Continuation from the previous 84 parts, the whole series can be found at https://www.nikoport.com/columnstore/
I wanted to write a blog post on some of the changes that were implemented in SQL Server 2016, that might affect workloads migrated from SQL Server 2012 & SQL Server 2014.
Some of the possibilities of acquiring the Batch Execution Mode in the 2012 & 2014 versions of SQL Server, especially in the indirect way are now removed from the product…
To my understanding, this happens for preventing the OLTP Systems from spending whole their resources on analytical style of processing, but in my opinion this will affect the DWH and the Hybrid scenarios mostly, plus some of the edge cases with mixed environments (short-range lookups joining with big tables).
I will use my favourite free Database ContosoRetailDW from Microsoft, to show what some of those changes are about.
Let’s roll out a freshly restored version of it, with upgrading the data files size and most importantly setting the compatibility level to 130, which corresponds to the SQL Server 2016:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
As the next step, let us create a Nonclustered Columnstore Index on the FactOnlineSales table:
CREATE NONCLUSTERED COLUMNSTORE INDEX [ncci_factonlinesales] ON [dbo].[FactOnlineSales] ( [OnlineSalesKey], [DateKey], [StoreKey], [ProductKey], [PromotionKey], [CurrencyKey], [CustomerKey], [SalesOrderNumber], [SalesOrderLineNumber], [SalesQuantity], [SalesAmount], [ReturnQuantity], [ReturnAmount], [DiscountQuantity], [DiscountAmount], [TotalCost], [UnitCost], [UnitPrice], [ETLLoadID], [LoadDate], [UpdateDate] );
Now to the test query, where I will look for top 1000 product based on their sales in USD since the year 2014:
select top 1000 prod.ProductName, sum(sales.SalesAmount) from dbo.FactOnlineSales sales with(index([PK_FactOnlineSales_SalesKey])) inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey inner join dbo.DimCurrency cur on sales.CurrencyKey = cur.CurrencyKey inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where cur.CurrencyName = 'USD' and prom.EndDate >= '2004-01-01' group by prod.ProductName order by sum(sales.SalesAmount) desc option (recompile);
