With today’s announcement on the availability and support of the Columnstore indexes in the Preview version of Azure SQLDatabase, I am opening a new subseries in my Columnstore – Azure Columnstore.
If you are interested in the basics of Columnstore Indexes, please visit the principal page for the series.
Today, on the 11th of December 2014, Microsoft has published a new Preview of the Azure SQLDatabase with a version 13.0.12 and which included support for the Columnstore Technology previously developed and used in SQL Server 2012 & 2014.
 If you are running a previous version of the Azure SQLDatabase, than you will need to upgrade it to the newest one, or maybe even create a new Azure SQL Database.
If you are running a previous version of the Azure SQLDatabase, than you will need to upgrade it to the newest one, or maybe even create a new Azure SQL Database.
Another important issue is that in order to use Enterprise Features of SQL Server, you will need to have a Premium Edition of the Azure SQL Database, otherwise you will get a similar error message:
Msg 40514, Level 16, State 32, Line 39
‘COLUMNSTORE’ is not supported in this version of SQL Server.
After upgrading or creating a new Azure SQLDatabase that is compatible with V12, let’s check on what is available there at the moment:
– Nonclustered Columnstore Indexes
– Clustered Columnstore Indexes
– The Batch Mode
– Execution Plan Improvements
– Updated information in current DMV’s :)
– New DMV’s :)
Clustered Columnstore
I decided to run my simplest script on my database in order to verify that some of the basic features of the Clustered Columnstore Indexes are supported:
create table dbo.MaxDataTable(
c1 bigint,
c2 numeric (36,3),
c3 bit,
c4 smallint,
c5 decimal (18,3),
c6 smallmoney,
c7 int,
c8 tinyint,
c9 money,
c10 float(24),
c11 real,
c12 date,
c13 datetimeoffset,
c14 datetime2 (7),
c15 smalldatetime,
c16 datetime,
c17 time (7),
c18 char(100),
c19 varchar(100),
c20 nchar(100),
c21 nvarchar(100),
c22 binary(8),
c23 varbinary(8),
c24 uniqueidentifier,
);
-- Lets try out to create a new Clustered Columnstore Index:
Create Clustered Columnstore Index
CC_MaxDataTable on dbo.MaxDataTable;
-- Insert some data into it
insert into dbo.MaxDataTable
default values;
-- Select content of our table
select c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, c11, c12, c13, c14, c15, c16, c17, c18, c19, c20, c21, c22, c23, c24
from dbo.MaxDataTable;
-- Let us add one more column
alter table dbo.MaxDataTable
add c25 int NULL;
GO
-- Update our newest column
update dbo.MaxDataTable
set c25 = 23;
-- Can we actually modify new column's metadata ?
alter table dbo.MaxDataTable
alter column c25 int NOT NULL;
-- Drop it
alter table dbo.MaxDataTable
drop column c25;
It has been executed perfectly, like I would expect from a good SQL Server 2014 installation.
I suspect that the type support has not been modified yet from the on-premise version, and so I have decided to test it:
create table dbo.LobDataTable( c1 varchar(max) ); -- Lets try out to create a new Clustered Columnstore Index on this LOB table Create Clustered Columnstore Index CC_LobDataTable on dbo.LobDataTable;
The error message that I have received on Azure SQLDatabase is equal to the SQL Server 2014 version:
Msg 35343, Level 16, State 1, Line 7
The statement failed. Column ‘c1’ has a data type that cannot participate in a columnstore index. Omit column ‘c1’.
That did not stopped me, of course :), and so I have opened my script with a table that has all the unsupported data types for Clustered Columnstore Indexes,
and so I executed the script below multiple times, modifying the dbo.UnsupportedDatatypesTable, removing tested columns 1 after 1:
create table dbo.UnsupportedDatatypesTable( c1 text, c2 timestamp, c3 hierarchyid, c4 sql_variant, c5 xml, c6 varchar(max), c7 nvarchar(max), c8 geography, c9 geometry ); GO -- Lets create a Clustered Columnstore Index Create Clustered Columnstore Index CC_UnsupportedDatatypesTable on dbo.UnsupportedDatatypesTable; GO -- Drop this test table drop table dbo.UnsupportedDatatypesTable
After 9 executions I had finally confirmed that there were no changes in the data type support from SQL Server 2014 RTM + CU4 (12.0.2402) to today’s preview version of Azure SQLDatabase.
