Continuation from the previous 62 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Data Loading is one of the most important topics for any IT professional, no matter if you are a Data Platform specialist working with huge ETL processes, or if you are a .NET developer, creating the next big application for the world.
Everyone cares about how fast their data lands in the destination table.
Doing my tests on SQL Server 2014, I have written a couple of blog posts: Clustered Columnstore Indexes – part 23 (“Data Loading”), Clustered Columnstore Indexes – part 24 (“Data Loading continued”),
Clustered Columnstore Indexes – part 27 (“Data Load with Delta-Stores”).
What is the reason for me to come back to this topic again ? It is simple as the fact, that Microsoft has changed something really important in the way that we can load data into SQL Server 2016. :)
INSERT SELECT WITH (TABLOCK)
In SQL Server 2016, Microsoft has implemented a parallel insert for the Insert … Select .. With (TABLOCK) command. This improvement applies to any table, not only tables with Clustered Columnstore Indexes, but even HEAPs as well.
This is definitely a magnificent improvement, that will result in great improvements for data loading, but what does it mean precisely for Columnstore Indexes ?
For starting, let us consider how the Insert SELECT with or without any options works in SQL Server 2014:
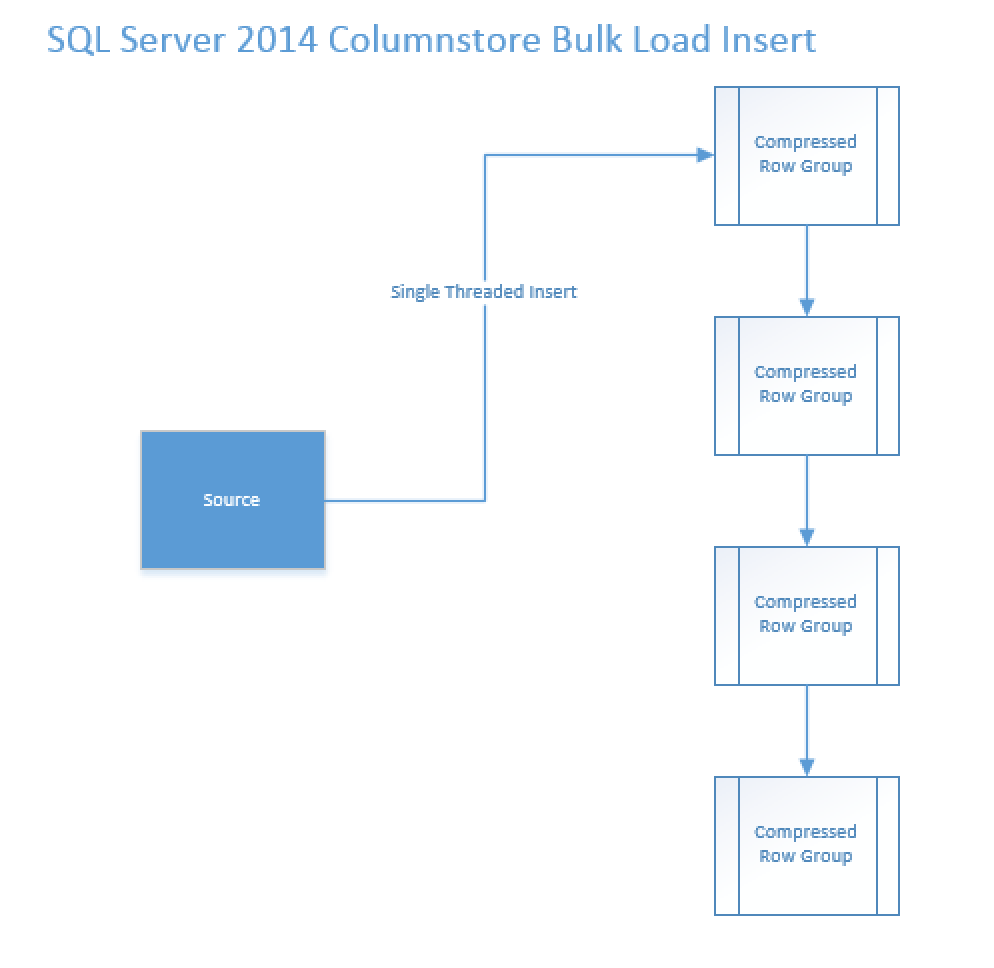 No matter how many cores we have, in SQL Server 2014, the data insertion into Clustered Columnstore uses 1 single core and starts filling Delta-Stores sequentially, by inserting the data into the 1st available Delta-Store until reaching the maximum possible number of rows (either 1048576 or the eventual trim with the memory or dictionary or having less rows). Once the first Delta-Store would get filled, then the next Delta-Store would be filled and so on and so forth.