This looks like a rather neat basic reporting query that one would meet on a daily basis when working in BI/DWH. The only thing that would differ from a normal plan is that we are forcing the Rowstore PK Index on the FactOnlineSales rather then using the created Columnstore Index. For a number of reasons, when we can’t get out of Query Processor what we need, we have to force the execution with the Index hint. Sometimes Query Processor will even select the path of using different index instead of the one that makes sense (well, because SURPRISE! Nothing is Perfect).
It takes a big amount of time to process this query – 12 seconds on my VM with a hot memory.
Considering it’s execution plan below, you will notice that there is nothing too much suspicious:

Well, imagine that – on the same VM, on the latest SQL Server 2014 version it takes 5.5 Seconds to run this very query! What ? 5.5 Seconds on SQL Server 2014 vs 12 Seconds on SQL Server 2016? So it’s not faster ? Captain, what the heck is the problem with this boat ? :)
Take a look at the execution plan from the SQL Server 2014:
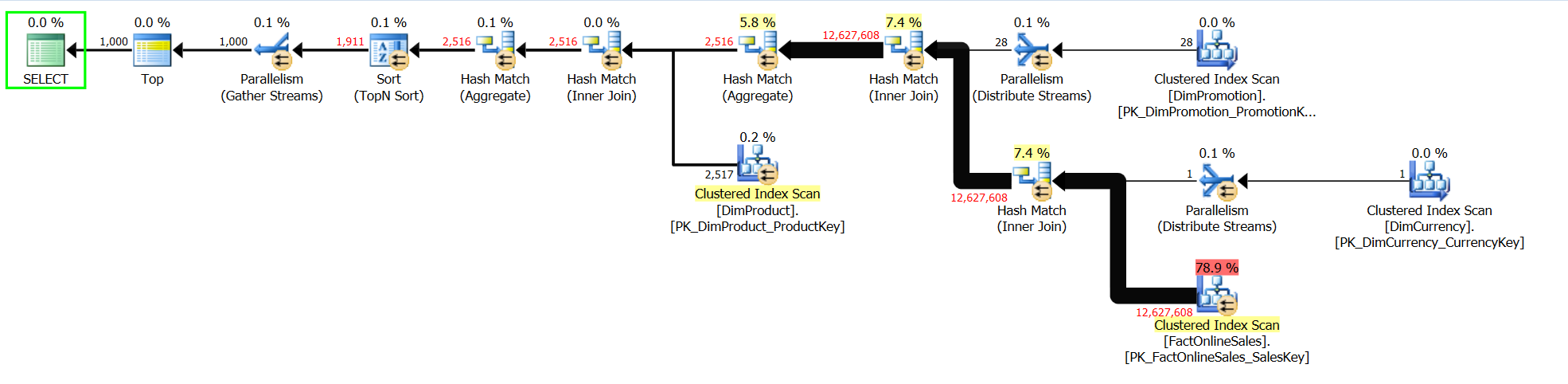
The difference I see on the first sight is that there is a Parallelism Repartition Stream iterator near the Clustered Index Scan for the DimProduct Dimension. It can’t make the execution times going havoc like they do!
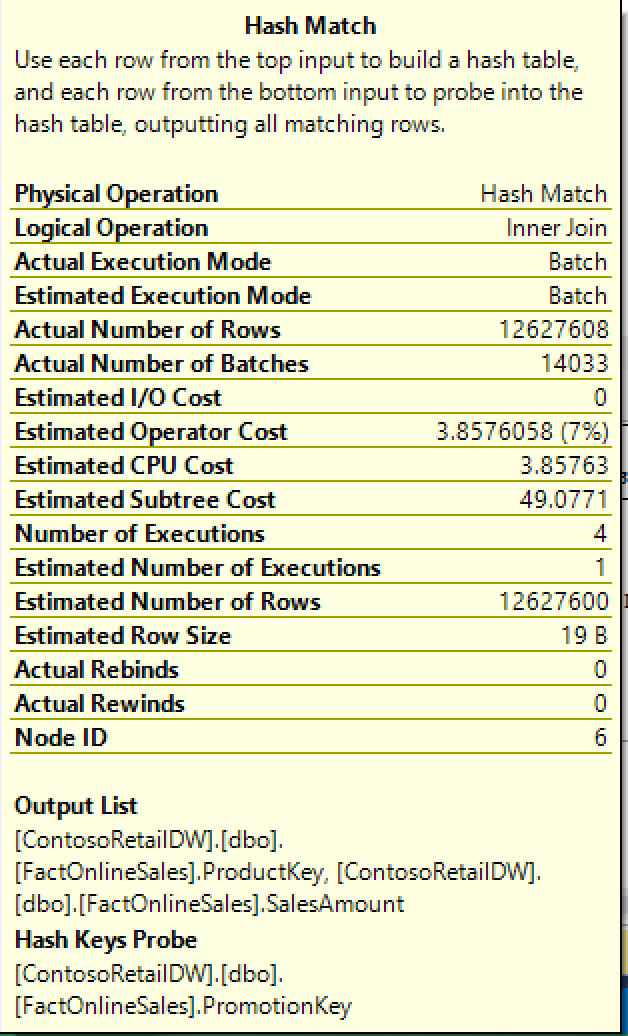 I will share a little secret with you – it’s all about the Batch Execution Mode in SQL Server 2014: all those Hash Match iterators are running in Batch Mode, even though we are not using Columnstore Index anywhere.
I will share a little secret with you – it’s all about the Batch Execution Mode in SQL Server 2014: all those Hash Match iterators are running in Batch Mode, even though we are not using Columnstore Index anywhere.
