Continuation from the previous 68 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blogpost is dedicated to one of the key improvements in Columnstore Indexes in SQL Server 2016 – the Operational Analytics.
This blog post is focused on the Row Store, on-disk based solution, and the next blog post will be focusing on the InMemory architecture, that is implemented to help InMemory OLTP applications. Given that the architecture has some significant differences, I decided to focus on each of the solutions separately.
First of all let us review what is being called ‘Operational Analytics’:
This term is being applied to the Operational Database (OLTP – Online Transaction Processing), where without any additional modifications of the normalised schema, we are trying to extract the analytical information.
Given that an analytical query will need to block a number of tables, while processing them – thus impossibilitating the normal functioning of the operational transactions, the traditional solution was to use an ETL process to store the informational in a separate Database. That separate database is typically optimised for reading in the way that the schema of the database is being converted to a denormalised DataWarehouse style of design.
That does not make out of that analytical database a DataWarehouse, its just a copy of the Operational Transaction Database, that is optimised for the analytical processing.
By using a separate database we would avoid fighting for the same resources and thus avoiding locks that would block our operational queries from completing.
Note: Another way of solving the locking problem would be using the Database Snapshot, T-Log Shipping, Mirroring with a Snapshot or Availability Groups secondary, while the problem of complex unoptimised schema is something that is not getting solved without any additional work.
There are 3 key problems with the ETL method that I do identify:
– Costs: Add an extra Server or an extra Database to the equation, plus the costs of the BI Developer (you do not think that your .NET Developer will do that correctly, don’t you?), plus the time that DBA will spend on taking care of this instance, plus the storage space, etc …
– Delay: Given that we are extracting data not in the real time, those transfers are executed with some certain frequency – Hourly, Daily or Weekly. This gives a final user the information which is never actual – by the time he/she is requesting the information, it is already having at least the delay that has passed since the last successful ETL process.
– Successful ETL: unless you are doing a presentation that has been already executed over 100 times, in the real world things do get broken. For example, if a OLTP developer shall change the data type or precision of one of the columns from the table that participates in ETL process, then voilá! ETL process will need to get fixed. And of course in the theoretical world – every developer is talking to BI Developer and they work together in 3 different & distinct environments, with TA team doing their job very well, etc, etc … Blah blah blah … In the real world, someone has just applied an emergency fix for some urgent problem, that some directory has ordered to do NOW. And this is why your ETL process is broken and why the dashboards still show old information.
Oh and please, add Sysadmin mistakes (they are also human, you know ;)), or simply Network problems – “we need to call the Network guy but in the mean time, stay tuned – the dashboards won’t get any update”.
An attempt to find a kind of a solution
Ok, ok – I am sure everyone is on the same line right now … But what if we would add some indexes to our existing OLTP tables ? Maybe they will do an OK-ish job after all ?
First of all, all of your writes into those operational tables will get affected with the additional indexes. They will not be very easy on your system, especially if you are inserting many thousands of rows per hour.
And do you really want to compete with the Batch Execution Mode ? Its almost the same as riding a bike against a Formula 1 on the straight road.
Operational Analytics in Azure SQLDatabase & SQL Server 2016
In 2015, Microsoft has taken some very serious steps in order to help everyone struggling with this problem – the upcoming SQL Server 2016 contains a solution for allowing to run the analytical queries in real-time on the operational database.
As a matter of a fact, as of this very moment, if you are using one of the Premium SQL Databases on Azure, you will be able to add this functionality to your workloads at any moment.
