Continuation from the previous 61 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
I have spoken a lot of times on the aspect of the Columnstore Indexes maintenance during my presentations, and I have even written 2 blogposts
Columnstore Indexes – part 36 (“Maintenance Solutions for Columnstore”) & Columnstore Indexes – part 57 (“Segment Alignment Maintenance”) plus I have created a Connect Item on another important aspect of it – Columnstore Segments Maintenance – Remove & Merge, but one thing I kept talking and even writing about it’s analysis improvement in SQL Server 2016 (Columnstore Indexes – part 56 (“New DMV’s in SQL Server 2016″)) I have never dedicated a whole post.
It’s name is Row Groups Trimming and this is the event that happens when your Row Groups do not reach the maximum allowed number of rows, but getting closed & compressed before.
It’s time to write about it now. :)
For setup, I will run the following script on the free ContosoRetailDW database, it will restore the database, drop the foreign key constraints, primary key and create a clustered columnstore index on my test table FactOnlineSales.
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]
-- Create Clustered Columnstore Index
Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales;
I will run the following exercise on the SQL Server 2014 instance, and later will switch to SQL Server 2016 to show what was improved in the upcoming version.
We expect everything to be perfect or as close to perfect as possible, hoping to have 1048576 rows in each and every Row Group. To have Row Groups close to the maximum allowed value (1048576 rows) will allow us to have the fastest read-ahead operations possible (should those Segments MB-sized) and Segment Elimination (we can eliminate vast amounts of data a number of times).
Let’s check the results with the query against sys.column_store_row_groups DMV:
select *
from sys.column_store_row_groups
where object_id = object_id('dbo.FactOnlineSales')
order by row_group_id;
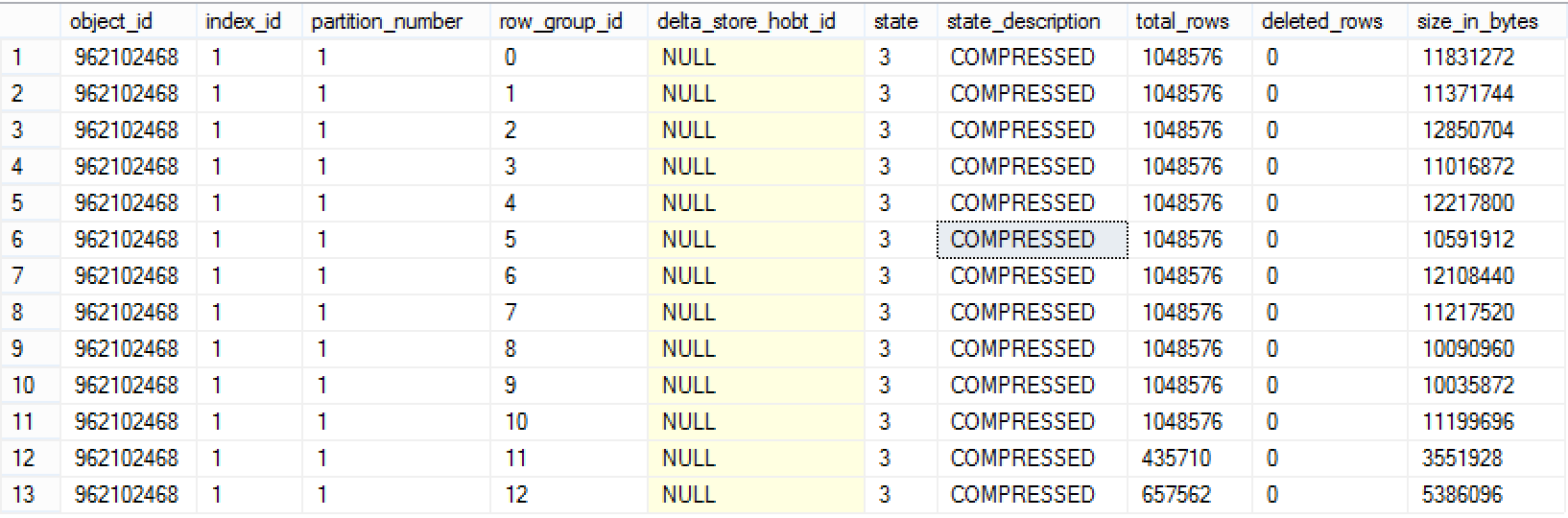 You can see that from 13 Row Group that I have, only the last 2 did not reached the maximum allowed number of rows – they have 435710 & 657562 rows respectively. We can make an educated guess, that because the sum of those rows (1093272) is superior to the maximum allowed number of rows in a Row Group (1048576), the engine decided to split them between 2 Row Groups, while achieving a good compression trying to balance them right.