In SQL Server 2016 this old (since 2012) functionality has been removed and once you are running your queries in the compatibility level of 130 (SQL Server 2016), your queries that were taking advantage of it – will be running significantly slower.
There is a fast & brutal solution for that problem – set your compatibility level to 120, but do not go there until you have understood all the implications: some of the most important and magnificent improvements for the Batch Execution Mode are functioning only if your database is set to compatibility level 130: single threaded batch mode, batch sorting, window functions, etc.
From what I know, there is no way you can have all of those functionalities working together under the same hood and enjoy the old way of getting Batch Execution Mode without the presence of the Columnstore Index.
For the sake experiment, let’s lower the compatibility level:
USE master
GO
ALTER DATABASE [ContosoRetailDW]
SET COMPATIBILITY_LEVEL = 120;
GO
Running the same query against my SQL Server 2016 instance, will bring me some very interesting results:
select top 1000 prod.ProductName, sum(sales.SalesAmount) from dbo.FactOnlineSales sales with(index([PK_FactOnlineSales_SalesKey])) inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey inner join dbo.DimCurrency cur on sales.CurrencyKey = cur.CurrencyKey inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where cur.CurrencyName = 'USD' and prom.EndDate >= '2004-01-01' group by prod.ProductName order by sum(sales.SalesAmount) desc option (recompile);
It took just 4.3 Seconds!
…
Here is an execution plan for that:
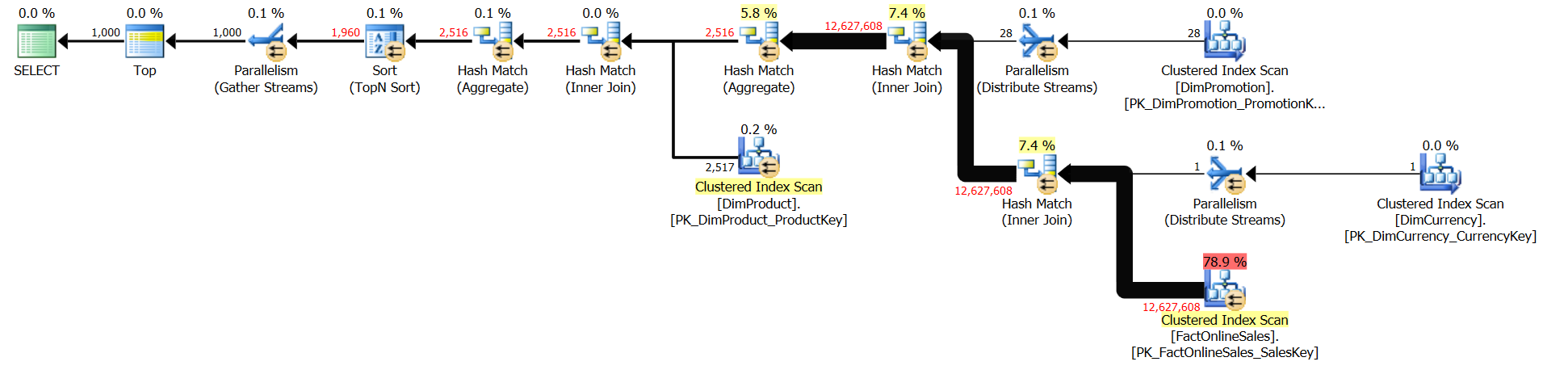
Yes, it looks pretty much like it does in SQL Server 2014.
Start crying now. Yes, it runs much faster in SQL Server 2016 over SQL Server 2014 (around 20%) even though because of the lack of 130 Compatibility Level support, the Sort iterator is running in the Row Execution Mode (meaning it can run even faster).
Such options as a IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX and others will be following the very same path – they will loose the Batch Execution Mode once you upgrade to the 130 Compatibility Level.
The biggest problem with this situation is that things that were running fast – will be running slow and there is no reasonable way to solve this, because when migrating to SQL Server 2016, my goal is to bring the compatibility to the level 130, and not to leave it at 120, but from the other side – I definitely do not want to explain to my clients, why their reports are running slower on SQL Server 2016 once migration is finished.
