Continuation from the previous 87 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Getting Data into the Database is one essential process, no matter if you are working with an OLTP application or if you are a professional Data Warehousing developer, or any other data jokey (or data wrangler).
Making this process function to the maximum velocity is essential, especially if you are working with large number of processes or large volumes of data. In the current age of the global processes and exploration of the data value this skill is essential for any data professional. The skill of knowing how to load can be there, but what about the database, what about SQL Server and the columnstore indexes ? In the blog post Columnstore Indexes – part 43 (“Transaction Log Basics”) related to the SQL Server 2014, I have shown that Columnstore Indexes were more efficient in comparison to Rowstore ones, when loading data in small transactions, but once we tried Minimal Logging, the situation would change with the traditional Rowstore being quite more effective than the Columnstore Indexes.
In SQL Server 2016, Microsoft has implemented the Minimal Logging for Columnstore Indexes and I am excited to put it to the test and to see if this will be another barrier where Columnstore Indexes has successfully tackled the Rowstore indexes.
For the setup, I will use the following script, where the source table dbo.TestSource will get 1.500.000 rows, which will be used to seed the data into our test tables: dbo.BigDataTestHeap (Heap) & dbo.BigDataTest (Clustered Columnstore)
create table dbo.TestSource( id int not null, name char (200), lastname char(200), logDate datetime ); -- Loading 1.500.000 Rows set nocount on declare @i as int; set @i = 1; begin tran while @i <= 1500000 begin insert into dbo.TestSource values (@i, 'First Name', 'LastName', GetDate()); set @i = @i + 1; end; commit; -- Create a HEAP create table dbo.BigDataTestHeap( id int not null, name char (200), lastname char(200), logDate datetime ); -- Crete our test CCI table create table dbo.BigDataTest( id int not null, name char (200), lastname char(200), logDate datetime ); -- Create Columnstore Index create clustered columnstore index PK_BigDataTest on dbo.BigDatatest;
Now let's do the very same test as before - loading 10 rows into an empty (truncated) heap table dbo.BigDataTestHeap, while not using Minimal Logging.
truncate table BigDataTestHeap; checkpoint -- Load 10 rows of data from the Source table declare @i as int; set @i = 1; begin tran while @i <= 10 begin insert into dbo.BigDataTestHeap --with (TABLOCK) select id, Name, LastName, logDate from dbo.TestSource where id = @i; set @i = @i + 1; end; commit; -- you will see a corresponding number (10) of 512 bytes long records in T-log select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTestHeap' order by [Log Record Length] Desc; -- 5K+ of transaciton log length select sum([log record length]) as LogSize from fn_dblog (NULL, NULL) where allocunitname='dbo.BigDataTestHeap';
As you can see on the picture below, we have exactly 10 entries with the log record length of 512 bytes and the total length of the 5.576 bytes.