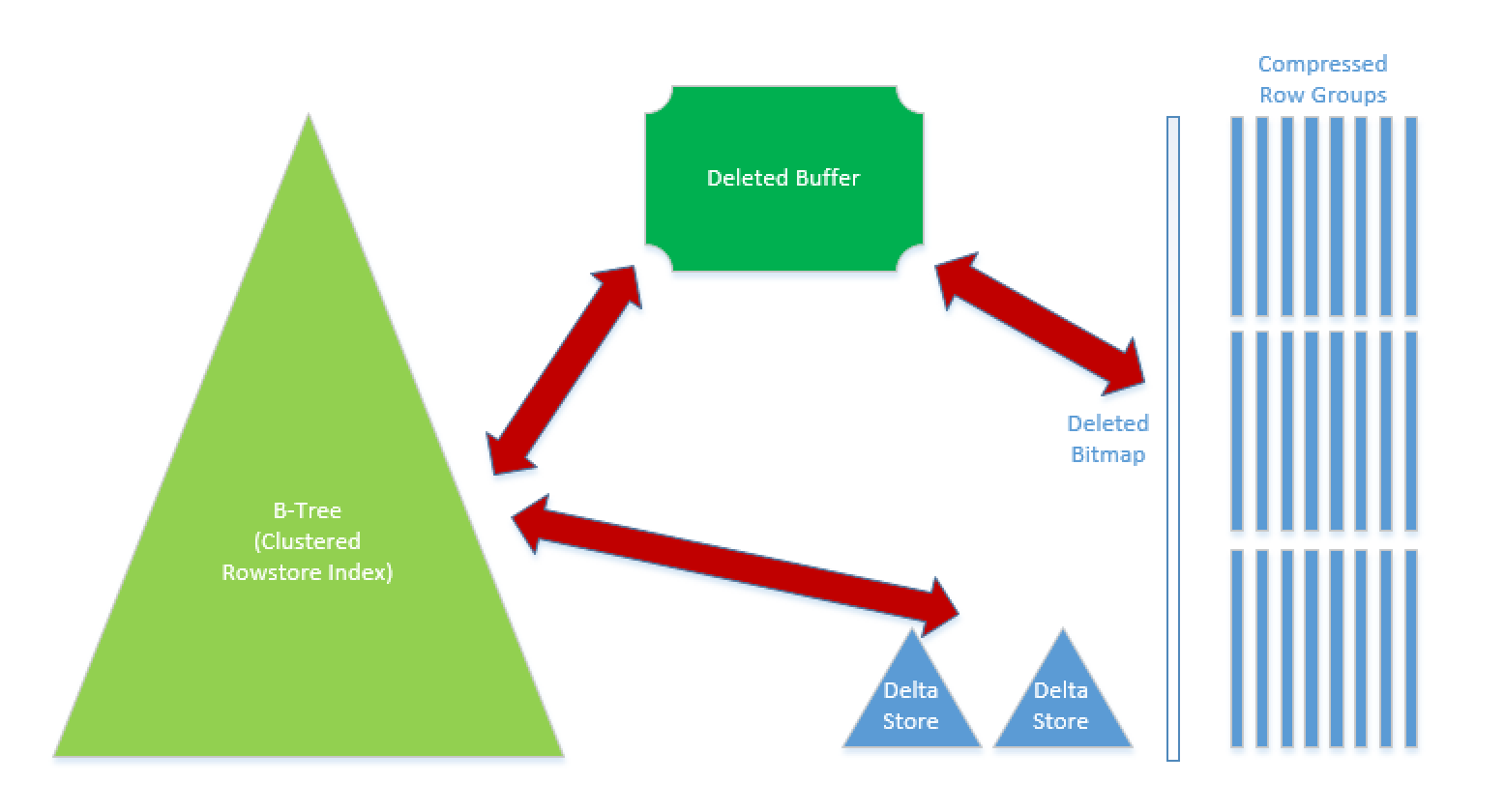 In SQL Server 2012 and in SQL Server 2014 the Nonclustered Columnstore Indexes were non-updatable (we could only switch in partitions as an alternative), but now in SQL Server 2016 and in Azure SQLDatabase, our Nonclustered Columnstore Indexes are updatable. I have already blogged about the architecture of the changes in Columnstore Indexes – part 55 (“New Architecture Elements in SQL Server 2016”), but to recap the difference to the Clustered Columnstore: the new element Deleted Buffer contains all the row that were deleted from the primary (Rowstore) structure, but were not synchronised with Deleted Bitmap yet. This is done in order to lower the performance impact on the operational queries (Insert,Update,Delete) – scanning a Deleted Bitmap on a very large table might take the very precious time.