No matter how many cores we have, in SQL Server 2014, the data insertion into Clustered Columnstore uses 1 single core and starts filling Delta-Stores sequentially, by inserting the data into the 1st available Delta-Store until reaching the maximum possible number of rows (either 1048576 or the eventual trim with the memory or dictionary or having less rows). Once the first Delta-Store would get filled, then the next Delta-Store would be filled and so on and so forth.
No matter how good your actual execution plan for reading data part is, the insertion will typically probably be the slowest performing part of your query.
This type of serial insertion for tables with Columnstore Indexes in SQL Server 2014 have some good advantage – in a normal case you would have only 1 Delta-Store not completely filled (the last one) and it might be actually an open Delta-Store, that you can close with a COMPRESS_ALL_ROW_GROUPS = ON hint while invoking ALTER TABLE REORGANIZE command or fill it with more data later.
In SQL Server 2016 when executing INSERT SELECT WITH (TABLOCK) type of command, we have a parallel insertion plan for the databases, that have compatibility level set to 130:
 Depending on the number of available resources for the query (such as memory and the CPU cores) we can have a separate Delta-Store for each of the used CPU cores that will be receiving data in parallel fashion. From the logical perspective, if we have enough Drive capacity for sustaining X times faster data writes, where X is the number of CPU cores used in the query, than we shall have around X times improvement for the data loading.
Depending on the number of available resources for the query (such as memory and the CPU cores) we can have a separate Delta-Store for each of the used CPU cores that will be receiving data in parallel fashion. From the logical perspective, if we have enough Drive capacity for sustaining X times faster data writes, where X is the number of CPU cores used in the query, than we shall have around X times improvement for the data loading.
From the Delta-Store fullness & trimming perspective it will mean, that we shall be typically trimming the last X Delta-Stores, where X is the number of CPU cores used in the query. This is a quite clear X times disadvantage compared to the serial insertion, but which can be mitigated with Alter Index Reorganize command in SQL Server 2016 (see upcoming blog post on the Segment Merging).
Note that if you are using Compatibility Level below 130 with TABLOCK hint, then you should have the very same functionality as in SQL Server 2014,
or if you are not using TABLOCK hint while inserting, then the insertion will stay serial like in SQL Server 2014.
Enough with introductional and theoretical stuff, let’s see it in practice:
With my favourite test database, ContosoRetailDW, I shall restore a fresh copy, upgrading it to 130 compatibility level, then dropping the primary key & foreign keys for the test table FactOnlineSales, where I shall create a Clustered Columnstore Index:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered index PK_FactOnlineSales
on dbo.FactOnlineSales( OnlineSalesKey ) with ( maxdop = 1);
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales
with( drop_existing = on, maxdop = 1 );
Now let’s create a small partial copy of our FactOnlineSales table, using SQL Server 2016 syntax, allowing us to define Clustered Columnstore Index inline :)
CREATE TABLE [dbo].[FactOnlineSales_CCI](
[OnlineSalesKey] [int] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
INDEX PK_FactOnlineSales_CCI CLUSTERED COLUMNSTORE
);
Now I shall simply load 10 Million rows from FactOnlineSales into my new empty table with Clustered Columnstore Index (notice that I do not force parallel insertion):
truncate table [dbo].[FactOnlineSales_CCI];
set statistics time, io on;
insert into [dbo].[FactOnlineSales_CCI]
(
OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey
)
select distinct top 10000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey
FROM [dbo].[FactOnlineSales] sales
inner join dbo.DimProduct prod
on sales.ProductKey = prod.ProductKey
inner join dbo.DimStore store
on sales.StoreKey = store.StoreKey
where prod.ProductSubcategoryKey >= 10
and store.StoreManager >= 30
option (recompile);
 It took 30.0 seconds to load the data and so the data insertion part of the execution plan was serial.
It took 30.0 seconds to load the data and so the data insertion part of the execution plan was serial.