You can see that from 13 Row Group that I have, only the last 2 did not reached the maximum allowed number of rows – they have 435710 & 657562 rows respectively. We can make an educated guess, that because the sum of those rows (1093272) is superior to the maximum allowed number of rows in a Row Group (1048576), the engine decided to split them between 2 Row Groups, while achieving a good compression trying to balance them right.
In SQL Server 2014 we have no possibility to do a correct post-mortem analysis, we can run the respective Extended Events while rebuilding the index, which would help us to determine the cause of the Row Groups trimming, but should we arrive on the scene after the rebuild we can only determine the cause in SQL Server 2016 with the introduction of the sys.dm_db_column_store_row_group_physical_stats DMV.
We have a number of ways to get smaller then the maximum number of rows inside a Row Group:
– Upgrade from a previous version
– Bulk Load (loading more then 102400 Rows and not dividable amount on 1048576 Rows will produce smaller Row Groups)
– Alter Index Reorganize operation invocation. Especially the one with the COMPRESS_ALL_ROW_GROUPS = ON hint :)
– Memory Pressure.
– Dictionary Pressure.
– Not having exact number of rows that is dividable through 1048576.
Note that also in practice running Rebuilds with DOP > 1 will produce unevenly distributed Row Groups.
To exemplify what I am writing here about, imagine that we are loading data from 2 files, each with 110.000 Rows. For that, I will export this amount of data from the FactOnlineSales into a text file on the disk, enabling xp_cmdshell before:
-- ***************************************************************** -- Enable XP_CMDSHELL EXEC master.dbo.sp_configure 'show advanced options', 1 RECONFIGURE EXEC master.dbo.sp_configure 'xp_cmdshell', 1 RECONFIGURE EXEC xp_cmdshell 'bcp "SELECT top 110000 * FROM ContosoRetailDW.[dbo].[FactOnlineSales]" queryout "C:\Install\FactOnlineSales.rpt" -T -c -t,';
Now I will import that amount of information into FactOnlineSales twice:
BULK INSERT dbo.[FactOnlineSales]
FROM 'C:\Install\FactOnlineSales.rpt'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR ='\n'
);
BULK INSERT dbo.[FactOnlineSales]
