Continuation from the previous 82 parts, the whole series can be found at https://www.nikoport.com/columnstore/
A lot of things were changed in SQL Server 2012, which was quite a ground-breaking release if you look at it with a lot of attention – the memory functionality was rewritten, the first appearance of the Columnstore Indexes and a new high-availability technology, called Availability Groups made into the engine. With its appearance in the past 4 years it became clear that this is the direction where Microsoft was taking the SQL Server professionals. The investments for the high availability and disaster recovery, plus of course the readable secondaries plus the depreciation of the Mirroring were delivering the message to the masses – anything other then AlwaysOn/Always On AG/Always On FC should not be considered for the modern projects.
Around one year ago, in 2015 there was an important announcement about the new capability of doing Transactional Replication to Azure SQLDatabase. This has given a different kind of sign to the market – telling the story that the Transactional Replication was still an item, with some potential for further improvements.
This is not to say that the real customers in the real world have abandoned the Transactional Replication somehow, because why would you change a solution that works, unless of course it is not being functional anymore or some new functionalities does not support it.
In SQL Server 2012 & SQL Server 2014 there were no support for the Columnstore Indexes in combination with Columnstore Indexes (well, let’s be honest – there is no sense of replicating read-only table for the most cases) and the Clustered Columnstore were not supported at all.
Fast forward to the end of May 2016, days before the GA of SQL Server 2016. After delivering a 24 Hours of PASS presentation on what’s new for Columnstore Indexes in SQL Server 2016, I have received an email from Miles Marshall on the matter if the replication is finally supported or not.