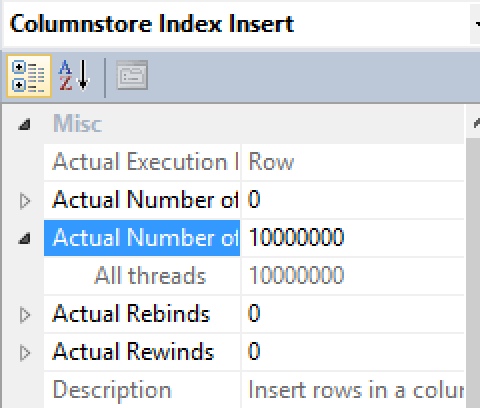 The properties of the Columnstore Index Insert iterator show only 1 thread with all 10 Million Rows being inserted at once. This results in generating a sequential insertion into the Delta-Stores which shall be automatically compressed into the Row Groups & Segments, so the final result should represent a number CEIL(10000000/1048576) of compressed Row Groups, where the last Row Group is trimmed with the resting number of rows.
The properties of the Columnstore Index Insert iterator show only 1 thread with all 10 Million Rows being inserted at once. This results in generating a sequential insertion into the Delta-Stores which shall be automatically compressed into the Row Groups & Segments, so the final result should represent a number CEIL(10000000/1048576) of compressed Row Groups, where the last Row Group is trimmed with the resting number of rows.
To verify, let’s execute the following query, which shall list all the Row Groups from our test table:
select * from sys.column_store_row_groups where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI' order by row_group_id asc;
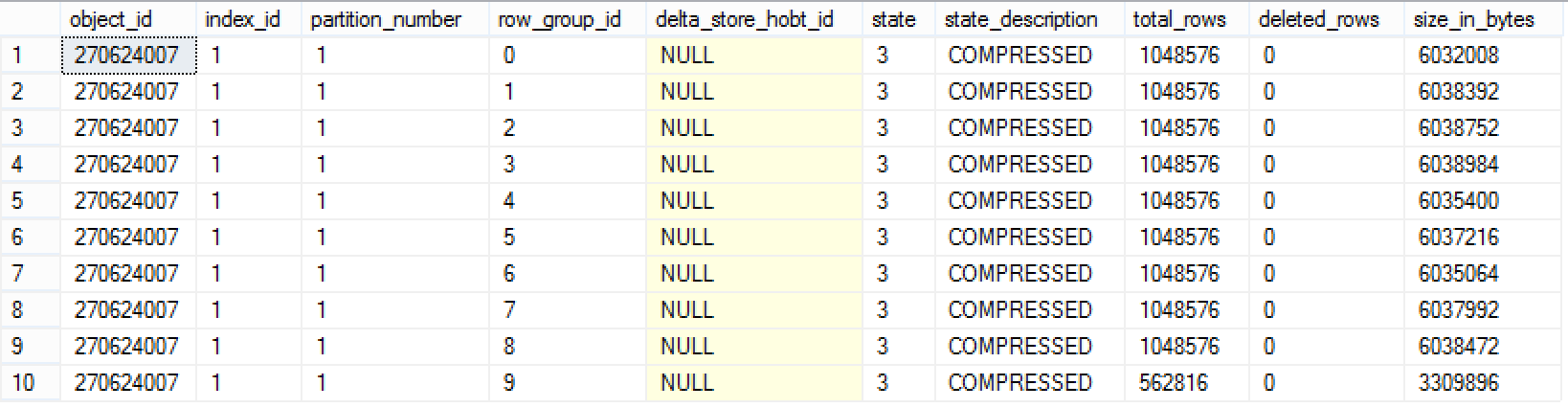 You can see on the picture that in my case I have loaded 10 Row Groups with only the last one being trimmed by the loading process.
You can see on the picture that in my case I have loaded 10 Row Groups with only the last one being trimmed by the loading process.
The second time I will select to load data with TABLOCK hint applied on the inserted table:
truncate table [dbo].[FactOnlineSales_CCI];
set statistics time, io on;
insert into [dbo].[FactOnlineSales_CCI] WITH (TABLOCK)
(
OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey
)
select distinct top 10000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey
FROM [dbo].[FactOnlineSales] sales
inner join dbo.DimProduct prod
on sales.ProductKey = prod.ProductKey
inner join dbo.DimStore store
on sales.StoreKey = store.StoreKey
where prod.ProductSubcategoryKey >= 10
and store.StoreManager >= 30
option (recompile);
 17 Seconds later I had my data loaded into my table. Going from 1 to 4 cores in my case allowed me to improve the performance almost 2 times, which is not a bad result, considering that I have a rather small (10 Million Rows) sample running on the pretty fast SSD drive.
17 Seconds later I had my data loaded into my table. Going from 1 to 4 cores in my case allowed me to improve the performance almost 2 times, which is not a bad result, considering that I have a rather small (10 Million Rows) sample running on the pretty fast SSD drive.