FROM 'C:\Install\FactOnlineSales.rpt'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR ='\n'
);
Now, if we run the same analysis query agains sys.column_store_row_groups DMV, we shall see 2 extra Row Groups, each one with 110K Rows:
select *
from sys.column_store_row_groups
where object_id = object_id('dbo.FactOnlineSales')
order by row_group_id;
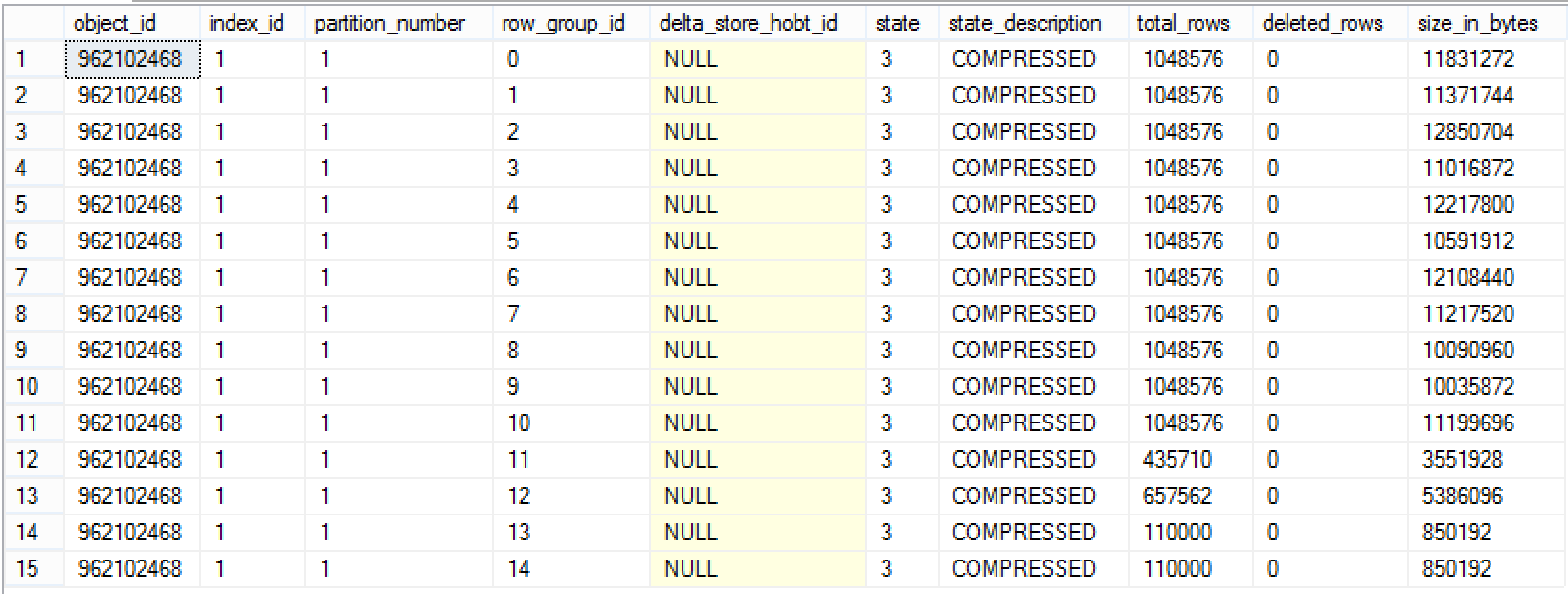 Now with 2 more not full Row Groups the situation has got a little bit more different – now we might have some percentage of the not full Row Groups that actually might require a rebuild of the table or respective partition!
Now with 2 more not full Row Groups the situation has got a little bit more different – now we might have some percentage of the not full Row Groups that actually might require a rebuild of the table or respective partition!
Let’s run a simply analytical query, which will count the number of non-full (aka Trimmed) Row Groups:
SELECT object_schema_name(p.object_id) + '.' + object_name(p.object_id) as 'TableName',
ind.name as 'IndexName',
ind.type_desc as 'IndexType',
p.partition_number as'Partition',
sum( case rg.total_rows when 1048576 then 0 else 1 end ) as 'Trimmed Segments',
cast(sum( case rg.total_rows when 1048576 then 0 else 1 end ) * 1. / count(*) * 100 as Decimal(5,2)) as 'Trimmed Perc.',
avg(rg.total_rows - rg.deleted_rows) as 'Avg Rows',
count(*) as 'Segments'
FROM sys.partitions AS p
INNER JOIN sys.column_store_row_groups rg
ON p.object_id = rg.object_id
INNER JOIN sys.indexes ind
on rg.object_id = ind.object_id and rg.index_id = ind.index_id
where rg.state in (2,3) -- Compressed & Closed
and ind.type in (5,6) -- Index Type (Clustered Columnstore = 5, Nonclustered Columnstore = 6. Note: There are no Deleted Bitmaps in NCCI in SQL 2012 & 2014)
and rg.object_id = object_id('dbo.FactOnlineSales')
group by p.object_id, ind.name, ind.type_desc, p.partition_number
order by object_schema_name(p.object_id) + '.' + object_name(p.object_id);
![]() This result shows us an important piece of analysis for our table on partition basis: the number of Trimmed Row Groups, the total Percentage of the Trimmed Row Groups, Average Number of Rows in a Row Group and the total number of Row Groups.
