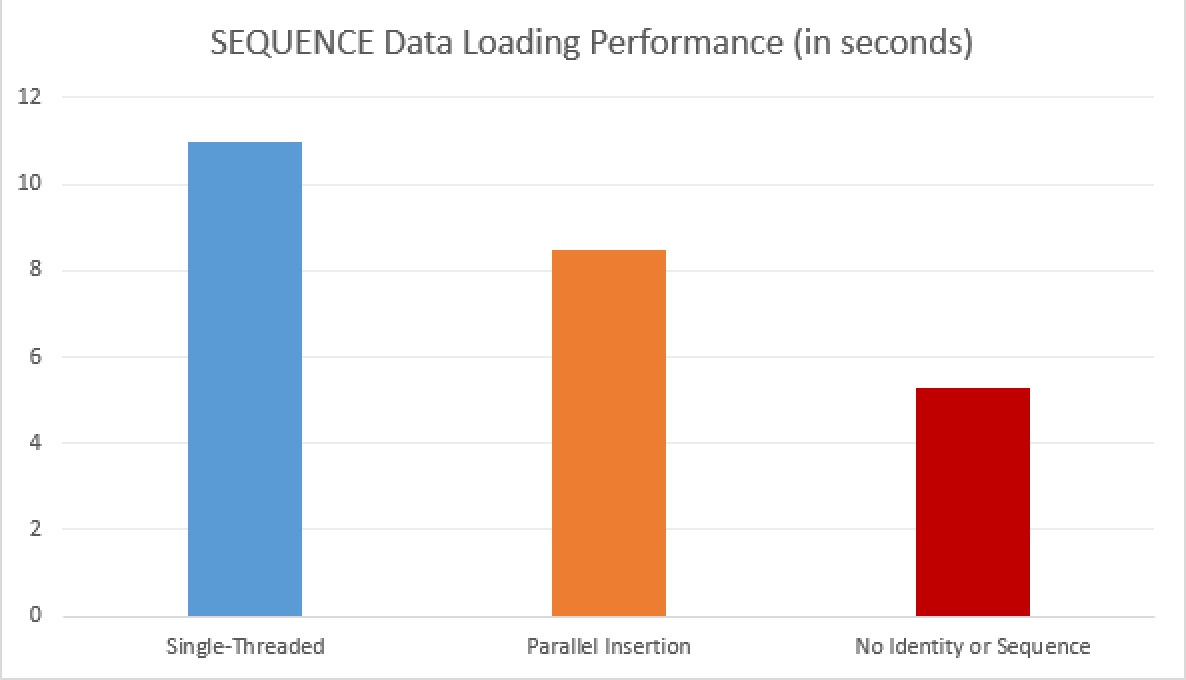
This time the execution plans takes a perfect shape of the parallel plan and the execution plan improves incredibly to the 5.3 seconds !!!

This is how you truly will want to load the data into the tables with Columnstore Indexes. By allowing the load process to run completely in Parallel with 4 cores on the Test VM for those 2 million rows we were able to improve the overall execution times more than 2 times.
Rowstore
Even though for the Rowstore Indexes (with OnlineSalesKey used as a key), the execution plans look the same, the performance is incredibly superior for the IDENTITY property usage. The default load takes 5.3 seconds while the TABLOCK will decrease the overall time even further to the incredible 3.7 seconds. This is definitely not the place where Columnstore Indexes shine through, and here are the scripts to test out:
DROP TABLE [dbo].[FactOnlineSales_Identity]; CREATE TABLE [dbo].[FactOnlineSales_Identity]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [numeric](18, 3) NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO CREATE CLUSTERED INDEX [CCI_FactOnlineSales_Identity] ON [dbo].[FactOnlineSales_Identity] ([OnlineSalesKey]); GO
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_Identity; INSERT INTO dbo.FactOnlineSales_Identity WITH (TABLOCK) ( /*OnlineSalesKey, */ DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_STAGE;
Faster with ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) (UPDATED ON 29th of March 2017)
With the help of Arvind Shyamsundar, I have discovered a wonderful article from him on the SQLCAT blog, where between many very useful ideas, the trick of using ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) is described.
Here is the identical script recreating the table FactOnlineSales_Identity with the Clustered Columnstore Index:
DROP TABLE [dbo].[FactOnlineSales_Identity]; CREATE TABLE [dbo].[FactOnlineSales_Identity]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [numeric](18, 3) NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [CCI_FactOnlineSales_Identity] ON [dbo].[FactOnlineSales_Identity]; GO
And here is the script that shows how to deal with the tables containing identity property and that needs to be loaded really fast.