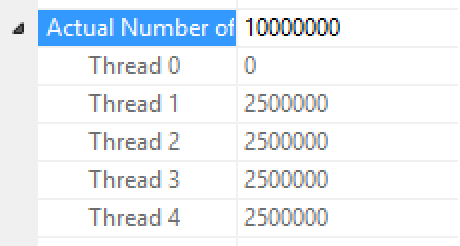 Looking at the Columnstore Index Insert iterator properties (shown on the right), you can see that the 10 million rows were equally distributed between my 4 cores (threads).
Looking at the Columnstore Index Insert iterator properties (shown on the right), you can see that the 10 million rows were equally distributed between my 4 cores (threads).
Let’s check how our Row Groups do look like after the parallel insertion:
select * from sys.column_store_row_groups where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI' order by row_group_id asc;
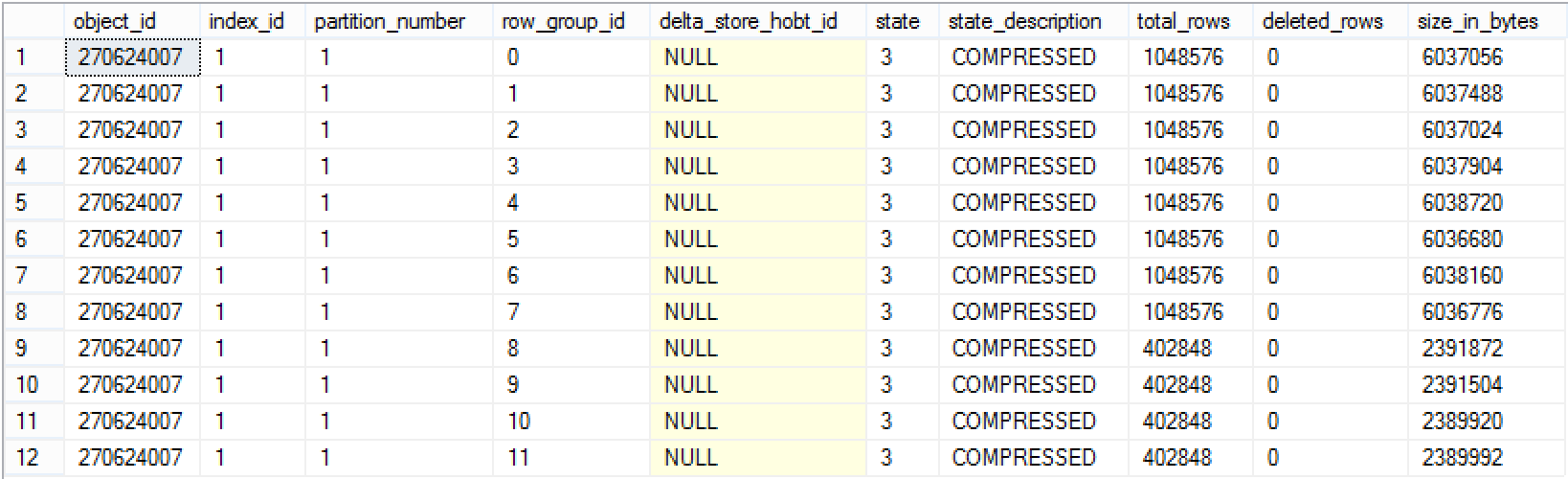 This time around we have received not 10 but 12 Row Groups, with the last 4 ones being trimmed by the equally distributed number of rows, exactly as we have expected. You have to pay for the performance and the payment is those trimmed Row Groups, though they impact is naturally relatively low if you are loading bigger amounts of data.
This time around we have received not 10 but 12 Row Groups, with the last 4 ones being trimmed by the equally distributed number of rows, exactly as we have expected. You have to pay for the performance and the payment is those trimmed Row Groups, though they impact is naturally relatively low if you are loading bigger amounts of data.