This result shows us an important piece of analysis for our table on partition basis: the number of Trimmed Row Groups, the total Percentage of the Trimmed Row Groups, Average Number of Rows in a Row Group and the total number of Row Groups.
We have 4 Trimmed Row Groups – This is nice, but what does it exactly mean ?
Let us abstract from the number of trimmed Row Groups and their total percentage, and simply take the average number of rows and by calculating the total size of the table, to see if we can potentially optimize the number of Row Groups by making it smaller:
RES = CEILING ( 856507*15./1048576) = 13
This means that if we Rebuild this table, in the best case we should be able to lower the total number of Row Groups by 2 (from 15), which represents a very good percentage ~13%!
Applying this logic, here is an updatable version of the very same query, which will provide me with the optimised numbers that I do not have to calculate manually any more:
SELECT object_schema_name(p.object_id) + '.' + object_name(p.object_id) as 'TableName',
ind.name as 'IndexName',
ind.type_desc as 'IndexType',
p.partition_number as'Partition',
sum( case rg.total_rows when 1048576 then 0 else 1 end ) as 'Trimmed RG',
cast(sum( case rg.total_rows when 1048576 then 0 else 1 end ) * 1. / count(*) * 100 as Decimal(5,2)) as 'Trimmed Perc.',
avg(rg.total_rows - rg.deleted_rows) as 'Avg Rows',
count(*) - ceiling(count(*) * 1. * avg(rg.total_rows - rg.deleted_rows) / 1048576) as 'Optimizable RGs',
cast((count(*) - ceiling(count(*) * 1. * avg(rg.total_rows - rg.deleted_rows) / 1048576)) / count(*) * 100 as Decimal(8,2)) as 'Optimizable RGs Perc.',
count(*) as 'Segments'
FROM sys.partitions AS p
INNER JOIN sys.column_store_row_groups rg
ON p.object_id = rg.object_id
INNER JOIN sys.indexes ind
on rg.object_id = ind.object_id and rg.index_id = ind.index_id
where rg.state in (2,3) -- Compressed & Closed
and ind.type in (5,6) -- Index Type (Clustered Columnstore = 5, Nonclustered Columnstore = 6. Note: There are no Deleted Bitmaps in NCCI in SQL 2012 & 2014)
and rg.object_id = object_id('dbo.FactOnlineSales')
group by p.object_id, ind.name, ind.type_desc, p.partition_number
order by object_schema_name(p.object_id) + '.' + object_name(p.object_id);
![]() Now this is much better & interesting view.
Now this is much better & interesting view.