I thought that it was truly neat, but maybe creating a table with more than 8060 bytes would be allowed in this new version ?
create table dbo.UnsupportedDatatypesTable( c1 char(3000), c2 char(3000), c3 char(3000), ); GO
Not really, as the following message shows:
Msg 1701, Level 16, State 1, Line 7
Creating or altering table ‘UnsupportedDatatypesTable’ failed because the minimum row size would be 9007, including 7 bytes of internal overhead. This exceeds the maximum allowable table row size of 8060 bytes.
I have also tried to create a Clustered Columnstore Index on the table containing Sparse columns, but logically this did not worked out. :)
Nonclustered Columnstore
Having heard the announcement at the PASS Summit 2014, delivered by T.K. Rengarajan, that in the next version of SQL Server we shall receive updatable Nonclustered Columnstore Indexes over In-Memory OLTP, I thought that it would be a perfect opportunity to test out if Microsoft has managed to turn them updatable in all situations and so I executed the script to test the updatability of the Nonclustered Columnstore Indexes:
create table dbo.MaxDataTable_NC( c1 bigint, c2 numeric (36,3), c3 bit, c4 smallint, c5 decimal (18,3), c6 smallmoney, c7 int, c8 tinyint, c9 money, c10 float(24), c11 real, c12 date, c13 datetimeoffset, c14 datetime2 (7), c15 smalldatetime, c16 datetime, c17 time (7), c18 char(100), c19 varchar(100), c20 nchar(100), c21 nvarchar(100), c22 binary(8), c23 varbinary(8), c24 uniqueidentifier, ); -- Lets try out to create a new NonClustered Columnstore Index: Create NonClustered Columnstore Index CC_MaxDataTable_NC on dbo.MaxDataTable_NC (c1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15,c16,c17,c18,c19,c20,c21,c22,c23,c24) ; -- Insert some Null's by default into this table: insert into dbo.MaxDataTable_NC default values;
The error message that I have received was quite clear and direct:
Msg 35330, Level 15, State 1, Line 44
INSERT statement failed because data cannot be updated in a table that has a nonclustered columnstore index. Consider disabling the columnstore index before issuing the INSERT statement, and then rebuilding the columnstore index after INSERT has completed.
Oh well, that’s ok – but what about the Hekaton tables themselves – are they supported ? Maybe there is a new way and a new order of building things for InMemory OLTP:
CREATE TABLE dbo.Hekaton_CCI
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 1000000),
c2 NVARCHAR(50) NOT NULL,
c3 NVARCHAR(50) NOT NULL
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
The error message returned says that InMemory OLTP is not supported yet in the current (13.0.12) release:
Msg 534, Level 15, State 73, Line 8
‘MEMORY_OPTIMIZED=ON’ failed because it is not supported in the edition of this SQL Server instance ‘C082BEF6F57D’. See books online for more details on feature support in different SQL Server editions.
DMV’s
Since the current version has already major number increased (from 12 to 13), I thought that this step would accompany with some new & exciting stuff, especially from the point of view of DMVs, and so I checked on the available management views and functions to find 2 of particular interest:
sys.dm_db_column_store_row_group_operational_stats & sys.dm_db_column_store_row_group_physical_stats
They book seem to describe internal structures and functioning of the Columnstore Row Groups, so I decided to create some data and to see what I can find out:
I have decided to create a small test table and load a number of Row Groups into it:
-- Create Test Table create table dbo.BigDataTest( id int not null ); -- Create Columnstore Index create clustered columnstore index PK_BigDataTest on dbo.BigDatatest; -- Load 1 Full Segment into the Test Table declare @i as int; set @i = 1; begin tran while @i <= 1048576 begin insert into dbo.BigDataTest values (@i); set @i = @i + 1; end; commit; GO -- Load extra 7 Segments into the test table declare @i as int; declare @max as int; set @i = 1; while @i <= 3 begin select @max = isnull(max(id),0) from dbo.BigDataTest; insert into dbo.BigDataTest select id + @max from dbo.BigDataTest; checkpoint; set @i = @i + 1; end;
I played for some time and the result of the first Row Group insertion was stable around 93-94 seconds in limited experience.