Also, do not forget that you can always look at the one of the newest DMV’s – sys.dm_db_column_store_row_group_physical_stats for checking for the reasons of the Row Groups trimming:
select * from sys.dm_db_column_store_row_group_physical_stats where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI' order by generation;
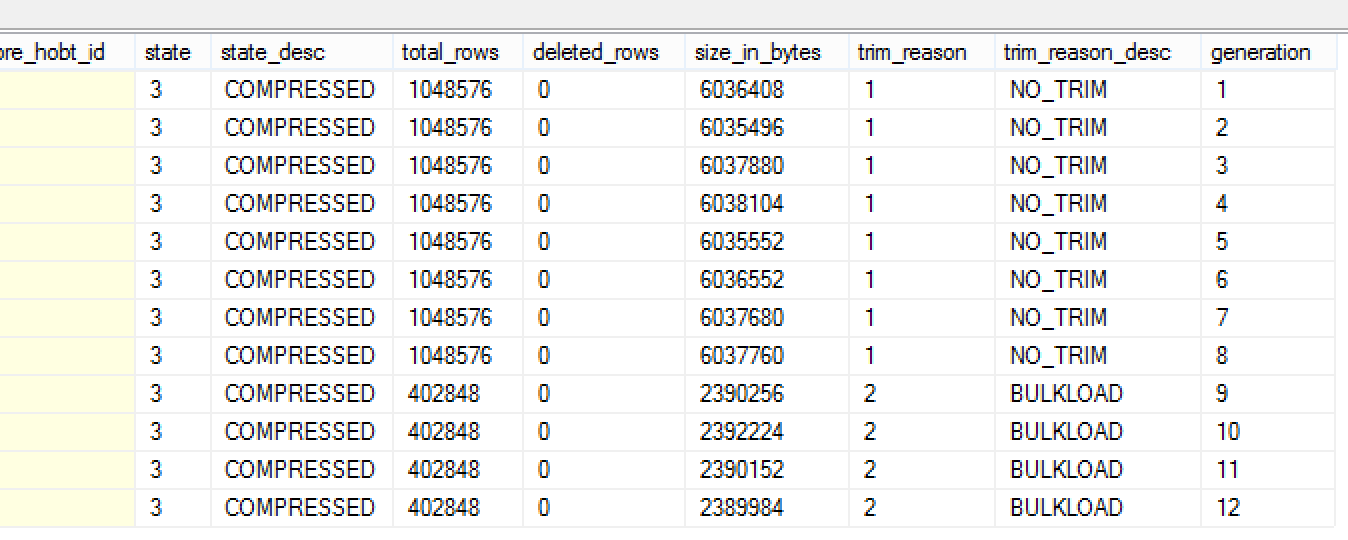 You can see on the partial screenshot on the left that the reason for the trimming of those Row Groups is the BULKLOAD, which clearly explains you the situation – allowing you to avoid running Extended Events to find it out.
You can see on the partial screenshot on the left that the reason for the trimming of those Row Groups is the BULKLOAD, which clearly explains you the situation – allowing you to avoid running Extended Events to find it out.
The maximum number of optimisable trimmed Row Groups for the single loading process equals X-1, where X is the number of used cores. This means that in practice if you are running a Server with MAXDOP = 8, per each of the load parallel insertion loading process you are generating up to 7 optimisable Row Groups, something to consider before kicking of the loading process.
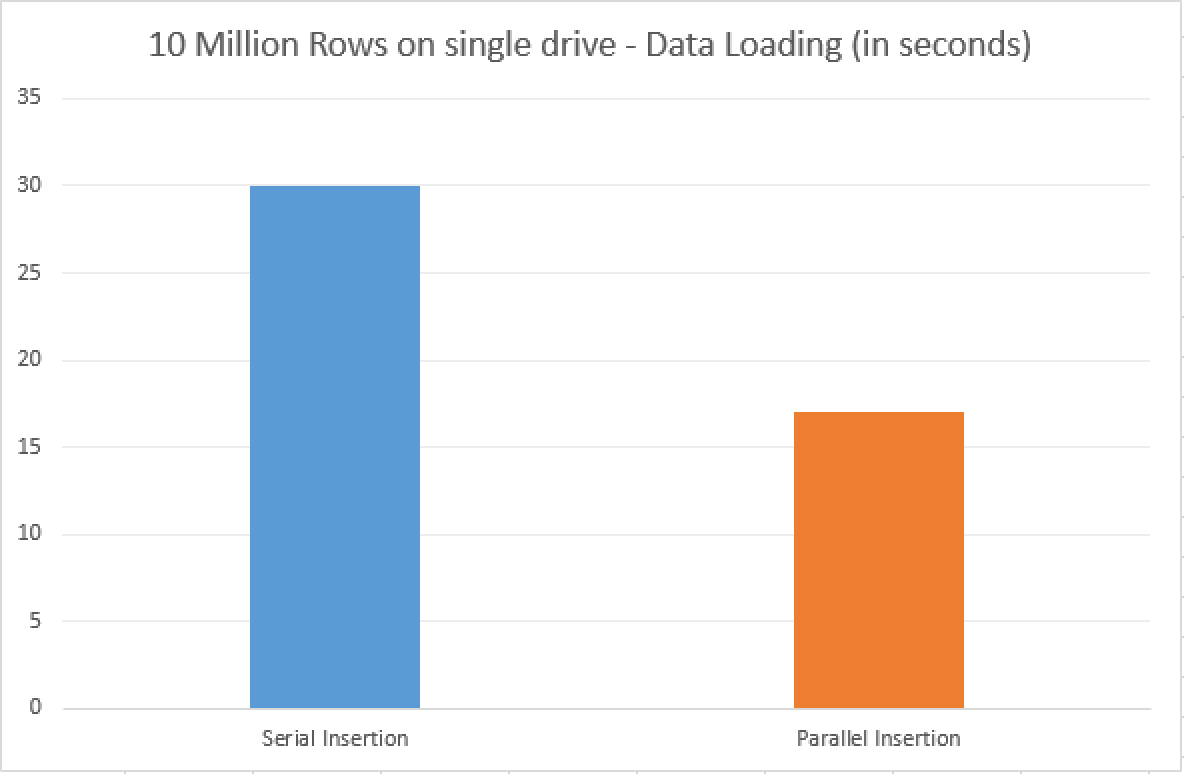 The results for this small test, based on the VM with SQL Server 2016 CTP 2.2 and the 4 cores + fast SSD show almost double performance improvement, which should vary extremely in real situation, based on the type of data you are loading (any pressures such as memory or dictionary?), type & location of the disk drives, etc …
The results for this small test, based on the VM with SQL Server 2016 CTP 2.2 and the 4 cores + fast SSD show almost double performance improvement, which should vary extremely in real situation, based on the type of data you are loading (any pressures such as memory or dictionary?), type & location of the disk drives, etc …
Test it before you apply it in the production is all I can say.
NonClustered Columnstore
I wish I could say write the same words about updatable Nonclustered Columnstore Indexes (aka Operational Analytics), but all my tests shown that the insertion in the current CTP 2.2 version not only works
CREATE TABLE [dbo].[FactOnlineSales_NCCI](
[OnlineSalesKey] [int] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
INDEX IX_FactOnlineSales_NCCI Nonclustered Columnstore ([OnlineSalesKey],[StoreKey],[ProductKey],[PromotionKey],[CurrencyKey],[CustomerKey])
);
Running a similar (but with just 4 Million Rows, instead of 10 Million Rows that were tested for Clustered Columnstore) insertion into this HEAP table, takes at least 40 seconds, with memory requirements easily exploding and flooding TempDB through spilled sorting operations when using Clustered Rowstore Table:
truncate table [dbo].[FactOnlineSales_NCCI];