This blog post is about the results of my research on this topic.
Given that in SQL Server 2016 we have 3 different type of Columnstore Indexes we have to consider them 1 by 1:
– The Nonclustered Columnstore Index became updatable and now the tables carrying them became more interesting
– The Clustered Columnstore Indexes which are the driving force for the DWH & BI solutions
– The Clustered Columnstore Indexes on the InMemory tables
I am not be going through all little details of setting up the transactional replication and configuring the respective accounts and access rights, because there are many competent blogposts and books on this matter. I will simply try to focus on the Columnstore part of the setup.
Once again the free sample DB ContosoRetailDW from Microsoft comes to the rescue, let’s restore a fresh version of it:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Now, let’s drop the current primary key on the FactOnlineSales and create a Clustered Columnstore Index on it:
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]; create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales;
For the updatable Nonclustered Columnstore Index, let’s create new table FactOnlineSales_NCCI, with a primary key, that will be required for the transaction replication:
drop table if exists [dbo].[FactOnlineSales_NCCI]; CREATE TABLE [dbo].[FactOnlineSales_NCCI]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, Constraint PK_FactOnlineSales_NCCI Primary key (OnlineSalesKey), INDEX NCCI_FactOnlineSales Nonclustered Columnstore (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) ) ON [PRIMARY] GO set identity_insert dbo.factonlinesales_ncci on insert into [dbo].[FactOnlineSales_NCCI] (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) select top 2 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate from dbo.FactOnlineSales_Hekaton where OnlineSalesKey not in (select OnlineSalesKey from [dbo].[FactOnlineSales_NCCI]) set identity_insert dbo.factonlinesales_ncci off
