Continuation from the previous 53 parts, the whole series can be found at https://www.nikoport.com/columnstore/
This is a not very deep technical post, which is describing the upcoming news and changes in SQL Server 2016.
Since there is no public CTP (Community Technology Preview), there is no chance (well besides doing Technet Virtual Labs with SQL Server 2016 CTP 1.3 :))
The reason that at the moment I am not publishing my tests at the moment is that according to all my sources, SQL Server 2016 CTP 2.0 the public preview version will contain a lot of very significant changes and speculating on the alpha version of software is a very ungrateful task as all of the readers know on the personal examples.
This blogpost marks a definitive turning point where I am officially changing the series name from Clustered Columnstore to Columnstore, because as you will see below the upcoming changes are bringing a very significative updates for Nonclustered Columnstore Indexes.
At the very first Ignite conference in Chicago between the 4-8th of May in 2015, Microsoft have revealed the following improvements for the Columnstore Indexes in SQL Server 2016:
– Operational Analytics (Updatable Nonclustered Columnstore Indexes on traditional Rowstore tables)
– In-Memory Analytics (Updatable In-Memory Nonclustered Columnstore Indexes on In-Memory OLTP tables)
– Nonclustered Rowstore Indexes on the tables with Clustered Columnstore Indexes
– Primary & Foreign Keys support for the tables with Clustered Columnstore Indexes
– Readable Secondaries for Availability Groups – Snapshot & Read Committed Snapshot Isolation Levels support
– Batch Mode support for 1 core execution plan operators
– Batch Mode support for the Sort operator
– Batch Mode support for the Multiple Distinct Count operations
– Batch Mode support for the Left Anti-Semi Join operators
– Batch Mode support for the Windowing functions
– String Predicte Pushdown for the Clustered Columnstore Index Scan operator in Batch Mode
– Simple Aggregate Predicate Pushdown
– Significantly improved performance for the Data Loading for Columnstore Indexes (including SIMD support)
– Better Index Reorganize (removes deleted rows, less memory pressure)
– Automated column ordering during Columnstore build process (very speculative)
– Full MARS support
– Very significantly improved monitoring and diagnostics for the Columnstore Indexes operation and maintenance
Operational Analytics (Updatable Nonclustered Columnstore Indexes on traditional Rowstore tables)
Operational Analytics is the term that is constructed from 2 important concepts: Operations (traditionally described as an OLTP, this concept is basically describing the working processing of any business) & Analytics (the concept focusing on discovery of meaningful patterns in operational data).
Typically there was a very significant delay between those 2 modules, since they were located separately (different databases or different servers). While Operations (OLTP) focused from its side on the 3rd normal form structured database, Analytics were typically optimised for reporting workloads with DataWareHousing layout technics.
In my personal point of view, in the modern IT world, the majority of the world has largely changed and moved from the one-side operational + one-side analytical workloads into more close to real-time reporting and analytics requirements.
Business does not want to wait until the next data loading cycle (next hour/next day/next week/next month), some business reporting is expected to be run as soon as possible, preferably real-time.
This requirement has created a number of problematic situations, where a number of solutions were trying to satisfy the Analytics scenarios with traditional indexes or applying CDC or similar solutions, and maintaining reporting data updated manually.
As Sunil Agarwal mentioned it very eloquently in Operational Analytics Podcast at Data Exposed Show, a more precise name for this feature would be Real-Time Analytics, since it is concerned with getting data for Analytics without any delay, as close to the real-time as it is technically possible.
 In SQL Server 2016, Microsoft has announced a possibility to create an strong>updatable Nonclustered Columnstore Index, which will be updated without any additional efforts for the Solution Developer.
In SQL Server 2016, Microsoft has announced a possibility to create an strong>updatable Nonclustered Columnstore Index, which will be updated without any additional efforts for the Solution Developer.
In SQL Server 2012 and in SQL Server 2014 the Nonclustered Columnstore Index was non-updatable, making the table where it was defined read-only, right after its creation. This made it only feasible for the DataWareHousing solutions, where data is loaded during some specific periods or where data can be updated on the partition basis.