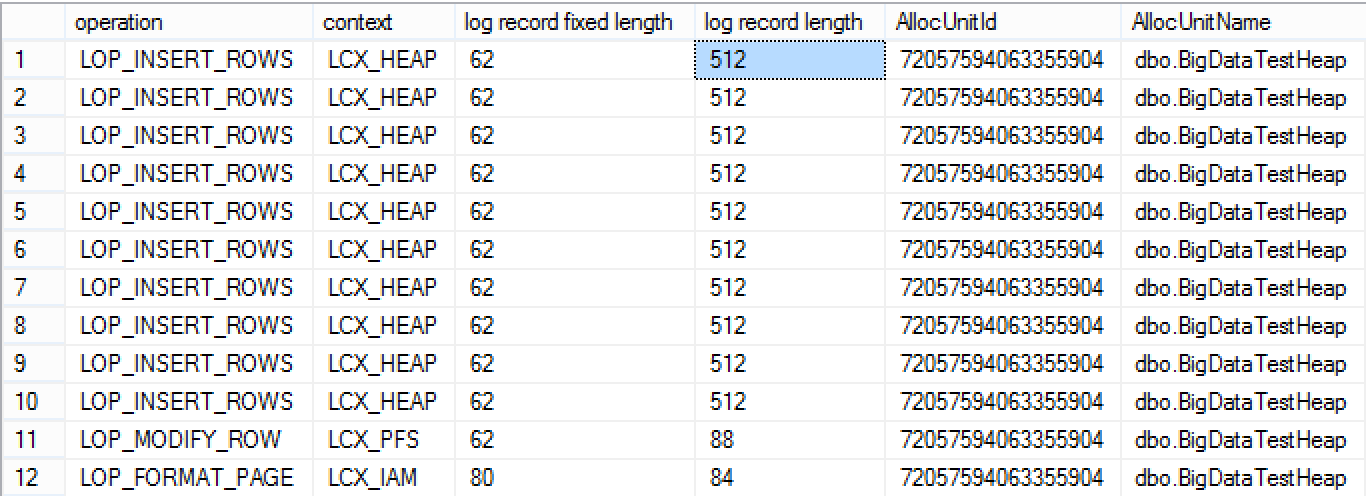
The rowstore table functionality did not changed since SQL Server 2014, but let's check the Columnstore tables. For that purpose, let's load the same 10 records and see if something has changed since SQL Server 2014:
truncate table dbo.BigDataTest; checkpoint declare @i as int; set @i = 1; begin tran while @i <= 10 begin insert into dbo.BigDataTest select id, Name, LastName, logDate from dbo.TestSource where id = @i; set @i = @i + 1; end; commit;
When starting to analyse the transaction log, you will immediately notice some very important changes that were implemented under the hood - the reference "full name of the table + name of the Clustered Columnstore Index" does not work any more, Microsoft has changed some details: they have added indication of the destination (Delta Store) and so the allocation unit name returned by the fn_dblog function for our case is dbo.BigDataTest.PK_BigDataTest(Delta) and instead of the previous 140 bytes the entries we have 524 bytes used for each of the log records:
-- Check on the length select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname like 'dbo.BigDataTest.PK_BigDataTest(Delta)' order by [Log Record Length] Desc select sum([log record length]) as LogSize from fn_dblog (NULL, NULL) where allocunitname='dbo.BigDataTest.PK_BigDataTest(Delta)';
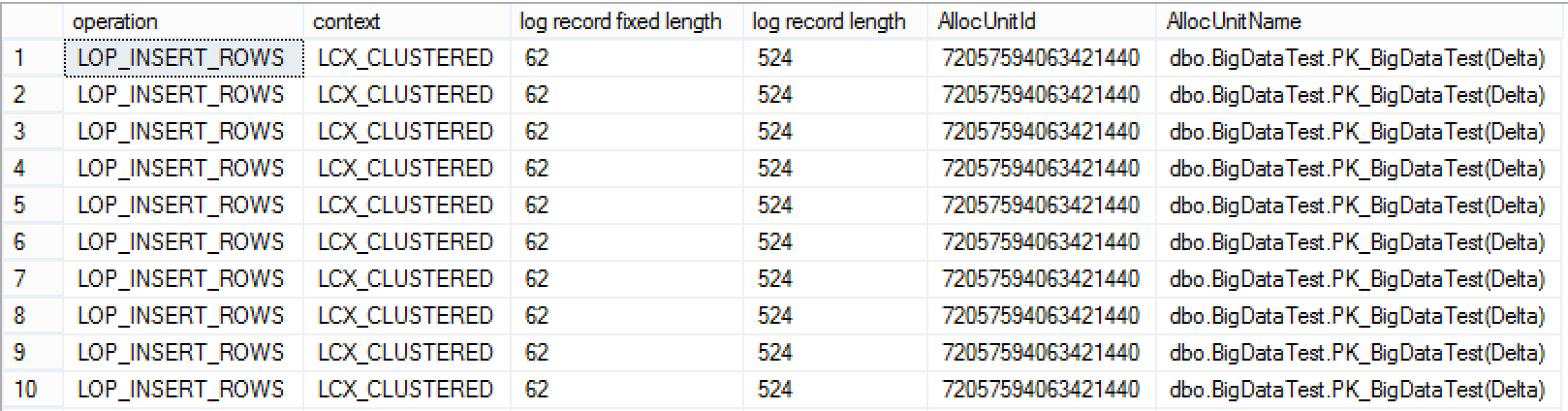
This is a very serious change under the hood for those migrating from SQL Server 2014 to SQL Server 2016, which will give a serious impact if loading data in the old way and expecting that it will function exactly as before. Overall we are talking about 5.696 bytes allocated in the log for the Columnstore Indexes table, instead of the 1.756 bytes that the same information occupies in SQL Server 2014.
