Continuation from the previous 98 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post is focused on the MERGE statement for the Columnstore Indexes, or as I call it – the worst enemy of the Columnstore Indexes. It is extremely difficult to imagine some statement or way of making the worst out of the Columnstore Indexes, if not the infamous MERGE statement. Why ? Because it is not only making Columnstore Indexes perform slow, it will make them perform MUCH SLOWER then any Rowstore Indexes. Yes, you have read right – slower then ANY_ROWSTORE_INDEXES. In fact, this should be a hint that one should apply to the Merge statement, when it is executed against Columnstore Indexes! :)
I decide to dedicate a whole blog post on this matter, mainly to warn people of this pretty problematic statement – I hope not to see it being used for Columnstore Indexes in the future!
MERGE T-SQL statement has a huge number of bugs and potential problems with some statements delivering incorrect results or being canceled – for the details I recommend that you read Use Caution with SQL Server’s MERGE Statement where Aaron Bertrand went into the details of why one should strive to avoid using this statement.
You might point that a couple of years ago, I have already published a blog post on the dangers of using UPDATE statement for the Columnstore Indexes, but as I keep seeing MERGE statement on the production servers, it is clearly deserves an own post.
As in the other blog post I will be using the a generated copy of the TPCH database (10GB version this time, because I want my tests to reflect bigger workloads), that I have generated with HammerDB (free software).
Below you will find the script for restoring the backup of TPCH from the C:\Install\
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_10gb.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
GO
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 130
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 2561520KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
I will be showing the data loading on the sample table dbo.lineitem and as previously, here is the setup script for creating the Clustered Columnstore Index on it:
USE [tpch]
GO
DROP TABLE IF EXISTS dbo.lineitem_cci;
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
Now we have a sweet 60 million rows within our lineitem table.
For the data loading test, I will be using the following staging table:
USE [tpch] GO DROP TABLE IF EXISTS [dbo].[lineitem_cci_stage]; CREATE TABLE [dbo].[lineitem_cci_stage]( [l_shipdate] [date] NULL, [l_orderkey] [bigint] NOT NULL, [l_discount] [money] NOT NULL, [l_extendedprice] [money] NOT NULL, [l_suppkey] [int] NOT NULL, [l_quantity] [bigint] NOT NULL, [l_returnflag] [char](1) NULL, [l_partkey] [bigint] NOT NULL, [l_linestatus] [char](1) NULL, [l_tax] [money] NOT NULL, [l_commitdate] [date] NULL, [l_receiptdate] [date] NULL, [l_shipmode] [char](10) NULL, [l_linenumber] [bigint] NOT NULL, [l_shipinstruct] [char](25) NULL, [l_comment] [varchar](44) NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [cci_lineitem_cci_stage] ON [dbo].[lineitem_cci_stage]; GO
For the test I decided to load from the staging and update our lineitem_cci table with 1 and with 5 million rows.