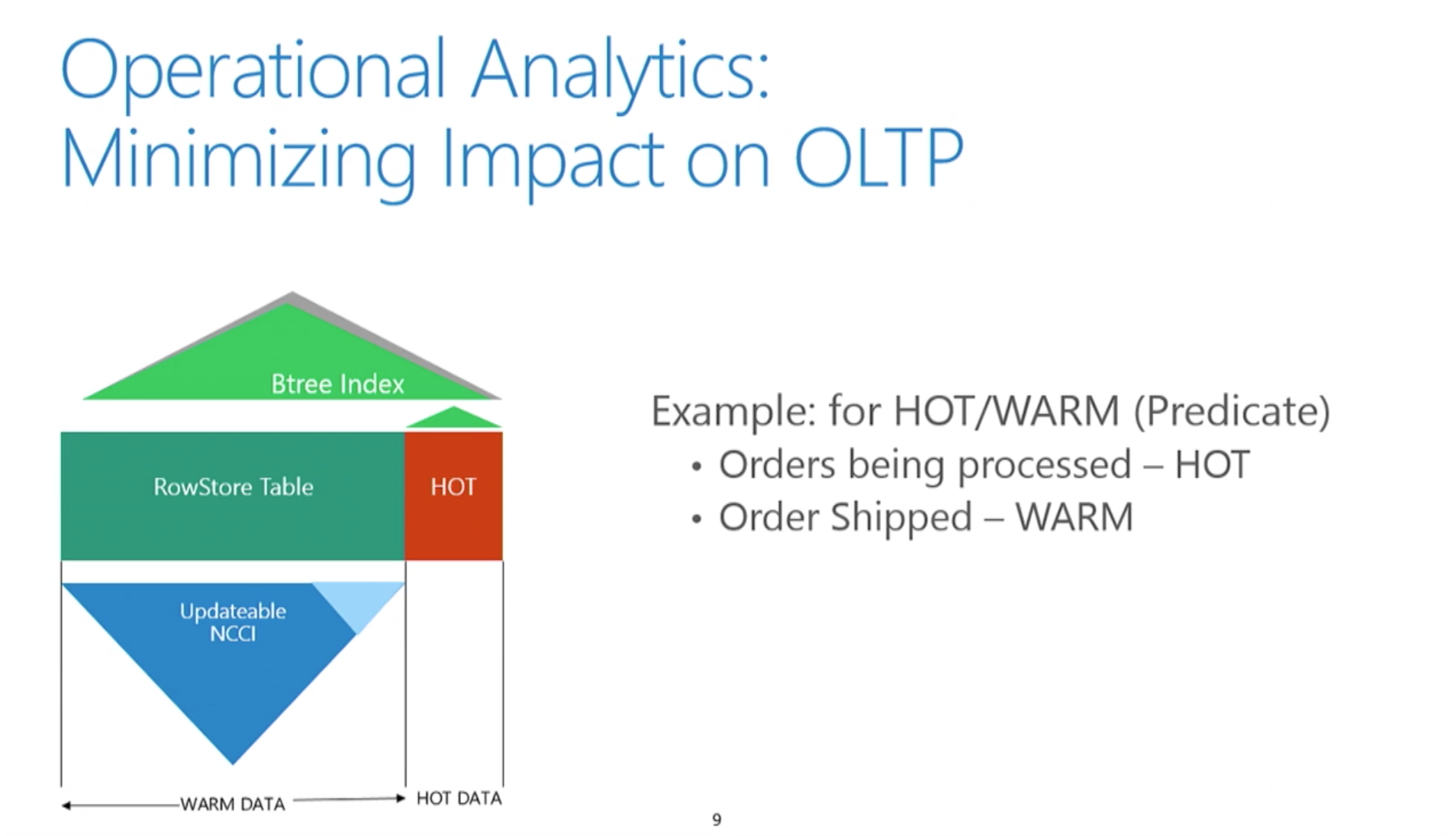
On the picture on the left you can see the combination of the traditional Row-Store & Columnstore Architectures for the same table. RowStore Indexes will provide support for the Operational functionality and the Columnstore Indexes will be providing the optimised performance for the Analytical workloads. The key here is the definition of the Hot Data & the Warm Data.