For the InMemory Clustered Columnstore we shall have to add a Memory Optimised Filegroup, creating then a new InMemory table FactOnlineSales_Hekaton with the Clustered Columnstore Index on it:
USE master; ALTER DATABASE [ContosoRetailDW] ADD FILEGROUP [ContosoRetailDW_Hekaton] CONTAINS MEMORY_OPTIMIZED_DATA GO ALTER DATABASE [ContosoRetailDW] ADD FILE(NAME = ContosoRetailDW_HekatonDir, FILENAME = 'C:\Data\xtp') TO FILEGROUP [ContosoRetailDW_Hekaton]; GO use ContosoRetailDW; drop table if exists [dbo].[FactOnlineSales_Hekaton]; CREATE TABLE [dbo].[FactOnlineSales_Hekaton]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, CONSTRAINT [pk_t_colstor_hk] PRIMARY KEY NONCLUSTERED HASH (OnlineSalesKey) WITH (BUCKET_COUNT = 10000000), INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Now with 3 tables corresponding each of the tested scenario, let’s go forward and set up a transactional replication for each of them step by step:
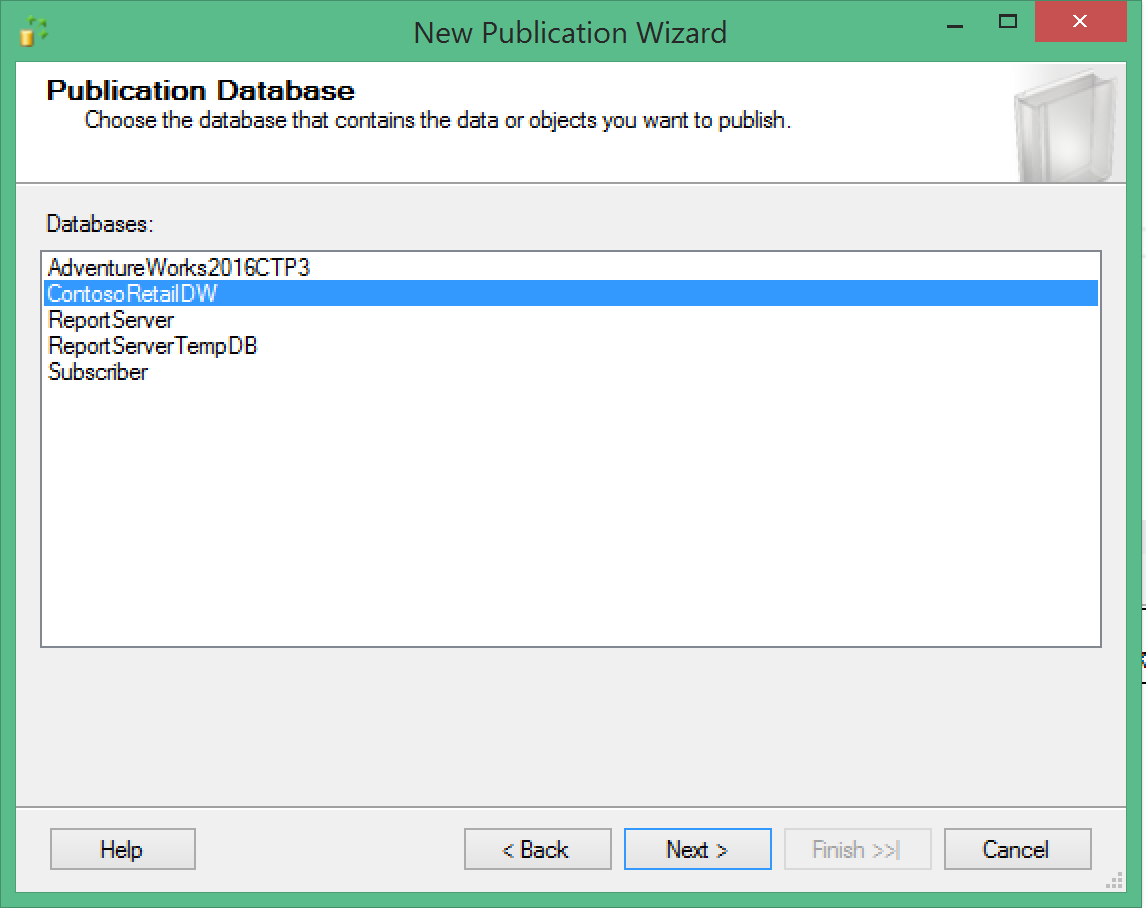
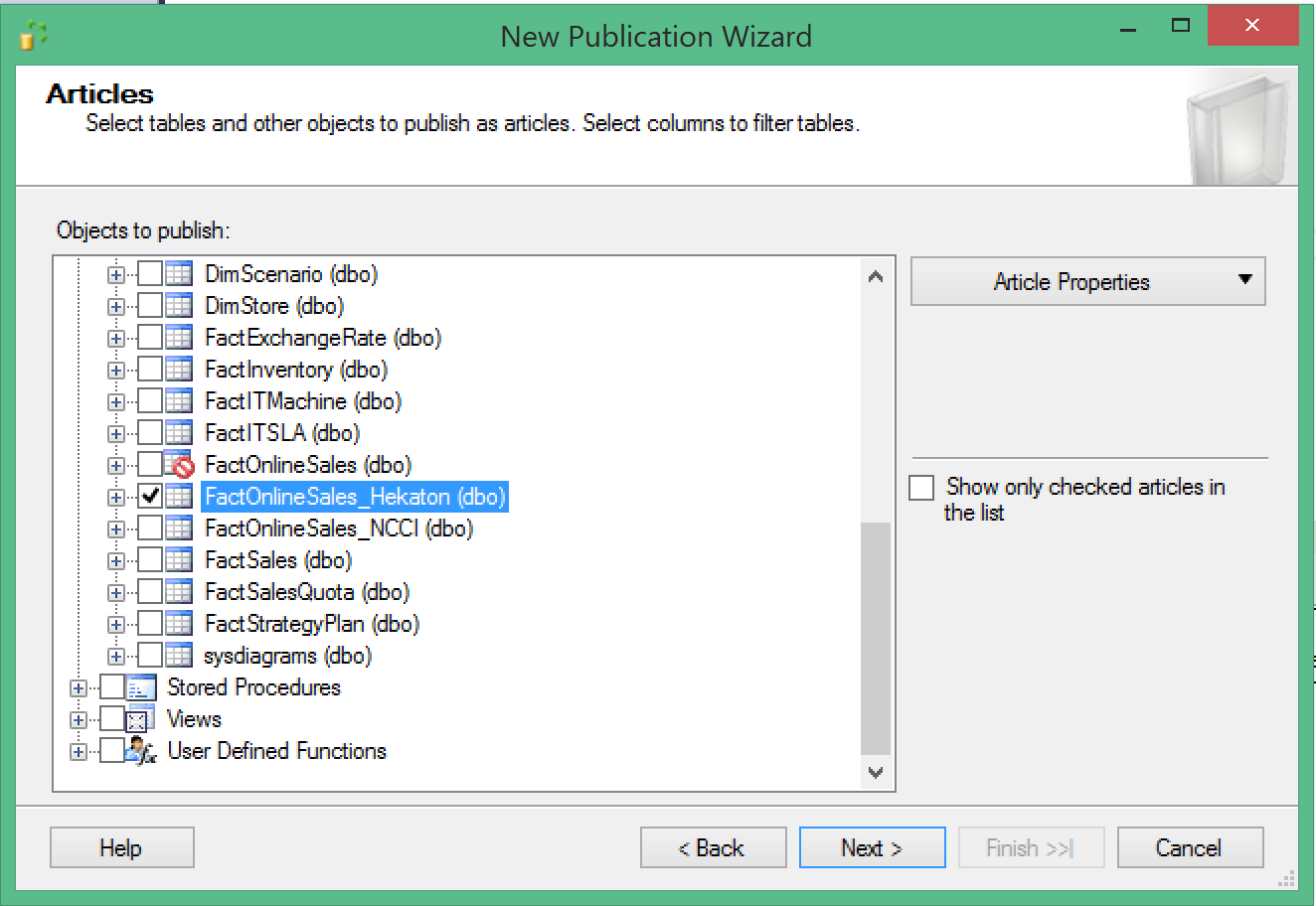
At this point you can notice, that from our 3 tables there are only 2 are available for the transactional replication, with the disk-based table with a Clustered Columnstore Index is not being available for the replication.
This means that there are no improvements since SQL Server 2014 for the DWH/BI scenarios in this direction and this is definitely sad.
Well, we can always go a different direction, like in the case of Availability Groups in SQL Server 2014, where readable secondaries are supported only for the Nonclustered Columnstore Indexes. In SQL Server 2016 we can use Nonclustered Columnstore Index even on all columns if needed and get the principle improvements for the Batch Execution Mode.
Notice here that even though we can select the InMemory tables with Clustered Columnstore, there are a couple of additional important settings that needs to be configured to make things function. So clicking through the GUI Wizard will not set things correctly up by default.