First of all let us start with extracting 1 million rows and putting them into the staging table:
TRUNCATE TABLE [dbo].[lineitem_cci_stage]; INSERT INTO [dbo].[lineitem_cci_stage] WITH (TABLOCK) SELECT TOP 1000000 l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM dbo.lineitem_cci;
Let’s MERGE the data from the Stage table into our main one, like a lot of people are doing. Surely this statement won’t hurt my test VM, running on the Azure – Standard DS12 v2 (4 cores, 28 GB memory):
MERGE INTO [dbo].[lineitem_cci] AS [Target]
USING (
SELECT
l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment
FROM dbo.lineitem_cci_stage
) AS [Source]
ON
Target.L_ORDERKEY = Source.L_ORDERKEY
AND Target.L_LINENUMBER = Source.L_LINENUMBER
WHEN MATCHED THEN
UPDATE
SET l_shipdate = Source.l_shipdate, l_orderkey = Source.l_orderkey, l_discount = Source.l_discount, l_extendedprice = Source.l_extendedprice, l_suppkey = Source.l_suppkey, l_quantity = Source.l_quantity, l_returnflag = Source.l_returnflag, l_partkey = Source.l_partkey, l_linestatus = Source.l_linestatus, l_tax = Source.l_tax, l_commitdate = Source.l_commitdate, l_receiptdate = Source.l_receiptdate, l_shipmode = Source.l_shipmode, l_linenumber = Source.l_linenumber, l_shipinstruct = Source.l_shipinstruct, l_comment = Source.l_comment
WHEN NOT MATCHED BY TARGET THEN
INSERT (l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
VALUES (Source.l_shipdate, Source.l_orderkey, Source.l_discount, Source.l_extendedprice, Source.l_suppkey, Source.l_quantity, Source.l_returnflag, Source.l_partkey, Source.l_linestatus, Source.l_tax, Source.l_commitdate, Source.l_receiptdate, Source.l_shipmode, Source.l_linenumber, Source.l_shipinstruct, Source.l_comment);
It took 27.3 seconds on the average to execute this operation (notice again, I am not pitching you here canceled transaction, because of the repeatedly touched row or any of other bugs or inconsistencies) with 29.5 seconds CPU time burnt.
Is it good ?
Is it bad ?
Let us find out by running the same data loading procedure, but this time with the help of DELET & INSERT statements:
DELETE Target FROM dbo.lineitem_cci as Target WHERE EXISTS ( SELECT 1 FROM dbo.lineitem_cci_stage as Source WHERE Target.L_ORDERKEY = Source.L_ORDERKEY AND Target.L_LINENUMBER = Source.L_LINENUMBER ); INSERT INTO dbo.lineitem_cci WITH (TABLOCK) SELECT l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM [dbo].[lineitem_cci_stage];
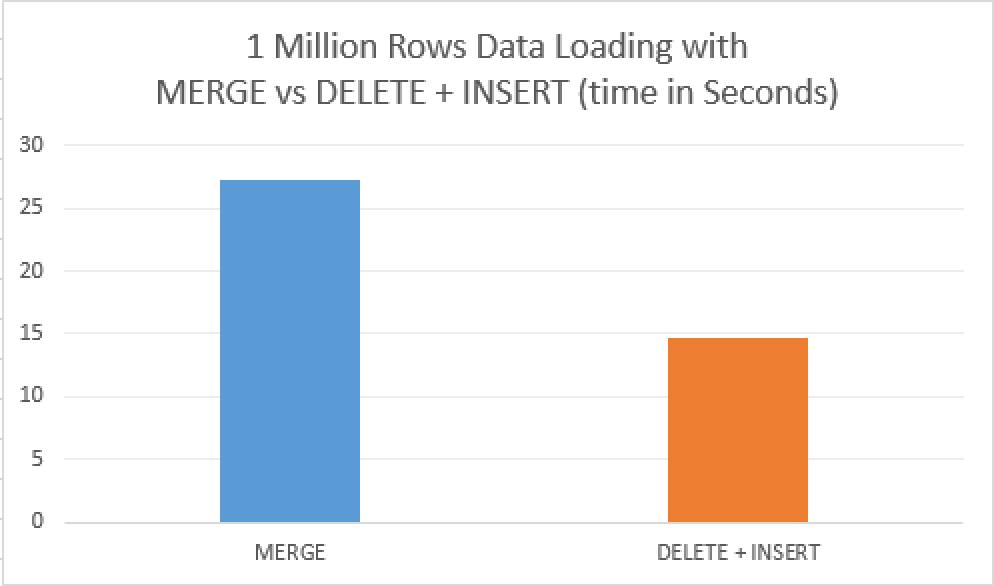 The first statement took 6 seconds while the second took 3.8 seconds of the total time on the average, making the sum to be around 10 seconds. The CPU time burnt on the processing was 6.8 seconds and 7.9 seconds respectively – 14.7 seconds in total. This is a very significant difference (over 2 times), but what happens if we load more data, like 5 million rows, will this have any significant impact ? Will the process be scaled in a linear way, even though we are still loading just around 8% of the total table size.