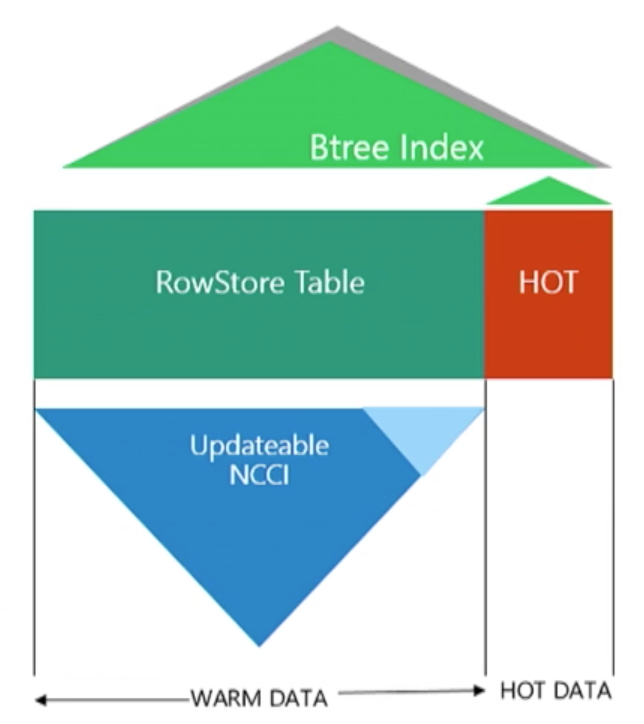 The Hot Data is the part which is being currently accessed by the most processes of the OLTP – this is the data that is being read, written & updated constantly, the data which changes with high frequency. This part of data will not be present at the Columnstore Index, since its synchronisation would be a total nightmare and would seriously impact the performance of the Operations as well as the performance of the Analytics.
The Hot Data is the part which is being currently accessed by the most processes of the OLTP – this is the data that is being read, written & updated constantly, the data which changes with high frequency. This part of data will not be present at the Columnstore Index, since its synchronisation would be a total nightmare and would seriously impact the performance of the Operations as well as the performance of the Analytics.
The Warm data is the one which is not updated frequently (hence warm) and thus being accessed by Operational and Analytical workloads. For the Warm Data, the presence of the updatable Nonclustered Columnstore Index will provide the best performance, and should we need to do some operational lookup on it, there is always a traditional RowStore B-Tree structures which will keep on supporting those operations.
The definition of the predicate which will separate the Hot Data from the Warm Data will be done in 2 different ways – based on the concrete T-SQL predicate (such as status = “active”, for example) as well as the time based (Hot Data will become Warm Data after a certain number of days, 7 days for example).
The developer/dba will be ultimately responsible for defining the predicate(tipping point), which will separate the Hot Data from the Warm Data and this is exactly what I expect for such solution, because there is definitely no size which fits everyone.
A very important performance issue with this solution will be the insertion/update of the OLTP Data – the impact that it will suffer for keeping connection with the Columnstore Index. Another performance issue will be the scan of the data that includes the Hot Data + the Warm Data. How well will the merging of RowStore + Columnstore data will be performing ? Will the bottleneck be Row Execution Mode for the RowStore or the Merge between the 2 stores shall be the hotspot every single query will have to fight against ?
I am really excited to see what will be available in CTP2 for SQL Server 2016 for the Operational Analytics!
In-Memory Analytics (Updatable In-Memory Nonclustered Columnstore Indexes on In-Memory OLTP tables)
In-Memory Analytics refers to the mixture of the In-Memory OLTP (previously known as Hekaton) and Columnstore Indexes, the same way as the Operational Analytics functions. I would even call Super-Real-Time Analytics. :)
Here is I am wondering if the Columnstore Indexes will be truly In-Memory or if they will be persisted on the disk. Some of the Microsoft competition is not persisting their In-Memory Columnstore indexes and I am convinced that for SQL Server it would be very useful to have this type of solution as well. Logically we need to persist only 1 copy of the data on the disk, but from the different angle, for repairing the data, for example, it is extremely useful to have some data duplicated …
Nonclustered Rowstore Indexes on the tables with Clustered Columnstore Indexes
 Clustered Columnstore Indexes shall be greatly enhanced as well – like in the case of Operational Analytics, we shall receive possibility to mix Columnstore & RowStore structures for the same table.
Clustered Columnstore Indexes shall be greatly enhanced as well – like in the case of Operational Analytics, we shall receive possibility to mix Columnstore & RowStore structures for the same table.