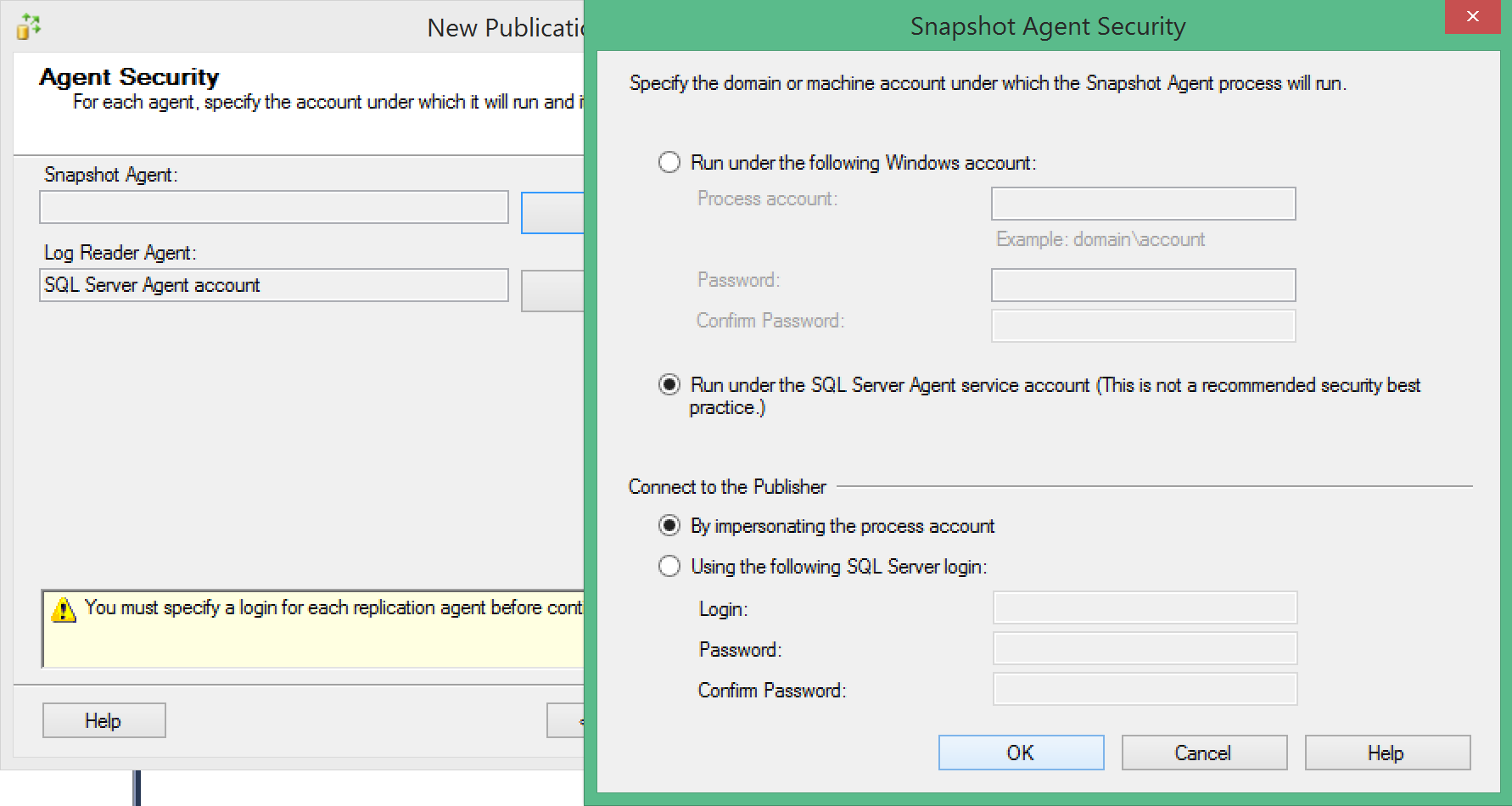
This way is easy to set up the publisher, and for the beginning I selected only the disk-based Nonclustered Columnstore table.
I will spare the details of clicking through the subscriber setup – it is a basic thing for this scenario. I have simply created a new database that I have called Subscriber, and starting pulling out the subscription information from the publisher into it.