I will make a serious assumption that this changes have a lot to do with the internal changes of SQL Server 2016, that allow to have multiple secondary nonclustered rowstore indexes on the tables with Clustered Columnstore Indexes.
Another important thing to hold in mind is that in SQL Server 2016, the Delta-Stores are no more page-compressed, meaning that the impact on the disk will be even bigger than before. To confirm the compression of our Delta-Store, let's use the following query - checking on the new DMV sys.internal_partitions:
select object_name(object_id), internal_object_type, internal_object_type_desc, data_compression, data_compression_desc,* from sys.internal_partitions where object_name(object_id) = 'BigDataTest'
![]()
From the image above you can see that the Delta-Store is not compressed anymore, meaning that it will definitely occupy more space on the disk, while using less CPU cycles.
Microsoft has optimised some of the operations for the data insertion (about some of them watch out for the upcoming blog post), and even the total length of the Clustered Columnstore Index record insertion is still smaller than the Rowstore counterpart, but the difference with the SQL Server 2014 can be a serious surprise for unprepared.
Minimal Logging in Columnstore Indexes 2016
Let's move onto the Minimal logging, that was implemented in SQL Server, but before that let's pick up the base line with Rowstore Indexes, while loading 10.000 rows into our HEAP test table:
truncate table BigDataTestHeap; checkpoint; insert into dbo.BigDataTestHeap with (TABLOCK) select top 10000 id, Name, lastname, logDate from dbo.TestSource order by id; select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTestHeap' order by [Log Record Length] Desc; -- Measure the transaction log length select sum([log record length]) as LogSize from fn_dblog (NULL, NULL) where allocunitname='dbo.BigDataTestHeap';
Without any huge surprises, we still have 92 bytes per record as in SQL Server 2014:
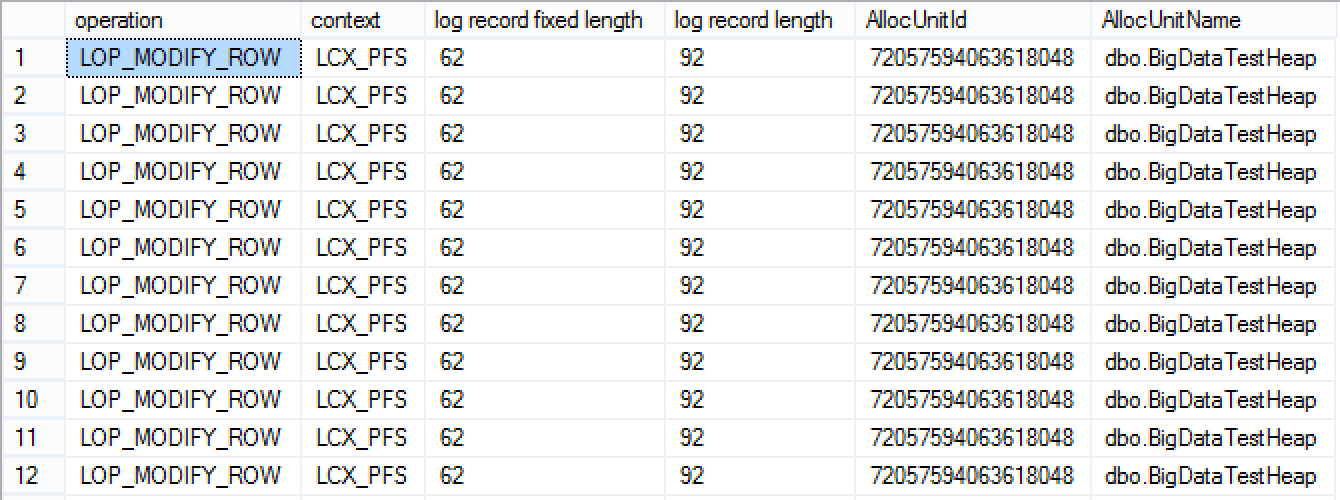
The total length of the inserted transaction log records was 85.704 bytes, which is different (more space occupied) to the SQL Server 2014, but I will leave this space for others to investigate.