This structure is definitely more adaptable for the scenarios where the major part of the workload is Reporting/Analyitcal in its nature. Here Clustered Columnstore Indexes will provide the biggest value as they already did in SQL Server 2014, but in SQL Server the existence of the RowStore B-Tree Indexes will allow to use the lookups for consulting small amounts of data, which is never so much feasible with Columnstore Indexes.
I was genuinely hoping to get this functionality for SQL Server 2014, but its better now then never! ;) Being able to create multiple Nonclustered Rowstore Indexes is something that will be extremely useful for a lot of environments. The same b-tree indexes should provide the so-much-needed Row-Level-Locking for the Columnstore Indexes structure, since as you should know that locking in Clustered Columnstore Indexes can get quite insane very easily. Getting an exclusive lock on your Row Group just because you are updating some data in the Delta-Store is not a very pleasant effect.
The Data Loading into Clustered Columnstore Indexes will become more slow (should you keep your indexes and not disable/drop them as the best practices would recommend), but this is something that is acceptable for the DWH solutions, since BI professionals responsible for ETL processes spend enough time making sure that they perform to the maximum of the Hardware ability.
Primary & Foreign Keys support for the tables with Clustered Columnstore Indexes
This is Huge – a lot of existing solutions are implemented with these important structures and not having them supported for years meant inability to convert those solutions to use Columnstore Indexes and was a major disappointment for everyone.
Naturally for the DataWareHouse Environments there will be enough people mentioning that that data Integrity should be guaranteed during ETL process and I do not argue with that. I argue that once you have loaded your data, you need the constraints like an old castle needs those safe protection walls.
Constraints are extremely helpful for the performance, since they allow Query Optimiser to make a lot of decisions and optimisations from this information. Even the classic book The Data Warehouse Toolkit talks enough on the matter of the foreign keys importance for the solution performance.
From the technical part I am wondering about the actual implementation and if its based on the RowStore Indexes that should be created in order to accompany the solution, or if the Primary Keys and Foreign Keys can function directly on the Columnstore Index.
Readable Secondaries for Availability Groups
The only 2 Isolation Levels support missing from the SQL Server 2014 were the ones that really matter for the scalability: Snapshot & Read Committed Snapshot, because they are the backbone for the Availability Groups support. As I already speculated in Azure Columnstore, part 2 – Snapshot Isolation & Batch Mode DOP, the support for both of them was already implemented in December 2014 and so we shall be able to spread our workload between the replicas in Availability Group in SQL Server 2016.
With the announced support for the balancer in Availability Groups, which will distribute read-only requests between the secondary replicas, this might bring a very significant performance improvement for the performance of BI solutions, I know a couple of companies that will be extremely happy about this improvement. :)
Batch Mode support for 1 core execution plan operators
The most anticipated feature for those, who do not have enough memory on their instances or playing a dangerous game of running Columnstore Workloads with DOP close to 1 – the Batch Execution Mode will support 1 core execution.
I have already highlighted that it was functioning in Azure in December 2014 and I am naturally happy to see it being transported to SQL Server 2016.
No more unexpected performance cliffs when the same query suddenly runs extremely slowly!
Batch Mode support for the Sort operator
Yes. Yes. Yes. Yes YES YES! Yes in a Batch Mode!
Sorting is inevitable element of the big part of the execution plans and knowing that once it will be hit, than everything will virtually stop is something that is not easy to deal with.
I expect this feature to be quite complicated to implement, since I do not think that every single execution plan with Sort operator should use Sort operator in Batch Mode – if we are sorting 10 rows, then spending a lot of resources for the preparations is just a useless waste of time. Hitting sweet spot with the implementation will be one of the biggest technical challenges for those responsible for the Execution Engine of SQL Server.
Batch Mode support for the Multiple Distinct Count operations
As I wrote around 2 years ago in Columnstore Indexes – part 19 (“Batch Mode 2012 Limitations … Updated!”), selecting multiple distinct aggregates works extremely slow in SQL Server 2012 & 2014, because the Query Processor uses Eager Spools. I am extremely happy to hear about the improvements in this area, I am using multiple Distinct Aggregates and splitting them into different queries is not a very practical thing to do.
Batch Mode support for the Left Anti-Semi Join operators
Nice improvement for some of the queries that are using constructs such as Not Exists. The Left Anti-Semi Join is basically returning all the rows from the top operator, that have no corresponding rows in the lower operator. The Left Anti-Semi Join is an opposite for the Left Semi Join operator, which represents a typical LEFT OUTER JOIN logic.