SET STATISTICS TIME, IO ON TRUNCATE TABLE dbo.FactOnlineSales_Identity; SET IDENTITY_INSERT FactOnlineSales_Identity ON INSERT INTO dbo.FactOnlineSales_Identity WITH (TABLOCK) ( OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate ) SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)), DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales_STAGE; SET IDENTITY_INSERT FactOnlineSales_Identity OFF
The execution plan below shows fully parallelised execution plan that takes only 4.8 seconds to execute on my VM:
![]()
Final Thoughts
 Using Identities within your Columnstore Indexes tables is not a very efficient method when considering data loading strategies, moving your tables to the sequences with default values and using the parallel loading strategy with TABLOCK hint will bring you some improvement. This improvement will become bigger, proportionally to the overall time of the data insertion process.
Using Identities within your Columnstore Indexes tables is not a very efficient method when considering data loading strategies, moving your tables to the sequences with default values and using the parallel loading strategy with TABLOCK hint will bring you some improvement. This improvement will become bigger, proportionally to the overall time of the data insertion process.
If you need to load data as fast as possible, consider moving completely away from the IDENTITY property and the Sequence object. Of course a lot of times this structural changes might not be completely possible, and this blog might shed some light on why your data loading processes are slow.
I hope that in the future the performance of the IDENTITY and the SEQUENCE will be improved in the SQL Server, there are way too many solutions which structure will not be changed in the next years, but the improvements to loading process will be so much welcomed and celebrated.
to be continued …
Hey Niko,
I just tried tests on vNext and parallel execution IS enabled for Identity table with TABLOCK, but execution time is higher than for SP1 SQL Server, where is no parallel plan.
Worse news are for Sequence table – there parallel plan take over 90s, maybe this is because of over scaling VM. I tried to run all three versions of tables against this machine together (to enable majority of cores) but queries for seq and nothing run approximately 90s.
Andrej
Hi Andrej,
will try out today to find out.
Thank you for pointing to this!
Best regards,
Niko
Hi Andrej,
I tried out on SQL Server vNext (1.4, version 14.0.405.198) and have seen no differences.
I do not get any new parallelism on SQL Server vNext and the data reading for the single-threaded data processing still runs with Row Execution Mode. I believe the limitation here is exactly how IDENTITY and SEQUENCES are generated (single-threadedly and non-optimised).
Can you share the execution plans that you are getting ?
Best regards,
Niko
Hi Niko,
I tried again the same thing – and from Azure VM 4cores/14GB RAM I get same results as you. I was surprised, why I saw something different. Then came to my mind, that first time, I had machine 20cores and 140GB RAM. So I resized machine and ran query against Identity table “dbo.FactOnlineSales_Identity” with TABLOCK. I get the same result that you.
Then I drop/create stage table, identity table and heureka – get parallel plan. I will send you screenshots in email.
Andrej
Hi Niko,
Great Read ! Could you please clarify on below points ?
1. “To create a Sequence in SQL Server you can use the SQL Server Management Studio or t-sql (and notice that I have set the Cache to 100.000 values, so it might perform a little bit better than Identity, which is cached to 50 values by default” – I didn’t know identity values are cached, Is there any way to increase default cache size for IDENTITY ?
2. Are there any side-effect of bumping up cache size to 1mn for SEQUENCE ? Where does cached values reside ? Will that affect execution plan for bulk loading as well ?
Appreciate your help. Thank you.
Hi Anil,
Thank you for the questions!
Actually the 50 is the DEFAULT cache value for the SEQUENCE and for the IDENTITY it is set to 1000. I will correct the article.
1. Not to my knowledge.
2. Cache size will affect how often Sequence persist the cache value to the disk. Potentially on big transactions it can slow them down.
If you have a restart your server in the middle of transaction or instance failover shall take place, then you shall potentially loose up to this amount of numbers in the sequence.
It is up to you to decide which number is actually acceptable.
Best regards,
Niko
Thank you Niko for taking time to help.
Congratulations for awesome blog series !!
Hi
I have table with 40B records and 10 TB size on clustered columnstore index.
I am running a query which 0 records or only 2-3 from this large table .
1) If I run select count(*) then it returns quickly less then minute.
2)If I run select * from then it takes 15-20 minutes.
If sql can count 0 or 2-3 records in seconds so why select * takes minutes?
Plan also different for both query to search data.
I have created a connect item as below
https://connect.microsoft.com/SQLServer/feedback/details/3130451/select-taking-too-much-time-while-searching-in-large-table-in-clustered-columnstore-index
Hi Amish,
you will need to provide the actual execution plans to understand your problem, plus the relevant STATISTICS IO & TIME.
Best regards,
Niko
How to provide plan ?
Please also try on your system with such condition so that
select count(*) from table where id = ‘xxxx’
select * from table where id = ‘xxxx’
does it takes same time?
Amish,
If you wish, upload the execution plans to some place where I can take a look at them, for example to https://answers.sqlperformance.com.
Please include the information on the SQL Server with respective patches (CUs & SPs) and the compatibility level set for your database.
I do not need to try out something that works perfectly on my system. Most probably you have different execution plans for the queries with parameter sniffing or outdated statistics.
You should also understand that I am not providing any support, nor am I working for Microsoft.
Best regards,
Niko