Time for the Clustered Columnstore Indexes test, where we punch 10.000 rows at a time:
truncate table dbo.BigDataTest; checkpoint insert into dbo.BigDataTest with (TABLOCK) select top 10000 id, Name, lastname, logDate from dbo.TestSource order by id; -- Check on the individual length select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTest.PK_BigDataTest(Delta)' order by [Log Record Length] Desc -- Total Length select sum([log record length]) as LogSize from fn_dblog (NULL, NULL) where allocunitname='dbo.BigDataTest.PK_BigDataTest(Delta)'
There are a lot of different things to discover here:
- the good old "LCX_CLUSTERED" context is still here showing like in the singleton insertion a huge increase of the record length, but do not get too scared, because after a very reasonable number of rows (in my case just 76) you will start seeing LCX_PFS (page free space) allocation context with very reasonable and very comparable to the rowstore 92 bytes:
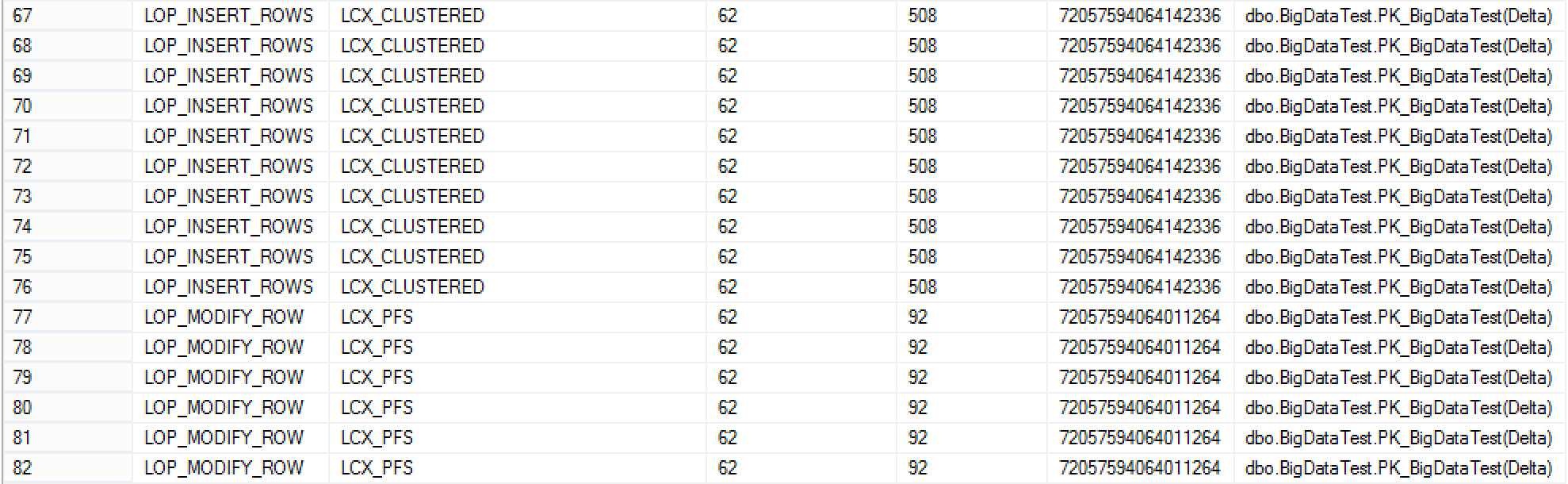
- for 10.000 rows we have quite a variation of the context and so many different operations, including LOP_MODIFY_HEADER, LOP_INSERT_ROWS & LOP_FORMAT_PAGE, with context switching between LCX_INDEX_INTERIOR, LCX_HEAP & LCX_BULK_OPERATION_PAGE. Wait did I see BULK here somewhere?