This is not a ground-shaking improvement, but still an important one – thus one by one the missing elements of the Execution Plan are getting more difficult to find.
Batch Mode support for the Window Functions
A lot of BI and DataWarehouse solutions are using Window Functions for complex calculations. Window Functions are composed from the Ranking, Aggregate & Analytical functions with some functionalities being available since SQL Server 2005 but with the most significant improvements implemented in SQL Server 2012.
Some of the most known and widely used of them are LAG and LEAD, to serve as an example.
I am using Window Functions in a number of projects, as they provide logic beyond the most trivial one of T-SQL and they allow to simplify greatly the code create and its maintenance.
I have personally seen a couple of situations where the query performance would stuck on the Window Functions performance and this is a very welcome improvements for anyone writing complex logic queries, and I would expect a lot of financial institutions using SQL Server to have a lot of code based on them.
A very very welcome improvement.
String Predicte Pushdown for the Clustered Columnstore Index Scan operator in Batch Mode
This will be one of the most important as well as one of the most underrated improvement in Columnstore in SQL Server 2016.
As I have written in Columnstore Indexes – part 49 (“Data Types & Predicate Pushdown”), the only important (and the most frequently used) data type that does not support neither Segment Elimination nor Predicate Pushdown is everything that is based on the strings – char, varchar, nchar & nvarchar data types.
Getting Predicate Pushdown supported means a lot for a lot of solutions that are using character types as the keys, or doing a lot of search on the fact tables based on string columns.
I can see hundreds of solutions based on SQL Server 2016 getting a great speedup (especially in the CPU terms) without doing anything at all – and this will be really amazing.
I am extremely excited about this improvement, since this is a kind of a bug fix to the functionality that was not implemented completely in SQL Server 2012 & 2014.
Simple Aggregate Predicate Pushdown
 This is another very significative addition to the Columnstore processing engine – some of the basic aggregate functions, such as Count(), Avg(), Min(), Max(), Sum() will be executed at the Storage Engine level, pushing the predicate closer to the storage and leveraging SIMD instructions. Important to notice here that in order to use this functionality, the respective column has to use a datatype with 8 bytes or less and … oh well … avoid strings.
This is another very significative addition to the Columnstore processing engine – some of the basic aggregate functions, such as Count(), Avg(), Min(), Max(), Sum() will be executed at the Storage Engine level, pushing the predicate closer to the storage and leveraging SIMD instructions. Important to notice here that in order to use this functionality, the respective column has to use a datatype with 8 bytes or less and … oh well … avoid strings.
Here I have a lot of questions on the specifics of the implementation:
– did the team considered the aggregation persistence at the storage level (storing a concrete value of aggregate function in a RowGroup – this would take almost no place and for major scan operations would work magic, with problems being associated with data removal and updates).
– another interesting question here is on the similarity and differences with Sybase implementation of the Aggregate Pushdown.
I am very excited about the potential improvements this feature might bring, though I am expecting a not very easy start and a very rough cut for the SQL Server 2016 version.
Significantly improved performance for the Data Loading for Columnstore Indexes (including SIMD support)
For this item, Microsoft has decided to advance with the changes for the data loading process for Columnstore Indexes, meaning that in SQL Server 2016, Query Engine will take a good use of the parallelism, by splitting the amount of the loaded data between the cores and insert it into different Delta-Stores in parallel.
Imagine if you have 4 Million Rows to load into a table with Clustered Columnstore Index – in SQL Server 2014, you will typically :) have 3 compressed Row Groups and an open Delta-Store with 1047568 rows and the insertion process will be executed single-threaded. In SQL Server 2016 we shall get a number of Row Groups (or Delta Stores), according to the number of cores used for the load process – for example if we are running this process on 8 cores, then depending on a number of factors and having none of the external or internal pressures we should get 8 Row Groups with 500.000 Rows each.
This parallelism will guarantee a significant improvement in the performance and it is like a good ETL parallel process that is simply implemented automatically.
A very welcome feature, especially since it should use the SIMD instructions, potentially improving the performance much further!
Better Index Reorganize (removes deleted rows, less memory pressure)
As I have mentioned it previously at Columnstore Indexes – part 34 (“Deleted Segments Elimination”), there is a very urgent need for better Row Group maintenance procedures. Executing update & delete statements creates a lot of trash (obsolete or removed versions of the rows) inside the Row Groups.