In SQL Server 2012 and in SQL Server 2014 the Nonclustered Columnstore Indexes were non-updatable (we could only switch in partitions as an alternative), but now in SQL Server 2016 and in Azure SQLDatabase, our Nonclustered Columnstore Indexes are updatable. I have already blogged about the architecture of the changes in Columnstore Indexes – part 55 (“New Architecture Elements in SQL Server 2016”), but to recap the difference to the Clustered Columnstore: the new element Deleted Buffer contains all the row that were deleted from the primary (Rowstore) structure, but were not synchronised with Deleted Bitmap yet. This is done in order to lower the performance impact on the operational queries (Insert,Update,Delete) – scanning a Deleted Bitmap on a very large table might take the very precious time.
This Deleted Buffer will be used to store the Row’s Locators of the rows that were removed from the Primary structure and that are related to the compressed Row Groups. Should we modify a row that is contained inside the Delta-Stores, then this operation will be executed immediately on them. This happens because Delta-Store is simply another B-Tree structure, like any other secondary Index it’s update does not bring something extraordinary to the architecture.
There is a background process which will synchronise the Deleted Buffer to Deleted Bitmap, making sure that it is scanning the whole Deleted Bitmap just once, and thus making the impact on the Columnstore Structure more singular and more controllable.
Another important aspect is that Nonclustered Columnstore Indexes include the columns that need to be participating in Analytical Queries, and thus their functionality will be generally faster when compared to the Clustered Columnstore indexes build on the same structure.
Taking Azure SQLDatabase for a drive
This time for the test, I will be using a different database on a different Server:
I will use a free AdvenuterWorks database that I have expanded with a great script from Adam Machanic – Make Big Adventure.
After configuring and running the script, I have generated a dbo.bigTransactionHistory with a little bit over 250 Million rows, with the Nonclustered Columnstore Index occupying a bit over 11 GB.
Note that this is rather narrow table with just 5 columns, and so its really very light and small, containing int, datetime and money data types, thus all typical memory & dictionary problems should be far far away.
exec sp_spaceused 'dbo.bigTransactionHistory'

I will run all my workloads against Azure SQLDatabase P6 instance, which at the moment has a version 13.0.700. Comparing to the most recent version of the SQL Server 2014 CTP 2.4, one can notice that the current version of the SQL Server is 13.0.600, so at this point we can only speculate if the next CTP version is already available on Azure. :)
Let’s create a simple Nonclustered Columnstore Index on the bigTransactionHistory table:
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_bigTransactionHistory on dbo.bigTransactionHistory ( [ProductID], [TransactionDate], [Quantity], [ActualCost] );
Let’s use our common query against the new DMV sys.internal_partitions to see currently available internal structure:
select object_name(part.object_id) as TableName,
ind.name as IndexName,
part.internal_object_type, part.internal_object_type_desc,
part.row_group_id, part.rows, part.data_compression, part.data_compression_desc
--,*
from sys.internal_partitions part
left outer join sys.indexes ind
on part.object_id = ind.object_id and part.index_id = ind.index_id
where part.object_id = object_id('dbo.bigTransactionHistory');
 You can observer 3 internal structures here at the picture: 1 Deleted Bitmap and 2 Deleted Buffers. Interesting is to notice that there is no compression applied to the Deleted Buffers – it make sense to keep them functioning as fast as possible, while the amount of the information contained inside should be nothing to worry or compare with the rest of the table.
You can observer 3 internal structures here at the picture: 1 Deleted Bitmap and 2 Deleted Buffers. Interesting is to notice that there is no compression applied to the Deleted Buffers – it make sense to keep them functioning as fast as possible, while the amount of the information contained inside should be nothing to worry or compare with the rest of the table.
Notice that besides our good old friend Deleted Bitmap we have 2 Deleted Buffers. At the moment, I have no concrete explanation why we have 2 instead of just 1, but I hope to find it out soon and to update this blog post.