To test the final result, I have executed the following query to see if the table has been created in the destination DB and if the data has been successfully transferred:
SELECT TOP 1000 [OnlineSalesKey]
,[DateKey]
,[StoreKey]
,[ProductKey]
,[PromotionKey]
,[CurrencyKey]
,[CustomerKey]
,[SalesOrderNumber]
,[SalesOrderLineNumber]
,[SalesQuantity]
,[SalesAmount]
,[ReturnQuantity]
,[ReturnAmount]
,[DiscountQuantity]
,[DiscountAmount]
,[TotalCost]
,[UnitCost]
,[UnitPrice]
,[ETLLoadID]
,[LoadDate]
,[UpdateDate]
FROM [Subscriber].[dbo].[FactOnlineSales_NCCI]
After inserting 2 rows into the original table with the help of the setup script, the Subscriber Database returned me the original rows as well:
![]()
To make sure that everything was working perfectly, I decided to consult the meta-structure of the replicated destination table, I simply opened the replicated table in the SSMS Object Explorer, and this is what I saw:
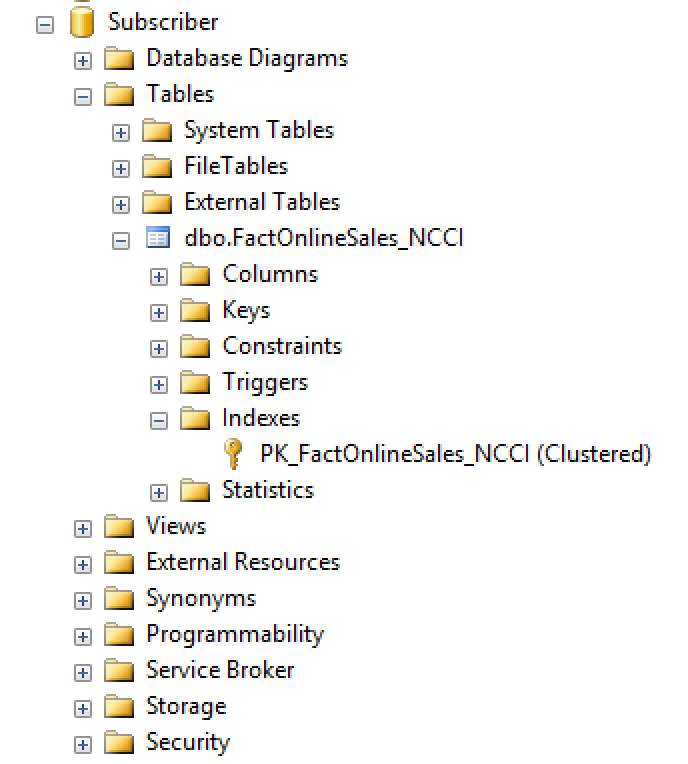
Yes, we can replicate a table with a Nonclustered Columnstore Index, but the destination table will not keep it.