The first statement took 6 seconds while the second took 3.8 seconds of the total time on the average, making the sum to be around 10 seconds. The CPU time burnt on the processing was 6.8 seconds and 7.9 seconds respectively – 14.7 seconds in total. This is a very significant difference (over 2 times), but what happens if we load more data, like 5 million rows, will this have any significant impact ? Will the process be scaled in a linear way, even though we are still loading just around 8% of the total table size.
TRUNCATE TABLE [dbo].[lineitem_cci_stage]; INSERT INTO [dbo].[lineitem_cci_stage] WITH (TABLOCK) SELECT TOP 5000000 l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM dbo.lineitem_cci;
Rerunning our statements (MERGE & DELETE+INSERT) brings our the following results:
Merge: 556 seconds total time with 162 seconds of the CPU time.
Delete + Insert: 43 seconds total time with 162 seconds of the CPU time.
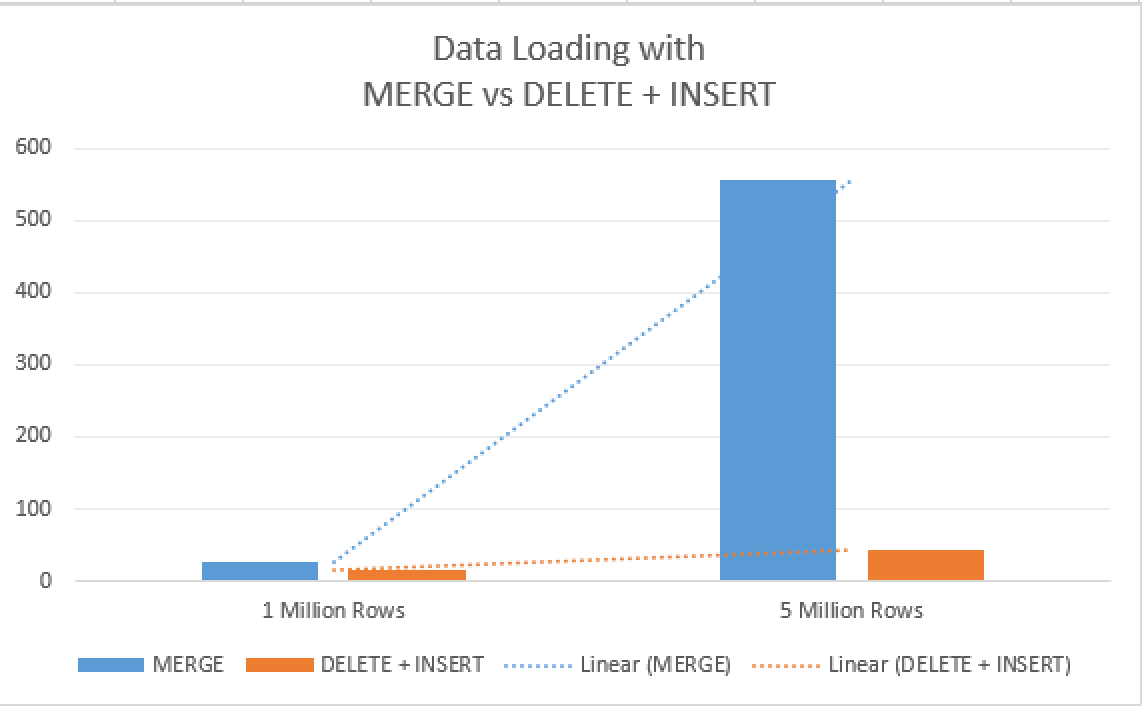
This is how it scales if we increase the amount of data – our 2 times difference was blown away with a new number corresponding almost 13 times difference, making the difference almost 7 times bigger while the amount of data was increased just 5 times ! A very interesting aspect here is that CPU Time has increased around 5 times for the MERGE statement (29.5 vs 161 seconds), meaning that the real bottleneck had nothing to do with the CPU, but most probably with the available memory and the disk.