Ladies and gentlemen! That's quite a difference to SQL Server 2014!
We better check the total length of the transaction log to see the final result: 384.032 bytes! Ok, that is significantly more than for the rowstore heap table for sure, but what about the comparison to the SQL Server 2014 ? Did this minimal logging bring any improvement ?
Well ... :)
In SQL Server 2014 we had 1.255.224 bytes spent on the transaction log - meaning over 1.2 MB, meaning around 3 times more, for the Delta-Store insertion! For such a simple table, this is a huge improvement, but let's take a look at the total length of the transaction log entries in both environments (SQL Server 2014 & SQL Server 2016)
select sum([log record length]) as LogSize from fn_dblog (NULL, NULL)
The other entries (not directly for the Delta-Store) within SQL Server 2016 make the log grow, but the total transaction log length for it is 670.648 bytes, while for SQL Server 2014 the transaction log length is 1.263.680 is around 2 times bigger.
So yeah, in this sense - it really "Just Runs Faster". :)

But let's take a look at what objects (internal partitions) we have created within our Clustered Columnstore Table:
select object_name(object_id), internal_object_type as objType, rows, internal_object_type_desc, data_compression, data_compression_desc,* from sys.internal_partitions where object_name(object_id) = 'BigDataTest'

Wow, we have 4 Delta-Stores with just 10.000 rows! Like I have shown in Columnstore Indexes – part 63 ("Parallel Data Insertion") over a year ago, SQL Server will take advantage of our available cores and will execute the insertion of the data in parallel, and here is the actual execution plan for the 10.000 rows insertion query showing the parallel insertion into the clustered columnstore index:

To see it from the Row Groups perspective, I will use my CISL library:
exec cstore_GetRowGroupsDetails @tableName = 'BigDataTest'
and since I have 4 CPU cores for this test VM, that's exactly the number of the Delta-Stores, that I will get as the final result:

2.500 rows per each of our Delta-Store!
Bulk Load in Columnstore Indexes 2016
Well, we have received Delta-Stores because the amount of data was way too small for loading directly into a compressed Row Group, and so lets load whole 1.5 million rows for seeing what the bulk load operation will bring:
In the script below, I am loading 1.5 million rows of data into our table with a Clustered Columnstore Index while holding a TABLOCK hint:
truncate table dbo.BigDataTest; checkpoint insert into dbo.BigDataTest with (TABLOCK) select id, Name, lastname, logDate from dbo.TestSource order by id; -- Check on the length of the single record select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTest.PK_BigDataTest' order by [Log Record Length] Desc -- Measure the total length select sum([log record length]) as LogSize from fn_dblog (NULL, NULL) where allocunitname='dbo.BigDataTest.PK_BigDataTest'
Notice that for checking the transaction log record length, I have used the syntax similar to SQL Server 2014, without the mentioning of the Delta-Store, because we are loading data directly into the compressed Row Groups.
Check out the output of the single transaction log records:

Each record has just 92 bytes, exactly like a Row Store HEAP table!
The total length of the generated transaction log in my test case was 1.493.178 bytes - 1.5 MB!!! I have loaded 1.5 million records and spent 1.5 million bytes on it ? This is truly incredible!
Or is it ? :)
What about the Rowstore HEAP Table:
truncate table BigDataTestHeap; checkpoint; insert into dbo.BigDataTestHeap with (TABLOCK) select id, Name, lastname, logDate from dbo.TestSource order by id; -- Measure transaciton log length select sum([log record length]) as LogSize from fn_dblog (NULL, NULL)
Well, we have 2.182.720 bytes in the transaction log, which is significantly more than for the Clustered Columnstore Table: 2.1 MB vs 1.5 MB!