Dear Microsoft, I need a Trace Flag to make this thing right. Please! :)
to be continued with Columnstore Indexes – part 86 (“New Trace Flags in SQL Server 2016”)
Do you have any idea why batch mode is not turned on for everything based on cost which clearly is technically possible?
Also, why did Microsoft apparently deliberately remove some well known hacks to turn on batch mode in a rowstore query?
Hi tobi,
I believe that the idea here was to soften some of the impact on the OLTP systems, because those who do copy&paste of the code found in internet, discovered that Columnstore can bring “miracle” to their performance.
I believe it is a right effort, but there need to be a way, for those who are using the previous implementations for 4 years to continue using it. I hope there will be some trace flag or some other way to do that, but I do not hold my breath on that :)
Best regards,
Niko
For SQL Server 2014, I saw a suggestion (at http://dba.stackexchange.com/questions/97650/what-exactly-can-sql-server-2014-execute-in-batch-mode) to get batch mode even on large rowstore tables by doing a “fake” join to a dummy table with columnstore index. I tested this on a SQL 2016 RTM intance and this still appears to work.
Preparation (needs to be done just once; after that never ever change the data or indexes in the dbo.ForceBatch table again):
CREATE TABLE dbo.ForceBatch (Dummy int);
INSERT INTO dbo.ForceBatch VALUES(1);
CREATE CLUSTERED COLUMNSTORE INDEX csix_ForceBatch ON dbo.ForceBatch;
(Note that the INSERT is required for option #2 below; if you plan to use option #1 only, you don’t even need to put this single row in the table)
Modification to query – option #1 (dbo.ForceBatch is not even used in query, but operators that can use Batch mode now do – at least on my test box)
select top 1000 prod.ProductName, sum(sales.SalesAmount)
from dbo.FactOnlineSales sales with(index([PK_FactOnlineSales_SalesKey]))
inner join dbo.DimProduct prod
on sales.ProductKey = prod.ProductKey
inner join dbo.DimCurrency cur
on sales.CurrencyKey = cur.CurrencyKey
inner join dbo.DimPromotion prom
on sales.PromotionKey = prom.PromotionKey
left outer join dbo.ForceBatch
on 1 = 0
where cur.CurrencyName = ‘USD’ and prom.EndDate >= ‘2004-01-01’
group by prod.ProductName
order by sum(sales.SalesAmount) desc
option (recompile);
Modification to query – option #2 (added in case there are situations where the optimizer outsmarts option #1; in this version the optimizer has to include a scan of the ForceBatch table which is an extra overhead of mere microseconds, but hopefully increases the chances of getting batch mode where possible)
select top 1000 prod.ProductName, sum(sales.SalesAmount)
from dbo.FactOnlineSales sales with(index([PK_FactOnlineSales_SalesKey]))
inner join dbo.DimProduct prod
on sales.ProductKey = prod.ProductKey
inner join dbo.DimCurrency cur
on sales.CurrencyKey = cur.CurrencyKey
inner join dbo.DimPromotion prom
on sales.PromotionKey = prom.PromotionKey
cross join dbo.ForceBatch
where cur.CurrencyName = ‘USD’ and prom.EndDate >= ‘2004-01-01’
group by prod.ProductName
order by sum(sales.SalesAmount) desc
option (recompile);
Both versions run in approximately 3-4 seconds on my test VM, versus 15 seconds for the full row mode plan you get when not adding the dbo.ForceBatch table. Most of those 3-4 seconds is spent in the clustered index scan, which still has to run in batch mode. This is impossible to avoid: rowstore indexes can only be scanned or seeked in row mode.
(Without the index hint, the optimizer will use the columnstore index for the query and it finishes in less than a second, so the hint is a bad choice in this case. And yes, I know you just wanted to show the side effect of avoiding the columnstore index and never impleid that this hint would be smart in this case).