The second batch process, that loads 7 times more the amounts of the information compared to the first batch, took 307 seconds on the first attempt and around 300 seconds on the secondary attempts.
For monitoring purposes I was using the following query to track the progress of my batch process:
-- Check on the Row Groups status SELECT rg.total_rows, cast(100.0*(total_rows)/1048576 as Decimal(6,3)) as PercentFull, cast(100-100.0*(total_rows - ISNULL(deleted_rows,0))/iif(total_rows = 0, 1, total_rows) as Decimal(6,3)) AS PercentDeleted, i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, rg.* FROM sys.indexes AS i INNEr JOIN sys.column_store_row_groups AS rg ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE object_name(i.object_id) = 'BigDataTest' ORDER BY object_name(i.object_id), i.name, row_group_id;
I was happily observing the first row groups loading until I noticed something strange:
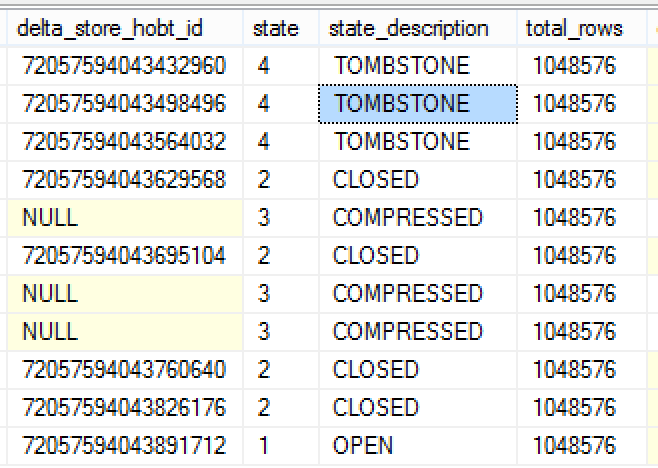 To my knowledge in SQL Server there is no status 4 for the Row Groups, nor the description Tombstone makes any sense for SQL Server 2014 architecture.
To my knowledge in SQL Server there is no status 4 for the Row Groups, nor the description Tombstone makes any sense for SQL Server 2014 architecture.
If I am loading 8 Row Groups in total, then why do I have those objects that have no direct definition of the size? I could not understand what was going on, besides being quite sure that we have a new type of the Row Group that has some new functionality.
At this point I decided to force the closure of the existing open Row Groups and invoke the manual Tuple Mover which would do the necessary stuff - I hoped:
-- Force closure of the Open Delta-Stores alter index PK_BigDataTest on dbo.BiGDataTest Reorganize with (COMPRESS_ALL_ROW_GROUPS = ON);
I re-invoked the query consulting the contents of the sys.column_store_row_groups DMV:
-- Check on the Row Groups status SELECT rg.total_rows, cast(100.0*(total_rows)/1048576 as Decimal(6,3)) as PercentFull, cast(100-100.0*(total_rows - ISNULL(deleted_rows,0))/iif(total_rows = 0, 1, total_rows) as Decimal(6,3)) AS PercentDeleted, i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, rg.* FROM sys.indexes AS i INNEr JOIN sys.column_store_row_groups AS rg ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE object_name(i.object_id) = 'BigDataTest' ORDER BY object_name(i.object_id), i.name, row_group_id;
and it pretty much brought no visible result at all: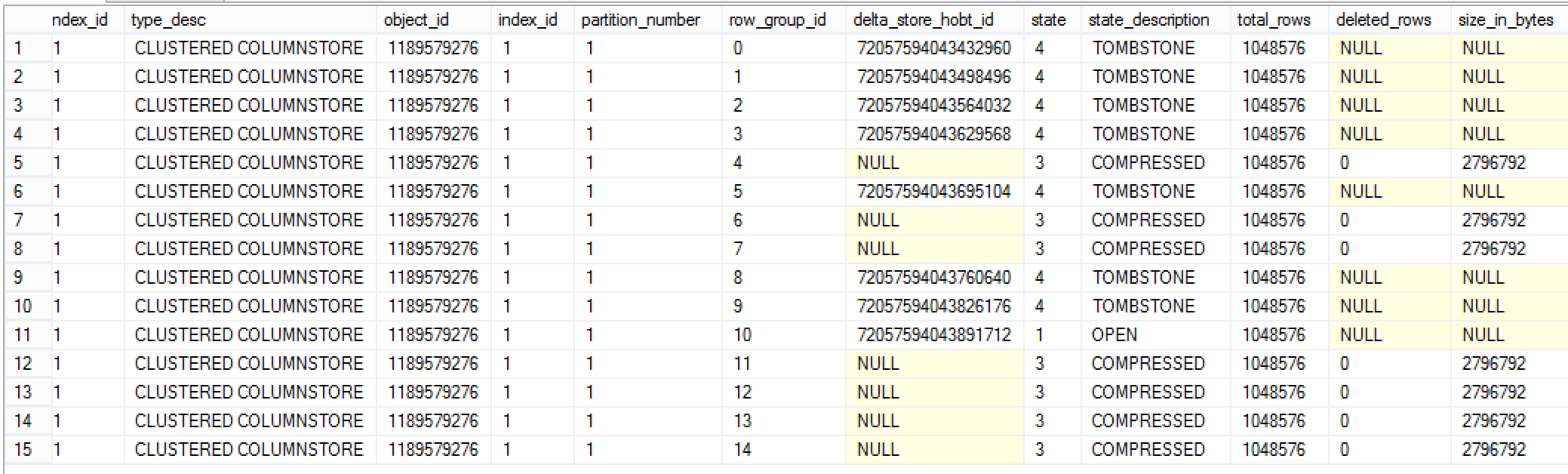