In such situations merging Row Groups that are not 100% full or that have a lot of deleted rows makes a lot of sense.
My Connect Item on this matter Columnstore Segments Maintenance – Remove & Merge was closed with the hopes of inclusion in the next version of SQL Server, and here we are – SQL Server 2016 is getting this feature through Alter Index Reorganize command.
This is a major maintenance & cleanup improvement and I am very happy about it ! :)
The other announced improvement for the maintenance and creation of the Columnstore Indexes i the less amount of memory required for the operations, which is a very important part for anyone dealing with huge tables and partitions.
I am looking very much forward into confirming what does it mean in practice.
Automated column ordering during Columnstore build process (very speculative)
It would be so great to have some kind of functionality that would allow us to do automatic ordering on the specific column inside the Columnstore Index, without forcing the explicit creation of the RowStore Index and then with a MAXDOP = 1 hint a creation of Columnstore Index.
If we would have some kind of a hint that would allow us to do that processing automatically – it would be beyond spectacular, since everyone loves Segment Elimination so much! :)
Warning: speculation ahead:
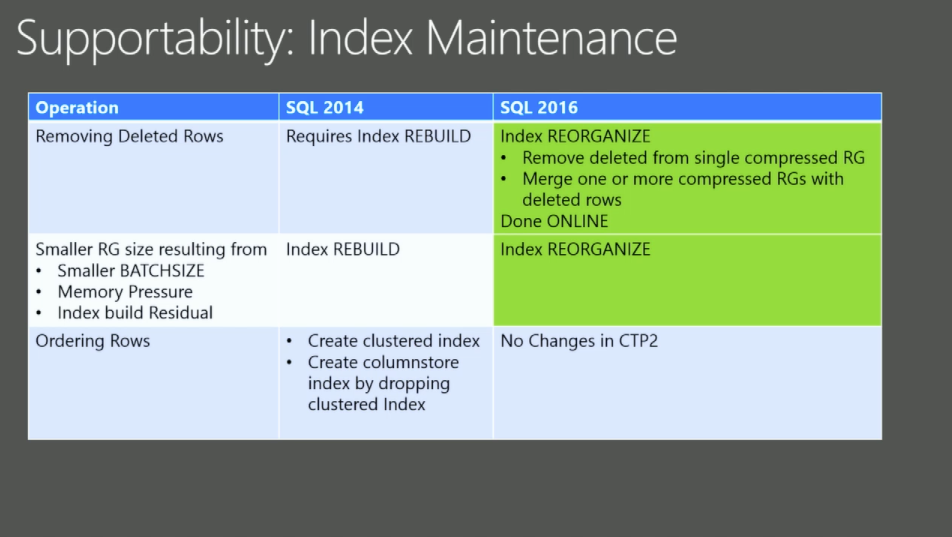 In one of his presentations at Ignite, Sunil Agarwal has published the part of the slide that I have inserted on the left side. This is the only slide on whole Ignite that I know about, where something is marked as “No Changes in CTP2”. :) If there are no plans for the changes, than those parts are typically avoided – so this gives me a lot of hope.
In one of his presentations at Ignite, Sunil Agarwal has published the part of the slide that I have inserted on the left side. This is the only slide on whole Ignite that I know about, where something is marked as “No Changes in CTP2”. :) If there are no plans for the changes, than those parts are typically avoided – so this gives me a lot of hope.
You know, hope is a wonderful thing, right? :)
Ah, and according to the public comment by Sunil on my Connect Item (Multi-threaded rebuilds of Clustered Columnstore Indexes break the sequence of pre-sorted segment ordering (Order Clustering) ), I am having some valid hopes :)
Niko: I am closign this as this is in the plans for next release. If this gets pushed out unepectedly, please feel free to re-activate
Full MARS support
Finally. I think that a number of vendors will be celebrating implementation of this feature. I remember seeing enough people on the internet commenting that they really really really need this feature.
I have not had any situation so far where I would desperately need this feature, but I can imagine enough situations where this feature will be truly desired.
Very significantly improved monitoring and diagnostics for the Columnstore Indexes operation and maintenance
For the situations when compressed Row Groups are trimmed naturally (not enough rows, parallelism, bulk load) or because of the pressure (Memory or Dictionary), we do not have a lot of ways of understanding the reason behind this, unless we were running Extended Events during the process of creation/rebuild.