TABLOCK? Do we still need it for Columnstore Tables?
Given that Microsoft implemented those incredible performance improvements for the parallel data insertion one should always use the TABLOCK hint, right ? Well, there is no reason to think otherwise ... Unless you want to make sure that it is so :)
Let's load the same data into our table, but this time WITHOUT the TABLOCK hint:
truncate table dbo.BigDataTest; checkpoint insert into dbo.BigDataTest --with (TABLOCK) select id, Name, lastname, logDate from dbo.TestSource order by id; -- Check on the length select top 1000 operation,context, [log record fixed length], [log record length], AllocUnitId, AllocUnitName from fn_dblog(null, null) where allocunitname='dbo.BigDataTest.PK_BigDataTest' order by [Log Record Length] Desc -- Check the log generated by the dbo.BigDataTest row groups select sum([log record length]) as LogSize from fn_dblog (NULL, NULL) where allocunitname='dbo.BigDataTest.PK_BigDataTest'
Imagine, that the footprint generated by the dbo.BigDataTest table was just 298.296 bytes, with the total size of the produced transaction log was 470.244 bytes, which is significantly smaller than anything else - Rowstore HEAP Table or Columnstore table that was used with a TABLOCK hint:

And of course you should keep in mind, that the number of created Row Groups will be smaller, since we are not using all available cores and the insertion process is single-threaded, making this process more assertive and as you will see in the results, compressing much better:
exec dbo.cstore_GetRowGroupsDetails @tableName = 'BigDataTest'
![]()
We have just 2 Row Groups instead of 4 and our overall occupied space is lower, since we get for the smaller number of row groups better global & local dictionaries.
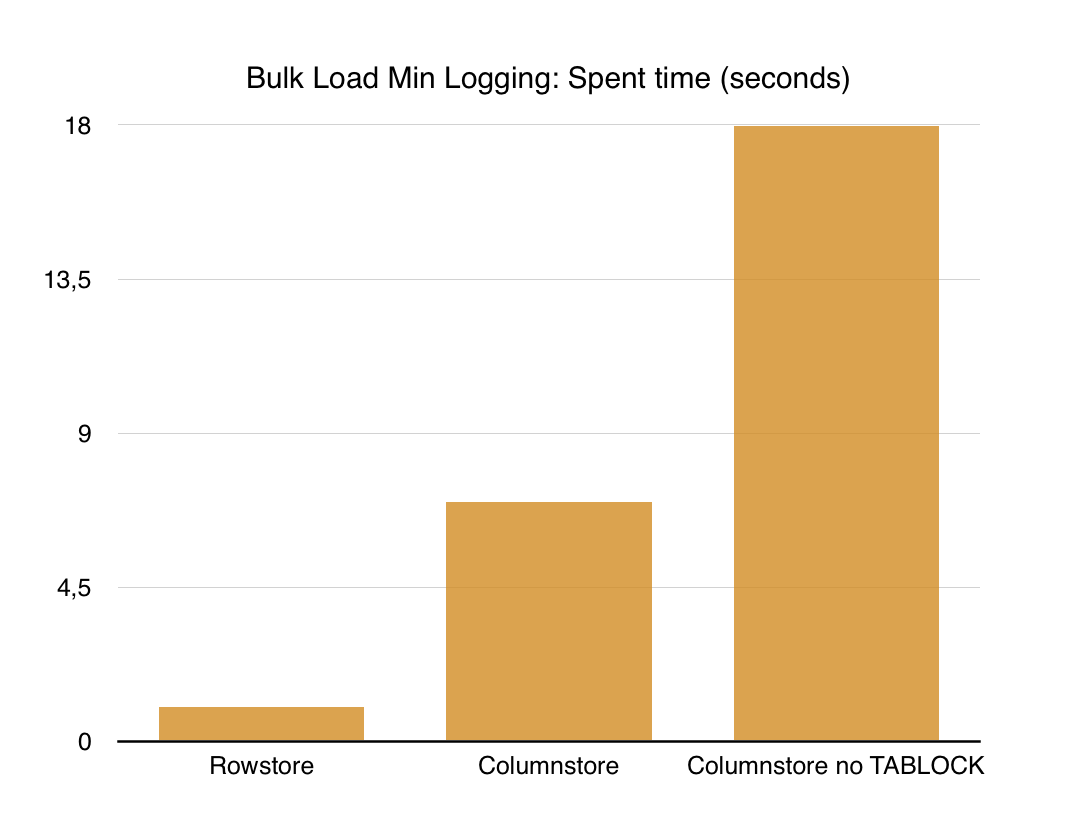 Another word should be added about the total elapsed time. It IS different. It will make any question about loading strategy for the columnstore indexes to go - "IT DEPENDS ... ".