Before diving into the analytical queries, let’s make sure that we have the best B-Tree index possible for out bigTransactionHistory table:
CREATE NONCLUSTERED INDEX [IX_ProductId_TransactionDate] ON [dbo].[bigTransactionHistory] ( [ProductID] ASC, [TransactionDate] ASC ) INCLUDE ( [Quantity], [ActualCost]) WITH (DATA_COMPRESSION = PAGE);
Now I will run the following 2 queries (1 against B-Tree index with the help of IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX hint, and the second against Columnstore Index) and compare their performance:
set statistics io, time on
SELECT Year([TransactionDate])
,Sum([Quantity]) as TotalQuantity
,Sum([ActualCost]) as TotalCost
FROM [dbo].[bigTransactionHistory] tr
inner join dbo.bigProduct prod
on tr.ProductID = prod.ProductID
where TransactionDate < '2009-01-01'
group by Year(TransactionDate)
having Sum([Quantity]) > 10000
order by Year(TransactionDate)
option (ignore_nonclustered_columnstore_index);
SELECT Year([TransactionDate])
,Sum([Quantity]) as TotalQuantity
,Sum([ActualCost]) as TotalCost
FROM [dbo].[bigTransactionHistory] tr
inner join dbo.bigProduct prod
on tr.ProductID = prod.ProductID
where TransactionDate < '2009-01-01'
group by Year(TransactionDate)
having Sum([Quantity]) > 10000
order by Year(TransactionDate);
This is the actual execution plan for using the traditional RowStore B-Tree Index:

Compare it to the actual execution plan produced by using Nonclustered Columnstore Index on the same table:

Not a huge difference, but you will notice that the most important part with Hash Match iterator has been moved closer to the Index Scan, thus enabling even faster processing. But let’s take a look at the execution times:
1. Rowstore B-Tree Index: CPU time = 68860 ms, elapsed time = 23573 ms
2. Nonclustered Columnstore: CPU time = 13061 ms, elapsed time = 3649 ms
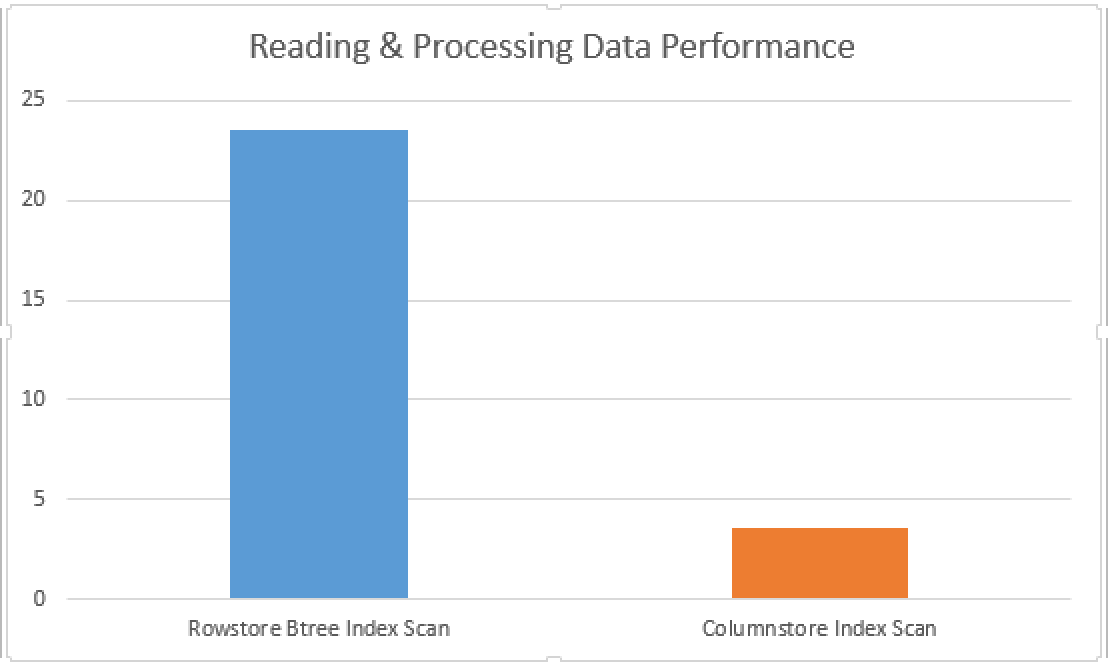 Even without any Segment Elimination, Columnstore Indexes Scan was more than 6 times faster! And notice on the execution plan, that we did not used any incredibly advantageous operators like Sort or Window Function, they would definitely make the difference even bigger. This is pretty amazing, given that for a lot of queries we should be able to tune the performance of Columnstore Index even further.
