Continuation from the previous 58 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
SQL Server 2016 brings a number of significant improvements in the relation of Columnstore Indexes performance and improvements in String Predicate Pushdown were already described in Columnstore Indexes – part 58 (“String Predicate Pushdown”), but wait – there are more things that will improve your existing queries performance!
SQL Server 2016 is bringing Aggregate Predicate Pushdown.
The Theory
Aggregation is one of the most common and most useful operation in any analytical processing. Before any significant amount of data can be presented to the user, it needs to be filtered and aggregated, and we all know that the final users will not scroll through pages of the results, but want to have an overview with < 100 rows, that they can potentially drill down in order to discover more details. Aggregation by itself is a process of using some statistical functions such as Min, Max, Avg or similar for processing the rows that are being aggregated. Applying those functions on large amounts of data can take a significant portion of the processing time of analytical query.
In SQL Server 2016 Microsoft has implemented a possibility to push some of the Aggregations right into the storage level, thus greatly improving performance of this type of analytical queries.
It is worth to mention that traditionally Aggregate Pushdown is being described as the operation of attempting to move the Aggregation Operation down through the join operations in the execution plan, with 2 types of situation that were called Eager Aggregation & Lazy Aggregation.
In the case of the Aggregate Pushdown in SQL Server, we are talking about implementing support for the aggregate calculations on the Storage Engine level, thus improving the overall performance of the query through sparing additional work for the CPU. This is the same type of operation that is happening for any other Pushdowns (Columnstore Indexes – part 58 (“String Predicate Pushdown”) &
Clustered Columnstore Indexes – part 49 (“Data Types & Predicate Pushdown”) ) that I have described in the previous blog posts.
At the moment, Microsoft has listed the following aggregate functions that will be receiving Predicate Pushdown support: COUNT, COUNT_BIG, SUM, AVG, MIN & MAX. and CLR.
The most interesting part here is naturally the mentioning of the CLR – one would not expect a heavy investment in this are for SQL Server 2016, and so it is a very nice surprise to say at least.
Also it is very important to note that it is apparent that SIMD instructions support will be implemented, and so using the latest & greatest CPU processors might bring you an additional advantage.
After good & exciting news, there is always a little space for the current limitations:
only the data types that are occupying 8 bytes of space or less are supported.
Let’s go and test it with a free database ContosoRetailDW, I am running the traditional setup script:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Now, let’s run a couple of tests for aggregate functions on the SQL Server 2016 CTP 2.0 & CTP 2.1 on our test table FactOnlineSales:
Test 1 (4 bytes Integer):
set statistics time, io on
select max(SalesQuantity)
from dbo.FactOnlineSales;
If you will execute this query a couple of times, making sure that the table data is already in the memory (Columnstore Object Pool & Buffer Pool respectively), you might see a similar execution times, which are nothing short of impressive, given that our table contains 12.6 Million Rows:
SQL Server Execution Times: CPU time = 16 ms, elapsed time = 8 ms.
Now, if I execute the same query on a SQL Server instance with SQL Server 2014 SP1,the best result I am getting is here:
SQL Server Execution Times: CPU time = 124 ms, elapsed time = 65 ms.
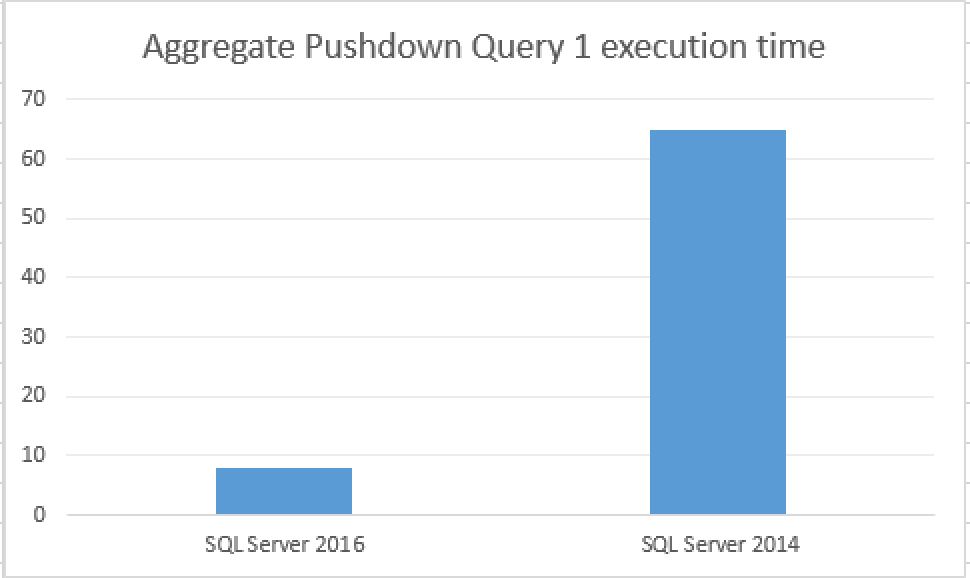 Take a good at the picture with the final results, the difference is really staggering – we are taking almost ~8 times difference in the total execution time. This is really impressive, since the elapsed time on the test query at SQL Server 2016 seems to be not using a lot of resources at all.