Overall the monitoring possibilities in SQL Server 2014 were good but needed a significant improvement, which we are getting in SQL Server 2016.
In SQL Server 2016 we should be getting the following new DMVs:
- sys.dm_column_store_object_pool – this DMV will provide information on the Row Groups that are In-Memory (This should largely obsolete the methods I have described in Columnstore Indexes – part 38 (“Memory Structures”) & Columnstore Indexes – part 39 (“Memory in Action”))
- sys.dm_db_column_store_row_group_operational_stats – this view will provide us operational information on the locking and blocking, scan counts and other similar operational statistics. This information will facilitate greatly the access
- sys.dm_db_column_store_row_group_physical_stats – this view will give us the reasons for having trimmed groups inside our Columnstore Indexes, that I have mentioned above. To the standard reasons I would expect to have more new ones, surging after merge operations from ALTER INDEX REORGANIZE and automated processes for Nonclustered Columnstore Indexes
- sys.dm_db_index_operational_stats – this DMF is in my expectation is the underlying function that should provide similar information on operational usage stats for Columnstore and maybe even Rowstore indexes
- sys.dm_db_index_physical_stats – this DMF is in my expectation is the underlying function that should provide similar information on physical layout for Columnstore and maybe even Rowstore indexes
Notice that DMVs sys.dm_db_column_store_row_group_operational_stats & sys.dm_db_column_store_row_group_physical_stats have been exposed in Azure SQLDatabase for good 6 months already, as I mentioned in Azure Columnstore, part 1 – The initial Preview offering.
Regarding to the Extended Events, Microsoft promised to put a whole new category for Columnstore Indexes and I am expecting a wide range of new Extended Events that will be available in SQL Server 2016.
An especial focus for the Extended Events will be given to the state transition of the Row Groups (Compression, Merging, etc), this comes from the slides that Sunil has shown at Ignite and I am truly happy about those upcoming improvements.
Performance Monitor will be vastly improved with a whole new category dedicated to Columnstore Indexes. From the publicly shown slides, I have managed to read the following counters:
– Delta Rowgroups Created
– Delta Rowgroups Closed
– Delta Rowgroups Compressed
– Segment Cache Hit Ratio (cool!!!)
– Segment Reads/sec
– Total Delete Buffers Migrated (merge operation?)
– Total Merge Policy Evaluations
– Total Rowgroups Compressed
– Total Rowgroups Merge Compressed
– Total Source Rowgroups Merged
This is basically everything that has been revealed about SQL Server 2016 related to Columnstore technology so far. In the next blog posts I will go down one on one with each of this improvements and tests then on the public CTP 2 whenever it will go live.
to be continued with Columnstore Indexes – part 55 (“New Architecture Elements in SQL Server 2016”)
“since its synchronisation would be a total nightmare and would seriously impact the performance”
Who knows? Maintaining a delta store that has the same clustering key as the CI of the table would be quite fast. The two index maintenance operators would be directly after each other in the plan without intermediate sorting step. This is technologically feasible. Let’s see if the product does it well.
I wonder what the merge plan shape looks like for reads. If the rows of the hot and cold sets are distinct we simply need a batch mode concat which is laughably cheap.
“Here is I am wondering if the Columnstore Indexes will be truly In-Memory or if they will be persisted on the disk. ”
Agarwall said that they are not persisted and can impact table loading time. I found this to be not ideal. Should be tunable at least.
“Sorting is inevitable element of the big part of the execution plans and knowing that once it will be hit, than everything will virtually stop is something that is not easy to deal with.”
Yes. Once you start turning on batch mode for all plans (btw, did you get my email on that? I sent you how to enable batch mode in all queries, no matter whether they reference a CS index or not) you tend to see mostly hash based operations. I believe that is not purely because hashing is superior. I think this is because thanks to batch mode hash operators compare very favorably now. Maybe if we get batch mode sorting (and merging?!) this will be balanced again.
Aggregate Pushdown: Will this be only for global aggregates? It seems it will be because I cannot imagine how it cannot. That makes it less applicable to say the least.
It is a terrible change that data loading will now tend to produce less full row groups. This helps inserts and hurts queries.