Let’s consider the execution plans for both of the methods:

The MERGE execution plan has 2 distinct regions (parallel one where the data is being read and sorted (34% of the execution plan cost estimated) and the serial one for the data insertion into the Columnstore Index with single-threaded sorting (why? what for? this makes no sense since we do not have any forced data order within Columnstore Index).
This execution plan has total estimated cost of 1572!
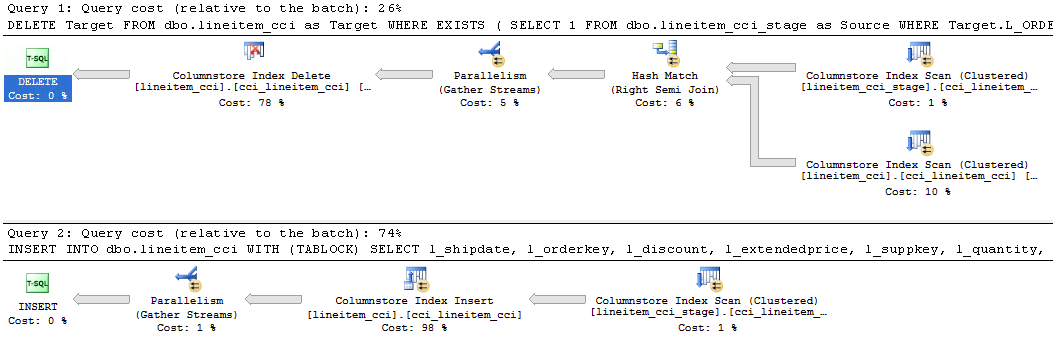
The DELETE + INSERT has data reading processing being executed within Batch Execution Mode, with predicates being pushed into the Columnstore Index Scan of the lineitem_cci table with the help of the bitmap bloom filter. The rows deletion, insertion and parallelism stream gathering is being executed within the Row Execution Mode, but those are very few operations.
This execution plan has total estimated cost of 400 (297 + 103), a huge difference to the MERGE!
Think what would happened if someone decide to do a FULL LOAD of the 60 million rows through the MERGE statement. A good theory here is that our TempDB would die before this statement would complete.
The reasons
First of all and the most importantly, the Columnstore Indexes do not like UPDATEs, nor they do truly understand them in the sense that Rowstore Indexes have a built-in functionality that prevents a row being updated if the new values are equal to the current ones, while Columnstore Indexes treat any update as a Delete + Insert operation, thus updating the row in any case. This operation reflects not only on the Table structure, but also on the transaction log – the number of writes will be highly different for the Columnstore Index then for the traditional Rowstore structure.
When executing UPDATE or MERGE statement against the Columnstore Indexes, we loose the capability of inserting data through Bulk Load API directly into the compressed Row Groups and doing our inserts into the uncompressed (2016+) or compressed (2014) Delta-Stores, thus making process incredibly slow when compared to the DELETE+INSERT combination, where inserts can take advantage of the Bulk Load API.
Another aspect are the Memory Grants, with MERGE we are pulling all data into Memory where at least 2 sort iterators will take place, and this is one of the reasons why the 5 Million Rows process took so much time – it was spilling into TempDB, this is a huge price to pay for dealing with big numbers of rows directly.
Let us reload all the data from the original rowstore table and go through all the steps:
SET NOCOUNT ON; TRUNCATE TABLE [dbo].[lineitem_cci]; INSERT INTO [dbo].[lineitem_cci] WITH (TABLOCK) SELECT l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM dbo.lineitem;
Lets put 1 Million Rows into our staging table:
TRUNCATE TABLE [dbo].[lineitem_cci_stage]; INSERT INTO [dbo].[lineitem_cci_stage] WITH (TABLOCK) SELECT TOP 1000000 l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM dbo.lineitem_cci;
Before proceeding further, let’s see how the Row Groups are looking in our lineitem_cci table, I am using my CISL stored procedure for that:
exec dbo.cstore_GetRowGroups @tableName = 'lineitem_cci';
![]()
We have 110 Row Groups because of the Dictionary Pressure for our 60 Million Rows table, and all of them are compressed – no Delta-Stores, no Fragmentation or whatsoever.