Well, of course there is a new option for that – there are actually a couple of them. Lets set the replicated table properties and scroll down a little bit:
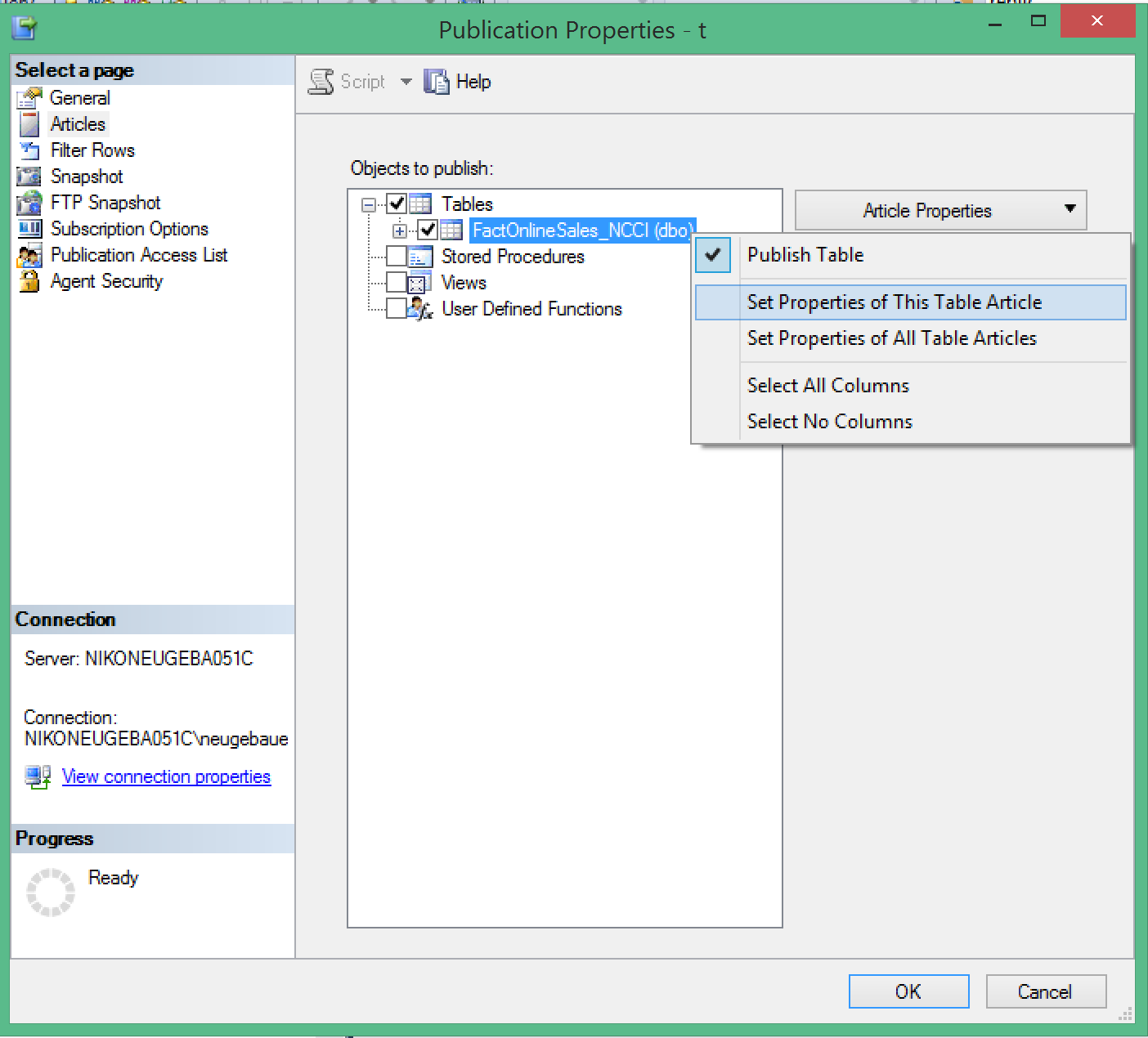
You will find the 2 new options, plus the necessary options for the in memory tables support in the properties for the selected table.
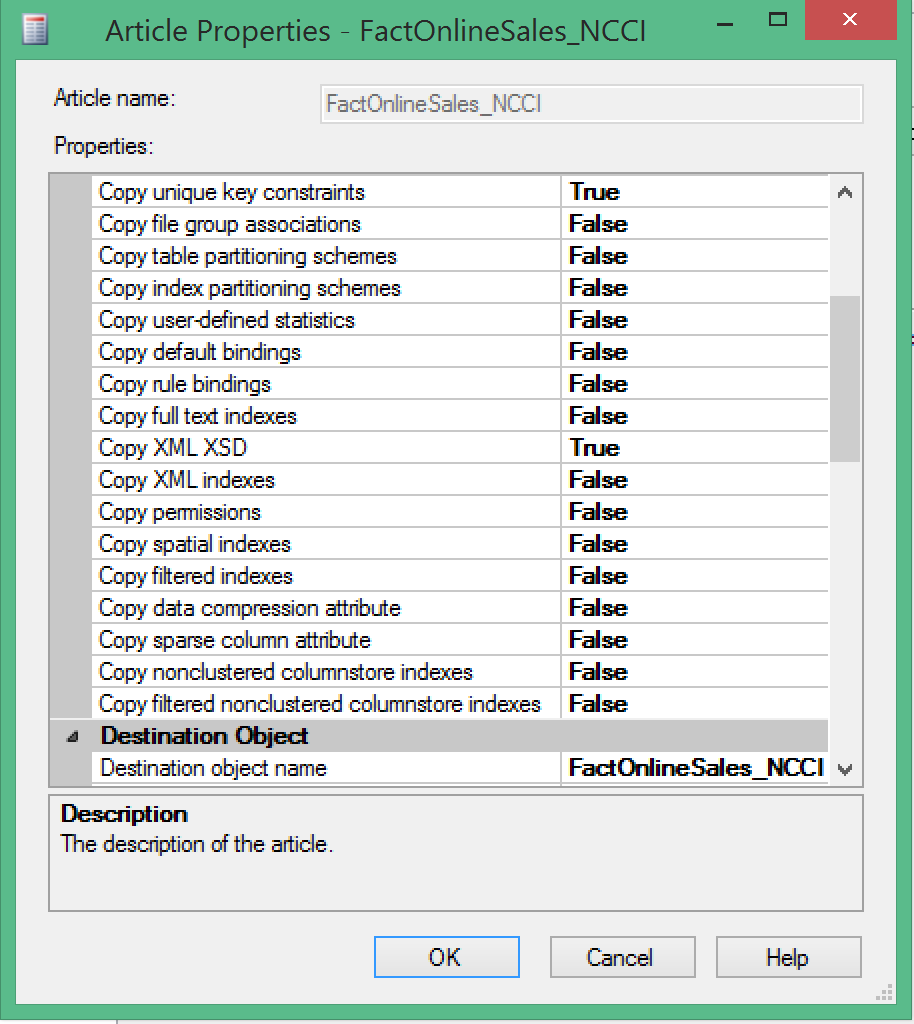
Well, I have to say that no matter how often I have tried to change those settings it has never functioned correctly. The only way to make it really work on RC 3.3 of SQL Server 2016 was to create a new publisher right from the beginning – and I am sending this info to the development team.
UPDATED: This bug was fixed in CU 2 for SQL Server 2016 RTM.
To solve it for now of course, you can simply create a nonclustered columnstore index on the destination table :)
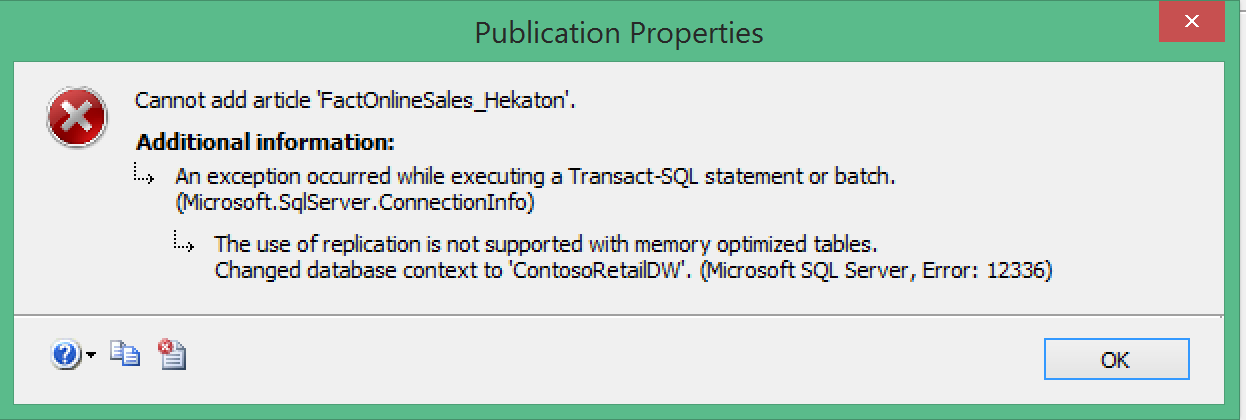
Regarding the Replication of InMemory tables – it looks like this functionality is not supported at all :( You can see on the left side the error message that one receives while trying to add an InMemory table to an existing publication. I have also consulted the documentation on the MSDN, which also states that publishing an InMemory Table is not implemented (https://msdn.microsoft.com/en-us/library/dn600379.aspx) while we can create an InMemory tables on the subscriber side.
Overall this means that only disk-based Nonclustered Columnstore Indexes can be published through the replication in SQL Server 2016 and I can imagine this option becoming quite popular even for the DWH-style solutions.
I am not sure that the effort of implementing support for InMemory tables replication is worth it and depending on the technical effort associated with Clustered Columnstore Indexes implementation the same applies to them as well, since I would rather see more investment in other areas of SQL Server.
to be continued with Columnstore Indexes – part 84 (“Practical Dictionary Cases”)
Please let’s know if this case still the same on newer sql versions.
Hi Maneesh,
indeed.
Best regards,
Niko