Even without any Segment Elimination, Columnstore Indexes Scan was more than 6 times faster! And notice on the execution plan, that we did not used any incredibly advantageous operators like Sort or Window Function, they would definitely make the difference even bigger. This is pretty amazing, given that for a lot of queries we should be able to tune the performance of Columnstore Index even further.
Without any doubt, on large amounts of data, Columnstore Indexes bring colossal improvements, that anyone needing to get dashboards with live information will appreciate.
Operational
Aren’t we forgetting something ? The improvement for Operational Analytics meant that we can finally modify Nonclustered Columnstore Indexes.
Let’s delete a couple of rows from the dbo.bigTransactionHistory table – remember we have a Nonclustered Columnstore index there:
delete top (5) from dbo.bigTransactionHistory;
(5 row(s) affected)
Wow! It has worked! Finally! Have been waiting for this moment for almost 4 years!!!
Hmm, what about our internal structures ? Did we update the Deleted Buffer?
select object_name(part.object_id) as TableName,
ind.name as IndexName,
part.internal_object_type, part.internal_object_type_desc,
part.row_group_id, part.rows, part.data_compression, part.data_compression_desc
from sys.internal_partitions part
left outer join sys.indexes ind
on part.object_id = ind.object_id and part.index_id = ind.index_id
where part.object_id = object_id('dbo.bigTransactionHistory');

Here we are, with one of the deleted Buffers encapsulating information about our 5 deleted rows.
Now if we go and add a couple of rows, to check if our #Columnstore Index has capability of receiving some new random data (I have manually set [TransactionId] column to be equal MAX value + 1):
insert into dbo.bigTransactionHistory
([TransactionId], [ProductID],[TransactionDate]
,[Quantity],[ActualCost])
values (250254581 + 1, 101001, GetDate(), 15, 34.76 );
(1 row(s) affected)
Perfect! What about the internal structure at the moment ?

Look, we have a new Delta-Store with exactly 1 row! That’s cool, but what if we go and delete this value – will it be removed from the Delta-Store as advertised or will we have to add it to the Deleted Buffer ?
delete from dbo.bigTransactionHistory
where TranactionId = 250254581 + 1;

Well done! The data has been successfully removed from the Delta-Store leaving Deleted Buffer and Deleted Bitmap untouched.
Ok, ok – but what about synchronisation between the Deleted Buffer and Deleted Bitmap, how can we do this ?
Let’s try to invoke our good old friend Tuple Mover with the help of Alter Index … Reorganize, to see if it helps:
alter index NCCI_bigTransactionHistory on dbo.bigTransactionHistory Reorganize;
It took a surprising 1 Minute and 5 Seconds to execute this on my 250 Million Rows table, but from what I have heard this operation is being run online – and boy it takes time to process all those Row Groups analysing if there is an opportunity to Merge some of those groups.
What changes has our activity brought to our Columnstore structures?

Brilliant – we have synchronised Deleted Buffer with the Deleted Bitmap, but why do we still have this 5 rows in the Deleted Bitmap? Is it still a small bug needs to be fixed?
Deleting extra 10 rows from the Columnstore Index, to see what changes:
delete top (10) from dbo.bigTransactionHistory;
 Here you go, we have got 10 rows in the Deleted Buffer, which makes me believe that maybe (speculation) after ALTER INDEX … REORGANIZE the moment we add new deleted rows to Deleted Buffer, the 2nd Deleted Buffer is taking over the first Deleted Buffer, while the first one resets. I will need to investigate this…
Here you go, we have got 10 rows in the Deleted Buffer, which makes me believe that maybe (speculation) after ALTER INDEX … REORGANIZE the moment we add new deleted rows to Deleted Buffer, the 2nd Deleted Buffer is taking over the first Deleted Buffer, while the first one resets. I will need to investigate this…
Reading data from Nonclustered Columnstore Index
With the addition of Deleted Buffer the Columnstore Index Scan process is changing internally. We need to take care of those rows that were marked deleted in Deleted Buffer but weren’t synchronised with the Deleted Bitmap yet.