Let’s also measure the impact on the transaction log, and for that I will force CHECKPOINT before advancing with testing the process impact:
checkpoint; select sum([log record length]) as LogSize from fn_dblog (NULL, NULL);
Now, let’s run the MERGE statement:
MERGE INTO [dbo].[lineitem_cci] AS [Target]
USING (
SELECT
l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment
FROM dbo.lineitem_cci_stage
) AS [Source]
ON
Target.L_ORDERKEY = Source.L_ORDERKEY
AND Target.L_LINENUMBER = Source.L_LINENUMBER
WHEN MATCHED THEN
UPDATE
SET l_shipdate = Source.l_shipdate, l_orderkey = Source.l_orderkey, l_discount = Source.l_discount, l_extendedprice = Source.l_extendedprice, l_suppkey = Source.l_suppkey, l_quantity = Source.l_quantity, l_returnflag = Source.l_returnflag, l_partkey = Source.l_partkey, l_linestatus = Source.l_linestatus, l_tax = Source.l_tax, l_commitdate = Source.l_commitdate, l_receiptdate = Source.l_receiptdate, l_shipmode = Source.l_shipmode, l_linenumber = Source.l_linenumber, l_shipinstruct = Source.l_shipinstruct, l_comment = Source.l_comment
WHEN NOT MATCHED BY TARGET THEN
INSERT (l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
VALUES (Source.l_shipdate, Source.l_orderkey, Source.l_discount, Source.l_extendedprice, Source.l_suppkey, Source.l_quantity, Source.l_returnflag, Source.l_partkey, Source.l_linestatus, Source.l_tax, Source.l_commitdate, Source.l_receiptdate, Source.l_shipmode, Source.l_linenumber, Source.l_shipinstruct, Source.l_comment);
After this MERGE statement finishes we can measure the impact with the 2 statements for the transaction log and for the Row Groups
select sum([log record length]) as LogSize from fn_dblog (NULL, NULL); exec dbo.cstore_GetRowGroups @tableName = 'lineitem_cci';
The transaction log impact in my case was around 457 MB, 457.764.460 bytes to be precise.
As for the Row Groups, you can see the result below – we have an open Delta-Store even though we have inserted 1 Million Rows (through Bulk Load API 102.400 rows will be enough to trigger fast direct insert), while we have fragmented our table with 1 million deleted rows, that are marked within Deleted Bitmap:
![]()
Let us measure the impact for the DELTE & INSERT operations:
TRUNCATE TABLE [dbo].[lineitem_cci]; INSERT INTO [dbo].[lineitem_cci] WITH (TABLOCK) SELECT l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM dbo.lineitem; -- Load 1 Million Rows into the staging table TRUNCATE TABLE [dbo].[lineitem_cci_stage]; INSERT INTO [dbo].[lineitem_cci_stage] WITH (TABLOCK) SELECT TOP 1000000 l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM dbo.lineitem_cci; -- CHECKPOINT and Verify the Transaction Log occupied space checkpoint; select sum([log record length]) as LogSize from fn_dblog (NULL, NULL); -- DELETE & INSERT DELETE Target FROM dbo.lineitem_cci as Target WHERE EXISTS ( SELECT 1 FROM dbo.lineitem_cci_stage as Source WHERE Target.L_ORDERKEY = Source.L_ORDERKEY AND Target.L_LINENUMBER = Source.L_LINENUMBER ); INSERT INTO dbo.lineitem_cci WITH (TABLOCK) SELECT l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment FROM [dbo].[lineitem_cci_stage];
After the whole train of statements finishes, we have the following situation: 207 MB impact on the transaction log (207.578.692) while 4 additional compressed Row Groups were created through the Bulk Load API.