I simply could not believe my eyes - the Tombstone Row Groups were there and they were not moving anywhere.
I could clearly see that their number was similar to the number of the compressed Row Groups, and so I ran the following query to check the number of different statuses for the Row Groups available for my table BigDataTest:
-- Check Row Group situation
select state, state_description, count(*) as 'RowGroup Count'
from sys.column_store_row_groups
where object_id = object_id('BigDataTest')
group by state, state_description
order by state;
The first result was showing that the reorganise operation with a hint were simply invoked, but somewhere after 5 minutes (automated Tuple Mover??? or simply an alpha-feature) my results became different and I have lost the only open Delta-Store and had just 8 compressed Row Groups and 8 Tombstones in my Clustered Columnstore Index.
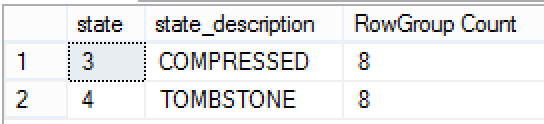
After some thoughts on the matter, I decided to search online for more information and to be sure enough in a matter of seconds I have found some information on Wikipedia on the Tombstone (aka Data Stone), and so Tombstone is a deleted record in a replica of a distributed data store, which makes me think that this structures will be used for some operations such as Merge of the different Row Groups or support of the Snapshot Isolation or maybe even having a distributed Columnstore inside an Availability Group (RAC InMemory type of thing). I mean those are all quite a speculations, with distributed Columnstore being by far the less possible thing.
Anyway, having the number of Tombstones being equal to the number of RowGroups is most probably done to percolate the space for any of such future operations.
I thought that it would be an interesting option to try to rebuild the table in order to see an effect on those Tombstone Row Groups and so I invoked the following statements:
alter index PK_BigDataTest on dbo.BiGDataTest
Rebuild;
select state, state_description, count(*) as 'RowGroup Count'
from sys.column_store_row_groups
where object_id = object_id('BiGDataTest')
group by state, state_description
order by state;
![]() And here we go - just 8 Compressed Row Groups were left without any Tombstones, which makes me believe at this point that Tombstone Row Groups are created and most probably are used by the Tuple Mover.
And here we go - just 8 Compressed Row Groups were left without any Tombstones, which makes me believe at this point that Tombstone Row Groups are created and most probably are used by the Tuple Mover.