Take a good at the picture with the final results, the difference is really staggering – we are taking almost ~8 times difference in the total execution time. This is really impressive, since the elapsed time on the test query at SQL Server 2016 seems to be not using a lot of resources at all.
Let take a look at the execution plans in different SQL Server versions in order to see the differences:
SQL Server 2016 CTP 2.0
SQL Server 2016 CTP 2.1
Looking at the pictures, you will notice that the earlier CTP has provided a different visual representation for the data movement between Columnstore Index Scan and Hash Match iterators were quite different. To be more precise, the thin line in CTP 2.0 was showing 0 (zero) rows flowing from the Columnstore Index Scan, which was definitely wrong, but in the latest CTP 2.1 we can see all rows (~12.6 Million) are being transferred. From the other side there is no visual identification that the Aggregate has been succesfully pushed down into the Columnstore Index scan and this information would be extremely valueable for the performance analysis.
Test 2 (8 bytes Money):
For the 2nd test I will use different aggregation on a different data type – this time going with AVG for the aggregation and choosing the maximum allowed length for the data type – 8 bytes:
select avg(SalesAmount) from dbo.FactOnlineSales;
For the SQL Server 2016 CTP 2.1 I have the following result:
SQL Server Execution Times: CPU time = 31 ms, elapsed time = 35 ms.
The same query executed on SQL Server 2014 SP1 resulted in the following times:
SQL Server Execution Times: CPU time = 95 ms, elapsed time = 63 ms.
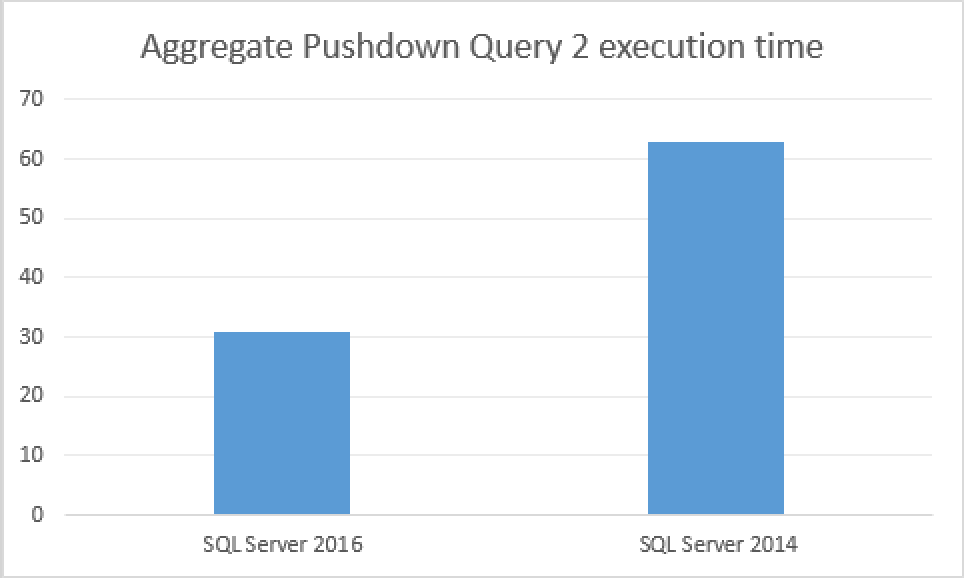 The difference between the systems is still impressive, but at the same time much less significant as for the data type containing just 4 bytes, we are talking here about 2 times in performance improvement.