To see more details, let’s use the following statement:
exec dbo.cstore_GetRowGroupsDetails @tableName = 'lineitem_cci', @showTrimmedGroupsOnly = 1;

You can see the imperfect distribution of the data between the newest Row Groups 250002,250002,249998,249998 that in sum represent our 1 Million Rows that we have loaded.
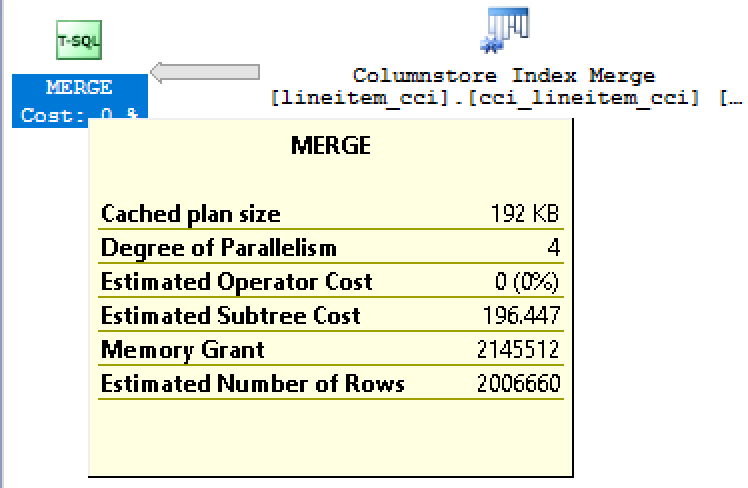 Regarding the memory grant – for 1 Million Rows we have actually spent over 2 GB, as you can see on the picture on the left side. Loading 5 Million Rows would scale the needed memory to 11 GB, and with my current VM having maximum of 28 GB (and even I would set MAX MEMORY to it – because I limit SQL Server memory on lower numbers for such configuration) with the default combination of the Resource Governor we shall be limited with 7GB for a single query.
Regarding the memory grant – for 1 Million Rows we have actually spent over 2 GB, as you can see on the picture on the left side. Loading 5 Million Rows would scale the needed memory to 11 GB, and with my current VM having maximum of 28 GB (and even I would set MAX MEMORY to it – because I limit SQL Server memory on lower numbers for such configuration) with the default combination of the Resource Governor we shall be limited with 7GB for a single query.
On the other side, for the DELETE & INSERT we do not need any other memory grants, besides the basic requirement of feeling 1 Row Group into the Memory.
Final Thoughts
Say a big fat NO to MERGE. Just say NO, NO, NO!
Do no use it for the Columnstore Indexes for all the reasons, for all the bugs and consistency problems that it brings.
Testing it in production will be a very, very & very expensive option.
to be continued with Columnstore Indexes – part 100 (“Identity”)
looks like a bad implementation; maybe they will fix it.
Hi Joe,
given all the problems that MERGE I do not hold my breath ;)
Best regards,
Niko
Great post – so I’m just testing implementation of going from non-clustered to clustered columnstore as just having upgraded from 2012 to 2016. I just ran a test of 150 million record insert verses a merge command for an empty table with clustered columnstore. The merge took 2 hours 32 minutes and the insert as select took 3 hours 13 minutes. Quite a different result than your test. I wonder if your test isn’t a pattern for larger columnstores and in fact merge may work better in those scenarios? All I know is my test shows that switching to plain delete/insert would be worse not better if on a whole load. Next I’ll test merge into an existing fact table a small set of changes and see which is faster. As for documented issues with merge – never encountered them – I’ve used merge for many years with never a problem as the issues documented in the link you provided seem to be edge cases that many if not most people don’t have.
Hi Gary,
there will be scenarios where MERGE might be faster/more efficient, but generally, I keep on seeing the scenario I described in this blog post. Even today for a client I have re-written their MERGE into UPDATE & INSERT, getting a very significant performance improvement.
Best regards,
Niko
Looking at your code, I did not see any place that you took your cardinality errors in it. The merge statement will handle this, which are going to need some different code and just the two simple statements you used.