Hi Hugo,
I know about the dummy table – as you have written in the last paragraph, I was trying to make a case where it will make difference. I am convinced that a lot of people migrating from 2012/2014 will notice the impact and I wanted for those who are using search engines to find a reference, since there is nothing official published on this matter.
Best regards,
Niko
Let me get this straight: in the SQL Server 2016 ContosoDW, you didn’t get batch mode execution even though there is a columnstore index on the table? That’s because the columnstore index is never used in the plan (while with the dummy table it does appear in the plan)? Am I correct?
Hi Koen,
yes – this is correct.
Best regards,
Niko
Hiko, my goal is read all your practical notes to be better prepare in our migration plan from 2014 into 2014. The primary motivation are the advanced analytics features and lot more things mentioned on your prev posts but this is a disappointing. This is very close to regular queries our data analysts use everyday and its a natural thing to, parellel sort in 2016 being i think one of the most important.
Ill follow through your remaining posts, maybe it was resolved anyway in 2016 SP1. Thanks and more power to you.
Hi Rodel,
In case you missed it, please read all the comments. In comment 2 I show two workaround methods that can be used to “force” batch mode onto a query that would otherwise use row mode.
Also, please be aware that what Niko demonstrates only happens because he *forces* the optimizer to not use the columnstore index. You write that your query analysts use this every day; I really hope that this is a remark about the type of query and not about the hinting used in the demo query. My estimate is that this type of hint in needed in less than 0.01% of all queries, and without that hint the optimizer would have picked an execution plan that uses the columnstore index and batch mode execution.
I really hope you understand that Niko had to use a hint to show this precisely because, without the hint, it would not have happened. There might be examples of queries where the optimizer chooses by itself to use a rowstore index instead of the columnstore, and in those cases you might indeed lose batch mode. But I expect those situations to be very rare. (And if you do run into them, then you have the workarounds avaiilable from my previous comment)
Hi Hugo, probably it was reading too much that I missed some of important details in Niko’s tests. This kind of queries (not the hints) are what I expect our analysts would write everyday. Select queries and aggregates on large timeseries data in a partioned CCIX. If I understand it right, if I issue this query, it would naturally take a batch mode execution without hints?
SELECT TOP (1000) *
FROM HistorizedCCIXTable
ORDER BY
Timestamp DESC;
When I tried this query on a CCIXed table with 32 billion rows in 2014, it never finish lols. I thought optimizer is smart enough to pickcup or could it be because i have too much disallignment on my compressed row groups.
*Btw, I am a developer but I have to deal now with these big data, and lovin it so far :)
Hi Rodel,
The query from this blog post, without the hint, will use the columstore index and batch mode; and it runs very fast. For that type of query I expect no problems.
The query in your last comment is a different beast, and I am not surprised that it runs for a long time. It has several issues:
1) SELECT * means you want to return all columns. That makes nonclustered rowstore indexes relatively expensive (because you need to do a lookup), But it also makes columnstore indexes more expensive (because you lose the benefit of column elimination); and if you have a nonclustered columnstore index that doesn’t include all columns you still also need the lookup.
2) Sorting is expensive, batch mode helps a bit but is not a silver bullet. You still need to have all data available before you can even sort, and with 32 billion rows (and in this case even all columns for those 32 billion rows), that will be a challenge. Even though you requst only 1000 rows, you want “the first” 1000, and those can only be teremined by sorting all data first and then returning 1000 and discarding the rest.
3) Because the query forces a sort of 32 billion rows, I expect the optimizer to request a huge memory grant, which can delay the actual start of the query. (If insufficient memory is available when you submit the query, it will wait for memory to become available). But even that grant will probably not be enough so the sort will spill to tempdb, causing a lot of physical IO and perhaps even autogrow events on tempdb.
You mention disalignment, that is not a factor here. Alignment is important for rowgroup elimination, which can occur if there is a filter in the query. There is no filter here.