I considered to run a test by deleting a couple of rows to see if a new Row Group would appear on the list:
-- Delete some 50 rows delete top (50) from dbo.BigDataTest;
After that I executed my query to see if there are any changes to the Columnstore structure:
SELECT rg.total_rows, deleted_rows, cast(100.0*(total_rows)/1048576 as Decimal(6,3)) as PercentFull, cast(100-100.0*(total_rows - ISNULL(deleted_rows,0))/iif(total_rows = 0, 1, total_rows) as Decimal(6,3)) AS PercentDeleted, i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, rg.* FROM sys.indexes AS i INNEr JOIN sys.column_store_row_groups AS rg ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE object_name(i.object_id) = 'BigDataTest' ORDER BY object_name(i.object_id), i.name, row_group_id;
 The observed result shown no modification in Columnstore Index structure, besides naturally 50 rows being marked as deleted in Deleted Bitmap.
The observed result shown no modification in Columnstore Index structure, besides naturally 50 rows being marked as deleted in Deleted Bitmap.
So I decided to see what happens if I add another Row Group to my test table:
-- Load 1 Full Row Group into the Test Table declare @i as int; set @i = 1; begin tran while @i <= 1048576 begin insert into dbo.BigDataTest values (@i); set @i = @i + 1; end; commit;
90 seconds later I had another Row Group added, which was an open Delta-Store - and in order to close it I simply added one more row to my table:
insert into dbo.BigDataTest
values (-1);
I executed a query for seeing the Row Groups:
SELECT rg.total_rows, deleted_rows, cast(100.0*(total_rows)/1048576 as Decimal(6,3)) as PercentFull, cast(100-100.0*(total_rows - ISNULL(deleted_rows,0))/iif(total_rows = 0, 1, total_rows) as Decimal(6,3)) AS PercentDeleted, i.object_id, object_name(i.object_id) AS TableName, state, state_description, i.name AS IndexName, i.index_id, i.type_desc, rg.* FROM sys.indexes AS i INNEr JOIN sys.column_store_row_groups AS rg ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE object_name(i.object_id) = 'BigDataTest' ORDER BY object_name(i.object_id), i.name, row_group_id;
 At this point I decided to wait and see if the Tombstone Row Group will reappear... Sure enough less than 5 minutes later after rerunning my query I saw Tombstone Row Group coming back to town, which means that right now those structures appear only after the trickle load has been executed and a Delta-Store changed it's status from the Open to Close.
At this point I decided to wait and see if the Tombstone Row Group will reappear... Sure enough less than 5 minutes later after rerunning my query I saw Tombstone Row Group coming back to town, which means that right now those structures appear only after the trickle load has been executed and a Delta-Store changed it's status from the Open to Close.

But how does Tombstone Row Group is being treated in the SQL Server Engine - is it something that is considered to be a Segment of a kind or something ? To solve any doubts, I executed a query against sys.column_store_segments DMV, to check if the information on the Tombstone Row Groups is appearing there
select object_name(p.object_id) as 'Table Name',
seg.column_id,
seg.segment_id,
seg.encoding_type,
seg.row_count,
seg.primary_dictionary_id,
seg.secondary_dictionary_id,
seg.min_data_id,
seg.max_data_id,
seg.on_disk_size
, cast( seg.on_disk_size / 1024. / 1024
as decimal(16,3)) as 'size in MB'
from sys.column_store_segments seg
inner join sys.partitions as p
ON seg.partition_id = p.partition_id
where object_id = object_id('dbo.BigDataTest')
order by column_id
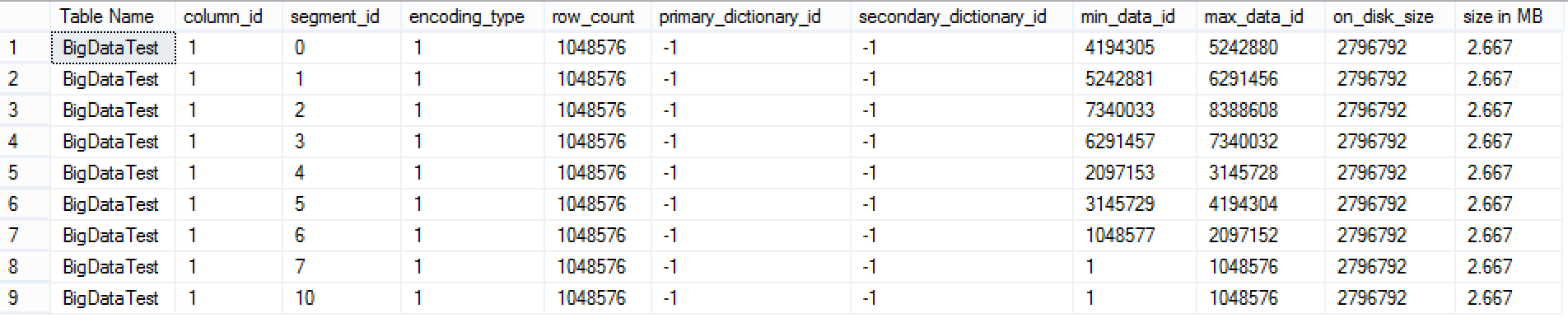 As you can see on the picture with results, there are no Row Groups with segment_id 8 & 9, and so the Tombstone is definitively not a compressed RowGroup (at least for the moment).