But wait a second, is this really a 3rd perspective ? Yes, because we have no deleted rows at the moment, and the Segment Alignment can be tuned externally (by creating a )
SELECT object_schema_name(p.object_id) + '.' + object_name(p.object_id) as 'TableName',
ind.name as 'IndexName',
replace(ind.type_desc,' COLUMNSTORE','') as 'IndexType',
p.partition_number as 'Partition',
cast( Avg( (rg.deleted_rows * 1. / rg.total_rows) * 100 ) as Decimal(5,2)) as 'Fragmentation Perc.',
sum (case rg.deleted_rows when rg.total_rows then 1 else 0 end ) as 'Deleted RGs',
cast( (sum (case rg.deleted_rows when rg.total_rows then 1 else 0 end ) * 1. / count(*)) * 100 as Decimal(5,2)) as 'Deleted RGs Perc.',
sum( case rg.total_rows when 1048576 then 0 else 1 end ) as 'Trimmed RGs',
cast(sum( case rg.total_rows when 1048576 then 0 else 1 end ) * 1. / count(*) * 100 as Decimal(5,2)) as 'Trimmed Perc.',
avg(rg.total_rows - rg.deleted_rows) as 'Avg Rows',
count(*) - ceiling(count(*) * 1. * avg(rg.total_rows - rg.deleted_rows) / 1048576) as 'Optimizable RGs',
cast((count(*) - ceiling(count(*) * 1. * avg(rg.total_rows - rg.deleted_rows) / 1048576)) / count(*) * 100 as Decimal(8,2)) as 'Optimizable RGs Perc.',
count(*) as 'Segments'
FROM sys.partitions AS p
INNER JOIN sys.column_store_row_groups rg
ON p.object_id = rg.object_id
INNER JOIN sys.indexes ind
on rg.object_id = ind.object_id and rg.index_id = ind.index_id
where rg.state in (2,3) -- 2 - Closed, 3 - Compressed (Ignoring: 0 - Hidden, 1 - Open, 4 - Tombstone)
and ind.type in (5,6) -- Index Type (Clustered Columnstore = 5, Nonclustered Columnstore = 6. Note: There are no Deleted Bitmaps in NCCI in SQL 2012 & 2014)
and rg.object_id = object_id('dbo.FactOnlineSales')
group by p.object_id, ind.name, ind.type_desc, p.partition_number
order by object_schema_name(p.object_id) + '.' + object_name(p.object_id);
![]() From the picture above, one can see that there is no deleted fragmentation, but there is a great opportunity to improve our table Trimmed Groups fragmentation, and by doing it to lower the overall number of Row Groups by ~13.33%.
From the picture above, one can see that there is no deleted fragmentation, but there is a great opportunity to improve our table Trimmed Groups fragmentation, and by doing it to lower the overall number of Row Groups by ~13.33%.
I will invoke the rebuild process for the Clustered Columnstore Index, by issuing ALTER INDEX REBUILD command:
alter table dbo.FactOnlineSales rebuild with(maxdop = 1);
Consulting the last analytical command shows the following result:
![]() Now I can see that our total number of Row Groups has lowered to 13 as expected, and even though we have 2 Trimmed Row Groups, the average number of rows per Row Group is so high, that we can theoretically further improve only 1 Row Group by moving more data into it, though it might provoke a certain misbalance in overall performance (Imagine synchronising Row Groups with 10 Rows & 1 Million Rows).
Now I can see that our total number of Row Groups has lowered to 13 as expected, and even though we have 2 Trimmed Row Groups, the average number of rows per Row Group is so high, that we can theoretically further improve only 1 Row Group by moving more data into it, though it might provoke a certain misbalance in overall performance (Imagine synchronising Row Groups with 10 Rows & 1 Million Rows).
You will need to very careful when using this view results, because the number of trimmed Row Groups might actually say nothing – If we have 10.000 Row Groups with 1048575 rows (1 row less than maximum allowed value), then there is no chance we can optimize anything. From a different point of view, if we have just incomplete 1 Row Group (once again imagine it has 1048575 rows), then we have 100% of trimmed Row Groups, but we can’t optimize it any further.
When considering Row Groups Trimming (3rd perspective besides Deleted Rows and Segment Alignment), focus on the number of optimisable Row Groups, it is the real number that truly matters.
Note that an enhanced version of this script is a part of my upcoming free Columnstore Indexes Scripts Library.
to be continued with Columnstore Indexes – part 63 (“Parallel Data Insertion”)
hello Niko! thank you for teaching so interesting topics!
there is a typo in the tsql for cci rubuild, there is an alter table rebuild instead of alter index
sometimes I see you using 1048576 and sometimes 1045678 ~ Is this a typo or intentional ?
Hi Suhas,
thank you for pointing out – has been doing this silly error for ages at that blog post time.
I corrected the information now.
Best regards,
Niko