set statistics time, io on;
insert into [dbo].[FactOnlineSales_NCCI] WITH (TABLOCK)
(
OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey
)
select distinct top 4000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey
FROM [dbo].[FactOnlineSales] sales
inner join dbo.DimProduct prod
on sales.ProductKey = prod.ProductKey
inner join dbo.DimStore store
on sales.StoreKey = store.StoreKey
where prod.ProductSubcategoryKey >= 10
and store.StoreManager >= 30
option (recompile);
 You can see the execution plan for itself, besides insertion into the heap we naturally need to update our Nonclustered Columnstore Structure, which is getting hit pretty hard with what seems to be a non-BULK based load process.
You can see the execution plan for itself, besides insertion into the heap we naturally need to update our Nonclustered Columnstore Structure, which is getting hit pretty hard with what seems to be a non-BULK based load process.
To prove it, execute the following script right after the loading finishes:
select * from sys.column_store_row_groups where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_NCCI' order by row_group_id asc;
 Notice that none of the Row Groups are compressed, all 4 of them are Delta-Stores, with 3 being closed ones and 1 is still open, which for me is the best signal that the load process was single threaded and not using Bulk Load API.
Notice that none of the Row Groups are compressed, all 4 of them are Delta-Stores, with 3 being closed ones and 1 is still open, which for me is the best signal that the load process was single threaded and not using Bulk Load API.
Hope that this will be improved in the current version of SQL Server …
InMemory OLTP & Clustered Columnstore
Of course I could not escape without testing Hekaton version of Clustered Columnstore Index, and so I executed the following script, enabling InMemory OLTP on my test database and then creating a InMemory table with Clustered Columnstore Index:
use master;
GO
ALTER DATABASE [ContosoRetailDW]
ADD FILEGROUP [ContosoRetailDW_Hekaton]
CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE [ContosoRetailDW]
ADD FILE(NAME = ContosoRetailDW_HekatonDir,
FILENAME = 'C:\Data\xtp')
TO FILEGROUP [ContosoRetailDW_Hekaton];
GO
use ContosoRetailDW;
GO
CREATE TABLE [dbo].[FactOnlineSales_Hekaton](
[OnlineSalesKey] [int] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
Constraint PK_FactOnlineSales_Hekaton PRIMARY KEY NONCLUSTERED ([OnlineSalesKey]),
INDEX IX_FactOnlineSales_Hekaton_NCCI Clustered Columnstore
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Since I have only 8GB of RAM on this VM, I had to limit the number of rows that I attempted to load with this InMemory configuration, even though my resource pool for memory was already set on 75%.