As you can see on the picture with results, there are no Row Groups with segment_id 8 & 9, and so the Tombstone is definitively not a compressed RowGroup (at least for the moment).
This is extremely interesting and it is definitely points to me that my Columnstore Queries library (expected to be published in the next 4-6 weeks) should be updated for the current Azure offering and for the future SQL Server versions.
New DMV sys.dm_db_column_store_row_group_operational_stats
As already mentioned above, I have found a new Dynamic management view - sys.dm_db_column_store_row_group_operational_stats. It looks like it should serve for the operational needs of those who are using queries that reading information from this view.
Detailed information on the locks & latches of different types are truly welcome, and being able to drill it down right to the concrete Row Group sounds like an amazing feature!
I hope that there will be a concrete way to reset this information, such as using one of the DBCC commands. :)
select object_id, index_id, partition_number, row_group_id, scan_count, row_group_lock_count, row_group_lock_wait_count, row_group_lock_wait_in_ms, page_lock_count, page_lock_wait_count, page_lock_wait_in_ms, row_lock_count, row_lock_wait_count, row_lock_wait_in_ms, page_latch_wait_count, page_latch_wait_in_ms, page_io_latch_wait_count, page_io_latch_wait_in_ms from sys.dm_db_column_store_row_group_operational_stats
Unfortunately at the moment none of my queries had provoked this view to show any kind of information and so I assume that it is very much under construction.
New DMV sys.dm_db_column_store_row_group_physical_stats
Judging by the name of this view, it will be providing detailed information on the physical state of the Columnstore Indexes.
The columns of this view are almost exact copy of the already existing DMV sys.column_store_row_groups with addition of the 2 new columns - trim_reason & trim_reason_description.
I can only speculate about the reasons for copying out information of a complete DMV, but anyway those 2 new columns should provide information on the trim operation.
Not being sure of what this trim might handle, I am interested in seeing more information before coming to any judgement.
select object_id, index_id, partition_number, row_group_id, delta_store_hobt_id, state, state_description, total_rows, deleted_rows, size_in_bytes, trim_reason, trim_reason_description from sys.dm_db_column_store_row_group_physical_stats;
Unfortunately there is no information that this DMV provides at the moment - were they actually published a little bit ahead of time because of the compatibility reasons ? :)
Anyway providing better information on the physical structure of the Columnstore Indexes will be more than welcome - there are enough areas such as Memory where these improvements should be applied.
Execution Plan Improvements & Batch Mode
One of the key things to succeed while using the Columnstore Indexes is to make them execute in the Batch Mode, and so I decided to see if Azure SQLDatabase has any minimal support for it.
I will dive into a lot of details of the execution plans in a future blog post, but for the moment - let's consider this query:
select count_big(m1.id + m2.id) from dbo.BigDataTest m1 cross join dbo.BigDataTest m2 where m2.id < 2000 and m1.id < 1000;
Consider the execution plan:

It looks perfectly normal to me. Now let us compare with an execution plan for the same table, generated on SQL Server 2014 CU4:

Some Interesting stuff:
- on Azure SQL Database both Columnstore Index scans are running in Batch Mode, while on SQL Server 2014 the m2 runs in row execution mode.