The difference between the systems is still impressive, but at the same time much less significant as for the data type containing just 4 bytes, we are talking here about 2 times in performance improvement.
![]() In the execution plan, the only difference in the execution plan to find here is the Compute Scalar iterator, which is simply ensuring that some kind of result is being returned to the user (non empty). The rest of the execution plan is similar to the 1st query, with Columnstore Index Scan delivering the rows to
In the execution plan, the only difference in the execution plan to find here is the Compute Scalar iterator, which is simply ensuring that some kind of result is being returned to the user (non empty). The rest of the execution plan is similar to the 1st query, with Columnstore Index Scan delivering the rows to
Test 3 (40 bytes, Nvarchar(20)):
For the third query, I have deliberately chosen to use an aggregate on the data type that is not officially supported for Aggregate Pushdown in SQL Server 2016 – this was a Nvarchar(20) column. :)
set statistics time, io on select max(SalesOrderNumber) from dbo.FactOnlineSales;
After executing on both VMs with SQL Server 2016 CTP 2.1 & SQL Server 2014 SP1, I have obtained the following results:
SQL Server Execution Times: CPU time = 2359 ms, elapsed time = 1220 ms.
SQL Server Execution Times: CPU time = 2437 ms, elapsed time = 1248 ms.
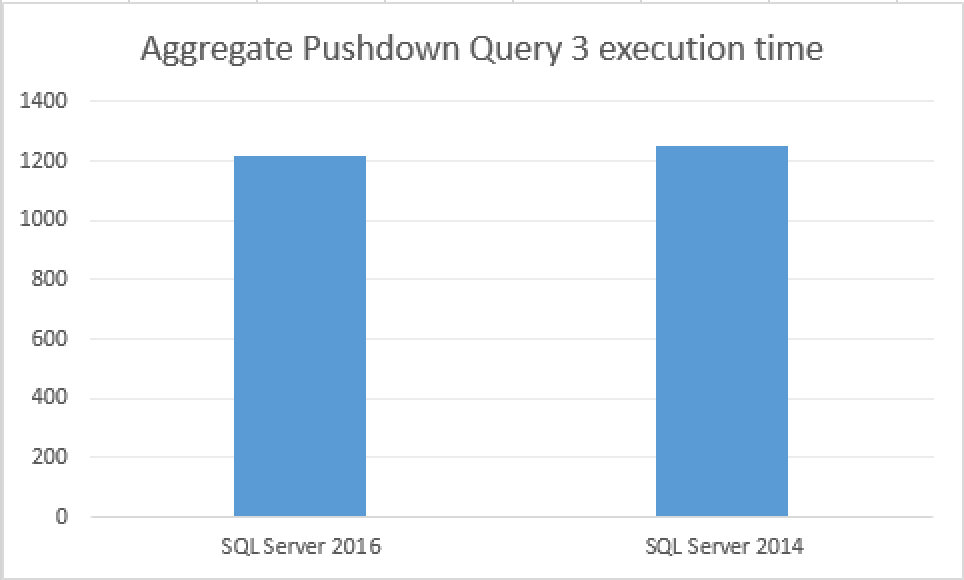 Looking at the picture of the query execution times, you will find yourself searching for any significant difference – with no success at all. Using an unsupported data type (oh those strings … :)), occupying up to 42 bytes (20*2+2) at the area where no improvements have been made …
Looking at the picture of the query execution times, you will find yourself searching for any significant difference – with no success at all. Using an unsupported data type (oh those strings … :)), occupying up to 42 bytes (20*2+2) at the area where no improvements have been made …
Ok, that’s fine, but what about the execution plan? Is there something in it that might help us to understand if the Aggregate Pushdown has taken place or not ?

Well, here it is – right now, if you are seeing the Stream Aggregate (Aggregate) operator instead of the Hash Match Aggregate (Partial Aggregate) iterator in your execution plan, this is a good indication that your Aggregate is not being pushed down to the Storage Engine.