In fact why can’t we choose segment size! The PowerPivot product can do that. I watched a presentation on that. They allow up to 16M rows per segment. I would very much like to turn that on to make use of the 16x more effective dictionaries and get much more sequential IO. Read-ahead does not cancel out the negative effects of small LOB sizes in CS indexes.
This is an awesome release. I expect this release to be the trigger for mainstream adoption. In my own adoption behavior I notice that the CS limitations are so severe right now that I only use it in the absolute sweet spot cases. Now I plan to convert many tables to CCI + some NC b-trees for point lookups and uniqueness. Or, simply add a NC CS index to existing tables and make analytics fly.
Hi Tobi,
>Let’s see if the product does it well.
Agreed! :)
>Yes. Once you start turning on batch mode for all plans (btw, did you get my email on that? I sent >you how to enable batch mode in all queries, no matter whether they reference a CS index or not)
Nope, please send it again, I have whitelisted your address to make sure it works this time. :)
I am very interested in learning new stuff on the batch mode.
>Maybe if we get batch mode sorting (and merging?!) this will be balanced again.
Sorting is already working batch mode. Limited, but works for a good number of cases. I would love to have Merge functioning in Batch Mode but I do not hold a candle on that.
>Aggregate Pushdown: Will this be only for global aggregates? It seems it will be because I >cannot imagine how it cannot. That makes it less applicable to say the least.
I will publish my experiences soon. :)
>It is a terrible change that data loading will now tend to produce less full row groups. This helps >inserts and hurts queries.
We have a Merge operation now ;) Alter Index Reorganize.
Plus we can monitor through DMV’s on the reasons our ETL processes produced lower number of rows.
>In fact why can’t we choose segment size! The PowerPivot product can do that. I watched a >presentation on that. They allow up to 16M rows per segment. I would very much like to turn >that on to make use of the 16x more effective dictionaries and get much more sequential IO. >Read-ahead does not cancel out the negative effects of small LOB sizes in CS indexes.
[crying] – (*sniff* … I … wish … *sniff*)
>This is an awesome release. I expect this release to be the trigger for mainstream adoption.
>In my own adoption behavior I notice that the CS limitations are so severe right now that I only >use it in the absolute sweet spot cases. Now I plan to convert many tables to CCI + some NC b->trees for point lookups and uniqueness. Or, simply add a NC CS index to existing tables and make >analytics fly.
Well … I agree, but I thought the same on many DWH Systems with SQL Server 2014, and the adoption still has its own curve.
The biggest win in Heap + NCCI combination is that you can choose the columns that you are adding into NCCI – thus avoiding those which are producing dictionary problems …
I wish to have a similar recipe for the CCI …
Best regards,
Niko Neugebauer
The dictionary pressure thing is quite aggravating. I am only used to such unnecessary and arbitrary cripplings on Azure normally.
Regarding adoption: I think the key is near zero effort adoption which is here now and was not present in 2014. Just create a CS index. No understanding necessary.
For operational analytics you might be right, but for DWH, SQL 2014 brought enough advantages with just 1 index to take care about.
While a lot of OLTP are using from Express to Standard editions mostly, any reasonable DWH needs to be on Enterprise.
Very exciting improvements! Thanks for your continued work in bringing us this series on columnstore, and I’m looking forward to your upcoming deeper dives on these features. And I now need to get Windows 8 so I can install CTP 2 myself…
Hi Geoff,
Thank you for the kind words – the whole “train” of new Columnstore blog posts is coming. :)
One of the best bloposts on SQL2016 columnstore improvements. Thanks.
Thank you for the kind comment, Damien!
Best regards,
Niko
Hi Niko,
Thanks for your detailed posts. I’m just starting out with column store indexes. Would it be sufficient to ‘start’ with this blog post onwards to understand columnstore indexes(especially in 2016) . As I understand SQL 2016 has a lot more features(Secondary B-Tree indexes, Referential integrity constraints and update table NCCI).
I assume it wouldn’t hurt to read all your posts (90+), however are there posts here that may no longer be applicable since SQL 2016 now has enhanced features?
Thanks
Hi JSAD,
just scroll all the articles in http://www.nikoport.com/columnstore/
and see which articles are 2012-focused and you can definitely skip them. As for the rest, the most 2014 cases are still pretty useful for SQL 2016.
Best regards,
Niko Neugebauer