Well, here is a picture is 1000 words worth:

I wish I could say that this architecture is mine, but I just made my own interpretation (copy, paste & adjust) of amazing work done by the incredible team of Per-Ã…ke Larson, Adrian Birka, Eric N. Hanson, Weiyun Huang, Michal Nowakiewicz & Vassilis Papadimos. I bow to their wisdom and knowledge.
In basic words to describe what is going on there: we read data from the compressed Row Groups, ensuring that the Row Locators do not exist in the Deleted Bitmap and that the Row Keys are not part of the Deleted Buffer (this is what makes the true difference with the Clustered Columnstore) and then join data with what is stored inside the Delta-Stores.
One do not have to be a genius to recognise that this architecture will definitely be slower then the original one with Clustered Columnstore Indexes – and let me make extremely clear:
Nonclustered Columnstore (Operational Analytics) is not a true replacement for a good star-schema optimised model.
If you need better performance, then what you can get out of the Nonclustered Columnstore Indexes, then you will need to get back to ETL processes.
Cool, oh but wait, there is one last thing:
Filtered Columnstore
Besides being updatable, the Nonclustered Columnstore Indexes on B-tree RowStore tables became a possibility to become filtered as well.
This will allow to lower even further the impact of the operational queries by dividing the whole structure of the table into 2 areas:
– Hot Data (The part of the data that is being frequently modified by Inserts/Updates/Deletes, we should try to avoid putting Columnstore Index on this part, as long as it is not too big)
– Cold Data (This part of the data is almost archived, it is not getting frequently updated and it is definitely the biggest part of the table structure. We should definitely include this part into our Nonclustered Columnstore Structures)
This means that we can define ourselves what kind of data should be stored inside our Nonclustered Columnstore Index, thus avoiding the pressure on so-called “Hot Data”. Of course we shall need to find some good criteria to do that, but let’s consider our test table and let’s say that I want to put only data that transaction relates to years before 2010 in my clustered Columnstore Index:
create nonclustered columnstore index [NCCI_bigTransactionHistory]
on [dbo].[bigTransactionHistory] (
[TransactionDate]
,[ProductID]
,[Quantity]
,[ActualCost] )
where TransactionDate < '2011-01-01'
with (drop_existing = on);
Checking on the internal structures:
select object_name(part.object_id) as TableName,
ind.name as IndexName,
part.internal_object_type, part.internal_object_type_desc,
part.row_group_id, part.rows, part.data_compression, part.data_compression_desc
from sys.internal_partitions part
left outer join sys.indexes ind
on part.object_id = ind.object_id and part.index_id = ind.index_id
where part.object_id = object_id('dbo.bigTransactionHistory');

Everything looks fine here.
Let's add a couple of rows for the year 2011:
insert into dbo.bigTransactionHistory
([TransactionId], [ProductID],[TransactionDate]
,[Quantity],[ActualCost])
values
(250254581 + 2, 101001, '2011-03-17', 49, 123.55 ),
(250254581 + 3, 101001, '2011-01-02', 94, 199.16 ),
(250254581 + 4, 101001, '2011-12-21', 71, 240.08 );
Successfully inserted, but looking at the internal structures you will find no data in Delta-Stores:
Now let's add 3 rows that correspond to the predicate of our Columnstore Filter:
insert into dbo.bigTransactionHistory
([TransactionId], [ProductID],[TransactionDate]
,[Quantity],[ActualCost])
values
(250254581 + 5, 101001, '2008-03-17', 49, 123.55 ),
(250254581 + 6, 101001, '2009-01-02', 94, 199.16 ),
(250254581 + 7, 101001, '2010-12-21', 71, 240.08 );

You can clearly notice the 4th internal partition, corresponding to the Delta-Store with our 3 rows in it. I expect the filtering functionality to be equal in performance to a regular RowStore B-Tree filtered index.