The query as written by you will only run fast if you have a rowstore index on the Timestamp column. In that case the optimizer will use an ordered backward scan to read only the last 1000 rows from that index, do a lookup into the clustered index to get the rest of the data, and that’s it. Should return in just a few seconds. But that index would probably not be relevant for any of the actual production queries so I hope you do not have it.
I assume that “Timestamp” is the name of a column with a datetime data type? And not actually a column with data type “timestamp” (which is a misleading data type name – timestamp or its synonym rowversion is a meaningless number that changes whenever the row is inserted or updated).
And I assume that your query is intended to give you a rough idea of what changed recently in your data?
In that case, I have two tips that, combined, will probably make this query run lots faster:
1: Replace SELECT * by SELECT Col1, Col2, … (where you specify only the columns you need to see; the fewer the better); and
2: Add a WHERE clause. You want the 1000 most recent rows, right? So if you know that, for instance, there are 2,000 rows on average each day, then add a filter on “WHERE Timestamp > (2 days ago)”. I use 2 days ago to make very sure that there will be at least the requested 1000 rows; the actual period depends on how many row son average you have each day and how wide the statistical variance is. This filter will allow rowgroup eliminiation (depending on alignment), and it will seriously reduce the amount of data to be sorted. Sorting a few thousand rows, or even a hundred thousand rows, is a very easy task that should complete in mere seconds.
I hope this helps!
Hi Hugo, you’re right in all your comments. Thanks for a comprehensive response!
I understand the benefit of CCIX is fully realized when we select only the columns that we need. The Timestamp is a datetime2 data type, sorry for the confusion.
Sorting is indeed the most expensive part of the execution plan in this query, I just thought query optimizer would be smart enough to figure out where to start based on partition and alignment of row groups (alignment of data) because they are sorted before they are loaded into CCIX. I tried a range query on 1 month data, it finished in couple of seconds, wonderful stuff.
And yes this script is extremely fast when i recreated (Clustered Rowstore index) CRIX which shaken my belief of CCIX. It’s undisputable, columnstore reduced disk space utilization multifold but i still havent seen full performance gains based CCIX to be honest. It seems to me analysts who developed analytical models based on data in CCIX need to have deeper insights of sql server data strucuture in order to perform their functions or we will always have to sitdown and perform query optimization :)
The data are loaded but the queries would come later and so I cannot predict where to actually look. But I hope to keep in touch with you in edge cases. Have nice weekend.
Hi Rodel,
Try to sort the Columnstore Index on the column you are ordering (executing Segment Clustering), this might improve the performance of your queries.
Best regards,
Niko
Hi Hugo,
thank you so much for the valuable editions! :)
Best regards,
Niko
Hiko, my goal is read all your practical notes to be better prepare in our migration plan from 2014 into 2014. The primary motivation are the advanced analytics features and lot more things mentioned on your prev posts but this is a disappointing. This is very close to regular queries our data analysts use everyday and its a natural thing to, parellel sort in 2016 being i think one of the most important.
Ill follow through your remaining posts, maybe it was resolved anyway in 2016 SP1. Thanks and more power to you…
Hi Rodel,
Parallel batch sorting works very well in SQL Server 2016, there is an additional trace flag (Trace Flag 9389) that will allow query to add Dynamic memory grant for batch mode operators (http://www.nikoport.com/2016/07/29/columnstore-indexes-part-86-new-trace-flags-in-sql-server-2016/).
2016 is an exceptional release which should accelerate your Columnstore Queries quite significantly in comparison to 2014, especially because of the sorting and predicate pushdown operations.
Best regards,
Niko
Hi,
We use SQL 2016 SP1 standard edition. In this edition there is a limitation with CCI of only 2 cores / threads.
I played around a bit, and found a worse performance when using this method: parallelism (40 cores) is being replaced by batchmode (2 threads), which takes about two times longer.
Can you confirm that this hack only works on enterprise edition and/or systems with less cores than we do?