- Azure SQL Database apparently does not need Compute Scalar & Hash Match operations and notice that on SQL Server 2014 those iterators run in Batch Execution Mode
- Table Spool runs in Row Execution Mode
- Azure SQL Database does not show the Degree of Parallelism for the individual iterator, while showing the total (If you dig into XML there is only an overall information with no details on the individual threads)
- Parallelism iterators are not present on the Azure SQLDatabase, they just introduce more clutter into complex structures and so I am happy about it
I decided to take a more detailed look into the execution plan on Azure SQL Database, and here is one of the most interesting and exciting things that I have found in it, related to the Columnstore Index Scan:
Yes, we have the incredibly useful information on the number of Row Groups accessed and skipped !!!
If you take a look at the meta information of our Columnstore Index Row Groups, you will see that we have 11 different Row Groups, where 1 of them is a Delta-Store, 1 is a Tombstone and 9 are Compressed.
From here it is logical to understand that this information is provided only for the compressed Row Groups (others do not have the min & max values and so can't be skipped), and for the test query that I executed just 2 Compressed Row Groups were processed, while all other Compressed Row Groups were skipped.
No more Trace Flags, no more ExtendedEvents for catching out this information!
Amazing! Because this information is already contained in the execution plan, I have no doubt that one day they will be present in a graphical visualisation of execution plans.
Also, SQLSentry development team - are you reading this? ;)
Important observation - it looks that the information about SegmentReads & SegmentSkips appears only if we are executing Columnstore Index scan in the Batch Mode, because if our query runs in Row Execution Mode, than this information is not available at all - at this point this might be simply a development preview version.
Now, it would even more awesome to have an information about the number of Delta-Stores & Tombstones that were read and skipped. :)
Updated
Update on the 14th of December 2014:
The mystery of the Tombstone Row Groups was solved with the help of none the less than Sunil Agarwal (Principal Program Manager at Microsoft) who explained to me that the Tombstone Row Groups are actually the Delta-Stores that got compressed and needed to be removed by the Garbage Collector by the Tuple Mover.
This means that if you wait long enough for the automated Tuple Mover to kick in, it should remove those Tombstone Row Groups.
Final thought
I am very happy to see further developments of the Columnstore technology from Microsoft and I very excited to see the explanations on what I have found out in the first 24 hours after its release. :)
to be definitively continued ...
Does this mean that batch mode no longer requires parallelism? The last Azure query in this post (the loop join) ran in batch mode but was not parallel according to the picture.
Hi tobi,
that’s the thing I would love to find out, I am expecting this to happen at one point.
Regarding the Batch Mode, before going live with this blog post, I have decided to remove any speculation out of it – because at the moment the only thing that an execution plan on azure shows is just one RunTimeInformation element making it more difficult to determine how many cores are taking care in the process.
Also, unfortunately no other information regarding DOP is present at the execution plan.
I have tested queries with DOP=1 in order to see the results, and I have got the Batch Mode there, but since the execution times were similar I still can’t be sure that the Batch Mode runs in DOP = 1.
I will blog about it soon.
Best regards,
Niko
Niko: this is in response to your experiment on batch mode and parallelism. Azure columnstore supports BATCH mode with DOP=1 as well. Try the following
(1) look at property of the scan operator. like you found, that it shows BATCH. Also look at number of batches (if you see non-zero value, it is a further proof that the table was scanned in batches) and also number of execution (assume in your case, it shows 1 which implies single threaded execution).
(2) you can look at sys.dm_os_schedulers and see how many visible non-DAC schedulers you have. I guess you have only 1.
When you say that ‘execution’ times were similar, what were you comparing with?
thanks
Sunil Agarwal
SQL Server Team
Hi Sunil,
thank you for the comment!
(1) Thanks for the information – I have already blogged about my investigations of the execution plan in the 2nd blog post of the series! :)
(2) I have checked on the sys.dm_os_schedulers and naturally as you said only 1 scheduler (besides DAC) is available – but if I remember correctly Multi-Threaded Parallel Index Rebuilds were also supposed to be in the current preview of SQLDatabase – or am I confused?
Under similar execution times, I meant that running queries with MAXDOP = 1 or without results in comparable execution times.
Best regards,
Niko Neugebauer