Running our test query against the Filtered Columnstore Index did not really improve its performance compared to the regular index, but in the terms of the IO - I have naturally seen a very important improvement: there were just 140 Row Groups to process, instead of 243 that I have had in my Columnstore Index originally.
Anyway the point here is that with the filtered Columnstore Index we are decreasing performance impact on the OLTP operations, while still enjoying the massive performance of the Columnstore Index.
The following part is marked as deleted, because this part will need a better research - thanks to awesome explanations from Vassilis in the comments:
One more issue that needs to be cleared though is the situations when we are running a query that will need to join the data from the Rowstore Index with a Nonclustered Columnstore one.
Let's run the original query, but this time without the predicate, based on the date column:
set statistics io, time on
SELECT Year([TransactionDate])
,Sum([Quantity]) as TotalQuantity
,Sum([ActualCost]) as TotalCost
FROM [dbo].[bigTransactionHistory] tr
inner join dbo.bigProduct prod
on tr.ProductID = prod.ProductID
group by Year(TransactionDate)
having Sum([Quantity]) > 10000
order by Year(TransactionDate)
What I expected at this point is that a UNION of the B-Tree Rowstore Index & Columnstore Index would appear, but unfortunately even with the current version on Azure SQLDatabase 13.0.700, this does not take place:

All I get in the execution plan is the usage of ether B-Tree Rowstore Index scan or Nonclustered Columnstore Index Scan (when the predicate allows), but they never work together like it would be logical. This way there would be a more stable and predictable performance without the cliffs between 4 and 24 seconds. I wonder if we shall see this improvement in CTP 3...
Some last thoughts:
One thing I wish to have here is some kind of automatically moving filtered predicate, such as TransactionDate = [LastWeekOnly], for making data from the last week to get into the filtered Columnstore Index automatically... Oh well, there is always a hope ;)
to be continued with Columnstore Indexes – part 70 ("Filtered Indexes in Action")
I would like to see the union plan rewrite for all filtered indexes, no matter what storage format they are using. Seems generally useful.
Hi tobi,
Agreed. Filtered Indexes are definitely the lesser family members of SQL Server, and I really hope that Microsoft will use this opportunity to make them function correctly at least for Columnstore Indexes.
Best regards,
Niko Neugebauer
Greetings Niko —
Regarding your last point, you *can* get the union plan you describe for filtered columnstores. That plan, however, is considered only if SQL has an efficient way to find the rows that are filtered out of the columnstore (otherwise, it would need to scan all the table’s rows from some other index and then filter out the ones that match the columnstore filter). There are various ways you can arrange that:
1. Create a clustered or nonclustered index with the filtering column as the leading column
2. Create a second filtered index with the complementary filter, TransactionDate >= ‘2011-01-01’
3. Have the clustered index partitioned on the filtering column (this sounds like the best choice here)
You can also force the union plan by hinting the filtered columnstore.
(Disclosure: I work for Microsoft).
Greetings Vassilis,
as always, thank you so much for the extremely valuable explanations! :)
I am updating the blogpost and will be posting a new blog post with the tests & thoughts on this matter!
Best regards,
Niko Neugebauer
Niko,
The first execution plan shown features a nonclustered index SEEK, not scan (on the bigTransactionHistory table). Are you saying that columnstore index scan is faster than nonclustered index seek?
Hi PL80,
the first execution plan shows NESTED LOOP with an Index Seek, which makes the Seek being executed for the number of rows that are coming into the nested loop.
Otherwise please do not forget that an Index Seek can be actually a Ranged Scan, or it can be multiple seeks (check the properties to find it out or look at the statistics IO).
Best regards,
Niko Neugebauer
Ok, thanks Niko.
Hi Niko.
Is there any idea why we have two delete buffers?
Hi b_mike,
to my knowledge this was a implementation decision for the online operation of the buffer switching.
Best regards,
Niko