Unfortunately at the moment, there is no information whatsoever inside the XML of the execution plan, that would indicate Aggregate Pushdown existence, but there is still enough time to get it in before the RTM. :)
Notes and final thoughts:
Another interesting issue that I have observed in SQL Server 2016 CTP 2.1 is that introduction of the Group By into T-SQL statements with Aggregate functions makes them quite slow – to my understandings the Aggregate Pushdown is not happening in this case, consider the performance of the slightly modified Test Query 1:
select sales.ProductKey, sum(sales.SalesQuantity) from dbo.FactOnlineSales sales group by sales.ProductKey;
No one would expect that the performance of the above query would go to be that slow:
CPU time = 220 ms, elapsed time = 177 ms.
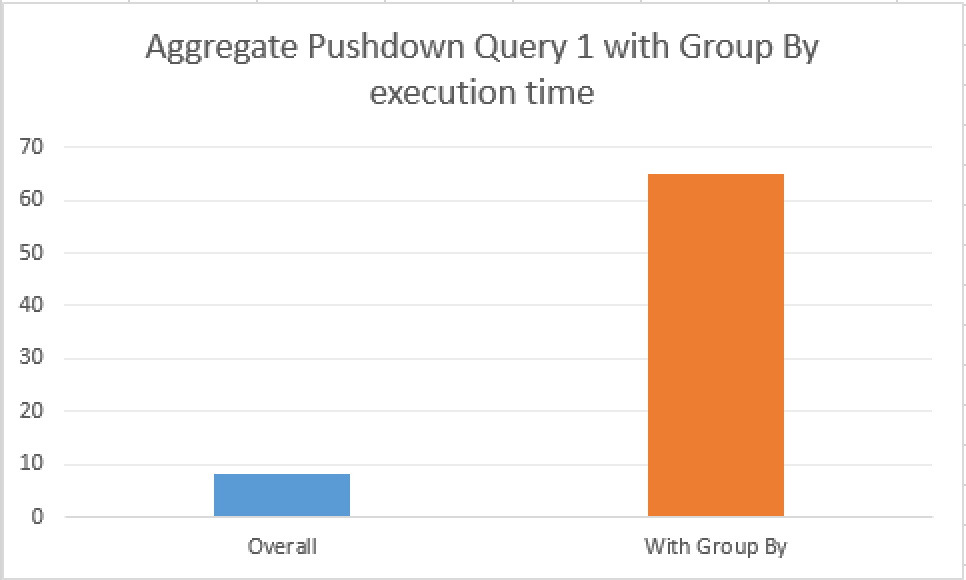 For better understanding take a look at the picture comparing the performance of overall table scan with the similar statement containing Group By part. To me, it seems that the support for Group By statement is simply not implemented so far, and I consider it to be important enough to appear in the RTM of the SQL Server 2016.
For better understanding take a look at the picture comparing the performance of overall table scan with the similar statement containing Group By part. To me, it seems that the support for Group By statement is simply not implemented so far, and I consider it to be important enough to appear in the RTM of the SQL Server 2016.
Overall a great performance improvement which is definitely going to improve the life of those running analytical query on SQL Server 2016, but there are definitely things to improve in the current beta-version, and this is the reason why it is being called CTP – Community Technology Preview.
to be continued …
As I understand it aggregate pushdown is implemented by using SIMD to process values. SIMD and hash table writes are not easy to make work because the writes might overlap. (Even hash table reads are hard because the number of bucket accesses is dynamic and unbounded per key being probed.) I do not see how any pushdown to the storage engine could be beneficial here. The regular hash table operators can just work on the column batches as usual. I doubt there will be pushdown for GROUP BY.
Which makes this feature pretty useless. I frankly do not see the point. It is rare to perform a global aggregation. I’d rather see them work on something else such as dictionary pressure and segment size.
I agree on the matter of lacking support for GROUP BY would render this feature quite limited.
It would surprise me in a way, that an investment would have been done for a small percentage of cases, since Microsoft has always had in mind a majority of the market.
As for controlling the segment size & dictionary pressure – yeah, that would be some major improvements.
Hi Niko, for your Test 1 case ie ‘select max(SalesQuantity) from dbo.FactOnlineSales;’ on SQL Server 2016 CTP 2.2 I get an actual execution plan showing an actual number of rows being 0 and estimated number rows being ~12 million. So it looks like it’s back to the way it was in CTP 2.0. ie wrong.
Hi –
I have not tested 2.2 in the details – and so thank you very much for the details.
I believe that Microsoft has not decided internally on how to implement this feature and so we might see some changes until RTM.
Best regards,
Niko