Another word should be added about the total elapsed time. It IS different. It will make any question about loading strategy for the columnstore indexes to go - "IT DEPENDS ... ".
It will depend on what you are trying to achieve and what is your slowest element in the system.
If you have a rather slow drive or loading incredible amounts of data that will make all other elements looking relatively unimportant, then loading the data with no TABLOCK can be quite an easy choice. If your system enjoys a very fast drive and the IO access times are less of a problem than for all means consider applying TABLOCK, while of course bearing in my mind that having TABLOCK on your table means that until the data insertion process is over the table is not accessible for the queries, trying to extract the consistent information from it.
Memory-Optimised Tables
Memory-Optimised Tables provide a lot of advantages by optimising the transaction log impact and providing 100% In-Memory access for data-processing and since SQL Server 2014 people are using them for some of the staging table scenarios.
Let's run a simple test on the persistent InMemory table, by loading the very same 1.5 million rows:
drop table if exist dbo.BigDataTestInmemory; create table dbo.BigDataTestInmemory( id int not null, name char (200), lastname char(200), logDate datetime, CONSTRAINT [PK_BigDataTestInmemory] PRIMARY KEY NONCLUSTERED ( id ), INDEX CCI_BigDataTestInmemory CLUSTERED COLUMNSTORE )WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
The In-Memory tables are required to have a primary key - hence the nonclustered index, meaning that in practice if applying a Clustered Columnstore Index on it, it will become a reasonably complex table with more indexes then a simple Disk-Based Clustered Columnstore Table.
Also, please notice that Memory-Optimised tables do not support TABLOCK hint currently, and so the only scenario here I can try is the one without this hint:
delete from dbo.BigDataTestInmemory; checkpoint; insert into dbo.BigDataTestInmemory select id, Name, lastname, logDate from dbo.TestSource order by id;
The amount of log records that this operation generates is absolutely epic (100s of MBs), and the impact on the disk is something that simply kills any potential application of the current implementation. The overall elapsed time is comparable to the Clustered Columnstore Table with no TABLOCK hint, since it runs with a single thread:

It is simply not worth considering because the data will not land into the compressed row group, but instead in the Tail Row Group (Delta-Store), requiring additional steps for getting the data compressed ... No, it is not worth considering.
Oh and the Schema_only option ?
As I have mentioned in Columnstore Indexes – part 78 ("Temporary Objects") - they are still not supported, unfortunately.
Final Thoughts
You can't have more functionality without affecting some parts of the product. SQL Server Developer team is doing an incredible job of implementing awesome new stuff. (Yeah, I know that sounds like a fanboy's talk, and trust me I am one! :))
By loading big amounts of data with Bulk Load API, you will get a huge advantage in the terms of Minimal Logging - it will use less space in the transaction log even when compared to a Rowstore HEAP.
Think twice wether you want to use TABLOCK hint for loading data into columnstore indexes.
Pro tip: when working with Columnstore Indexes in SQL Server 2016: Love your staging tables and use a lot of Bulk Inserts ;)
to be continued with Columnstore Indexes – part 89 ("Memory-Optimised Columnstore Limitations 2016")