I have decided to load just 3 Million of Rows, naturally avoiding TABLOCK hint, since it is as one might have expected is not currently supported (Truncate is not supported in this version of CTP as well):
delete from [dbo].[FactOnlineSales_Hekaton];
set statistics time, io on;
insert into [dbo].[FactOnlineSales_Hekaton]
(
OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey
)
select distinct top 3000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey
FROM [dbo].[FactOnlineSales] sales
inner join dbo.DimProduct prod
on sales.ProductKey = prod.ProductKey
inner join dbo.DimStore store
on sales.StoreKey = store.StoreKey
where prod.ProductSubcategoryKey >= 10
and store.StoreManager >= 30
option (recompile);
36 Seconds. Yes, I got the point – it is not though and not well suited for this type of operations. But still, you know – I have got to try :)
Take a look at the execution plan.
 Yes, scary as you can imagine, without any Columnstore Index Insert iterator, the information about it is hidden inside Clustered Index Insert, just consult it’s properties …
Yes, scary as you can imagine, without any Columnstore Index Insert iterator, the information about it is hidden inside Clustered Index Insert, just consult it’s properties …
Ok, Ok – I am not writing more on the InMemory Columnstore for the current version 2.X of CTP, I am waiting for the 3.X series, since this version is still extremely rough and definitely is being in progress.
Final Thoughts
Great Improvements for data loading into Clustered Columnstore – they are extremely welcome. One will have to make a well-thought decision before opting to use parallel insertion. It might not be worth it in a number of situation, unless the speed is the paramount – this is where you will definitely want to use it.
to be continued with Columnstore Indexes – part 64 (“T-SQL Improvements in SQL Server 2016”)
Good article about the 2016 new stuff.
but, does SQL 2016 is able to do parallel insert when we are using SSIS to load the data and not a simple insert into … select statement?
because for now, I still see only 1 core running at a time during the insertion process.
So I see 1million rows loaded, then compressed, then another 1million transferred, compressed etc… but but 4millions in parallel.
so how to use the new parallel processing option when loading data using SSIS?
Hi Jerome,
this functionality is designed for the t-sql execution (stage->dwh transfer for example), and it does not work with SSIS unfortunately.
Best regards,
Niko
Hello Niko,
I compared sequential vs parallel insert in term of final size and on my test the result is that the compression ratio is not the same : 30% less compressed when using parallel insert !
My table is quite large : 355 columns, may be this impact compression ratio ?
Regards
Romain
Hi Romain,
you will need to provide a little bit more details in order for me to understand.
Which SQL Server version are you using ? (2016, 2017, 2019)
Do you use any partitioning ?
How does parallel insert affect the size of the Row Groups ?
How does parallel insert affect the overall execution time performance?
Big number of columns will result in a bigger requirements for the memory which will force Row Group trimming, which might cause significantly poorer compression … But it is all a speculation unless there is more info.
Best regards,
Niko
Hi Niko
Tested on 2016 and 2017 Dev. Ed.
Several Tests with a 290 columns tables :
Tests with insertion of 1229768 rows
A) No partitioned table :
A.1 SEQUENTIAL INSERT MAXDOP 0 : Final Size : 107 MBytes / Elasped : 139s / 50% cpu used
A.2 PARALLEL INSERT MAXDOP 4 : Final Size : 231 MBytes (+115%) / Elasped : 128s / 100% cpu used
B) partitioned table :
B.1 SEQUENTIAL INSERT MAXDOP 0 : Final Size : 120 MBytes / Elasped : 139s / 50% cpu used
B.2 PARALLEL INSERT MAXDOP 4 : Too long , killed after 1 hour, their is a sort in row mode that slow down the query (duration estimation to finish 10hours…) even if you insert data for only one partition
here is the column definition “profile” :
CREATE TABLE #temptable ( [coltype] nvarchar(151), [colcount] int )
INSERT INTO #temptable
VALUES
( N’date(3)’, 1 ),
( N’time(5,7)’, 2 ),
( N’int(4)’, 4 ),
( N’datetime(8,3)’, 6 ),
( N’float(8)’, 8 ),
( N’decimal(5)’, 31 ),
( N’decimal(5,1)’, 2 ),
( N’decimal(5,2)’, 2 ),
( N’decimal(5,5)’, 1 ),
( N’decimal(9)’, 6 ),
( N’decimal(9,2)’, 11 ),
( N’decimal(9,3)’, 13 ),
( N’nvarchar(2)’, 93 ),
( N’nvarchar(4)’, 9 ),
( N’nvarchar(6)’, 29 ),
( N’nvarchar(8)’, 18 ),
( N’nvarchar(12)’, 1 ),
( N’nvarchar(16)’, 2 ),
( N’nvarchar(18)’, 1 ),
( N’nvarchar(20)’, 27 ),
( N’nvarchar(24)’, 2 ),
( N’nvarchar(26)’, 1 ),
( N’nvarchar(28)’, 1 ),
( N’nvarchar(30)’, 1 ),
( N’nvarchar(32)’, 3 ),
( N’nvarchar(34)’, 1 ),
( N’nvarchar(36)’, 7 ),
( N’nvarchar(44)’, 3 ),
( N’nvarchar(50)’, 1 ),
( N’nvarchar(70)’, 2 ),
( N’nvarchar(80)’, 1 )
SELECT * FROM #temptable
DROP TABLE #temptable;
And the get_fragmentation result (CSIL)
CREATE TABLE #temptable ( [TableName] nvarchar(517), [IndexName] nvarchar(128), [Location] varchar(10), [IndexType] nvarchar(4000), [Partition] int, [Fragmentation Perc.] decimal(5,2), [Deleted RGs] int, [Deleted RGs Perc.] decimal(5,2), [Trimmed RGs] int, [Trimmed Perc.] decimal(5,2), [Avg Rows] bigint, [Total Rows] bigint, [Optimisable RGs] decimal(30,0), [Optimisable RGs Perc.] decimal(8,2), [Row Groups] int )
INSERT INTO #temptable
VALUES
( N'[dbo].[Delivery_Details_DEFAULT_COLUMNSTORE_NOPARTITION_PARALLEL_INSERT_MAXDOP4]’, N’i0′, ‘Disk-Based’, N’CLUSTERED’, 1, 0.00, 0, 0.00, 72, 100.00, 16361, 1177997, 70, 97.22, 72 ),
( N'[dbo].[Delivery_Details_DEFAULT_COLUMNSTORE_NOPARTITION_SEQUENTIAL_INSERT_MAXDOP1]’, N’i0′, ‘Disk-Based’, N’CLUSTERED’, 1, 0.00, 0, 0.00, 5, 100.00, 245953, 1229768, 3, 60.00, 5 ),
( N'[dbo].[Delivery_Details_DEFAULT_COLUMNSTORE_PARTITION_PARALLEL_INSERT_MAXDOP4]’, N’i0′, ‘Disk-Based’, N’CLUSTERED’, 1, 0.00, 0, 0.00, 1, 100.00, 1, 1, 0, 0.00, 1 ),
( N'[dbo].[Delivery_Details_DEFAULT_COLUMNSTORE_PARTITION_SEQUENTIAL_INSERT_MAXDOP1]’, N’i0′, ‘Disk-Based’, N’CLUSTERED’, 8, 0.00, 0, 0.00, 3, 100.00, 233017, 699051, 2, 66.67, 3 ),
( N'[dbo].[Delivery_Details_DEFAULT_COLUMNSTORE_PARTITION_SEQUENTIAL_INSERT_MAXDOP1]’, N’i0′, ‘Disk-Based’, N’CLUSTERED’, 9, 0.00, 0, 0.00, 2, 100.00, 262145, 524290, 1, 50.00, 2 )
SELECT * FROM #temptable
DROP TABLE #temptable
It seems you was right for trimming RG with parallel insert.
What also is interesting is that parallel insert in a clustered columnstore indexed table that is partitionned is thousand time slower than sequential insert.
Hi Romain,
yeap, the Partitioned operations are in fact are noticeable slower for a number of people. I hope that some fixes in the next SQL Server version will address at least some of those limitations.
Also remember that every partition of the CCI (Clustered Columnstore) is a Clustered Columnstore Index itself, meaning it has its own Delta-Stores, Global & Local Dictionaries, etc – and that’s the reason why you will see duplication and less sophisticated compression overall, when having highly repetitive values in your partitioned table.
Best regards,
Niko Neugebauer