Continuation from the previous 40 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
Note: This article is in’s 2nd version, after correcting comments done by Hugo Kornelis
Since I have started writing & doing presentations on Columnstore Indexes there have been a number of questions on the same topic – Statistics.
I have skipped some of the Columnstore Indexes basics since I have assumed that there were enough presentations and information on the internet on this topic, but since this question simply does not go away – I decided to include it into the series.
Segments elimination
A unit of read & write operation in Columnstore Indexes for SQL Server 2014 is a segment, with all the Pages & Extends that it includes, which means that no matter if we are reading 1 row or 1045678 rows, we shall need to read each 8K page that this Segments consists off.
To prove it, just run a simple query on any Clustered Columnstore Table, such as:
set statistics io on select top 1 * from dbo.FactOnlineSales
The number of reads will not correspond 1 or 2 or 3 Pages, but the whole Segment.
Note that according to the SIGMOD 2013 Columnstore WhitePaper this situation might change in the near future with lookup indexes being enabled (let us hope that it can happen already in the next SQL Server version)
How does Segment Elimination works ?
The Query Optimiser reads the meta information from the sys.column_store_segments, specifically consulting min_data_id and max_data_id columns and thus being able to take a decision if the Segment should be processed for the current query or not:
select column_id, segment_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.hobt_id = part.hobt_id
where OBJECT_ID = OBJECT_ID('FactOnlineSales');
For more information on Segment Elimination check out Clustered Columnstore Indexes – part 34 (“Deleted Segments Elimination”)
Statistics
Every SQL Server professional should know and understand the importance of the statistics, without which Query Optimiser would not be able to decide what is a good enough plan for a given query. Query Optimiser needs it in order to make an educated guess of how many rows a given query shall return – 1 row or 15 million rows, how much memory this query needs in order to execute requested functionalities, and so on
This is why for each of the columns in each and every table we have a statistics object, we also have statistics objects for the indexes whenever we create them.
Because for Columnstore Indexes a unit of any operation is a Segment and we already have minimum & maximum values we can decide if one particular Segment should be scanned or not.
There is no Columnstore Index Seek operation, because at the current version of the SQL Server (2014) does not support seek, whenever we touch Columnstore Index Segment we scan it completely for the searched information.
Let’s use a freshly restored copy of Contoso Retail DW database for the test, dropping all Primary & Foreign Keys and creating 1 Clustered Columnstore Indexes on our principal Fact Table:
USE [master] alter database ContosoRetailDW set SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE [ContosoRetailDW] FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1, MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf', MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf', NOUNLOAD, STATS = 5; alter database ContosoRetailDW set MULTI_USER; GO ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 120 GO use ContosoRetailDW; alter table dbo.[FactOnlineSales] DROP CONSTRAINT PK_FactOnlineSales_SalesKey alter table dbo.[FactStrategyPlan] DROP CONSTRAINT PK_FactStrategyPlan_StrategyPlanKey alter table dbo.[FactSales] DROP CONSTRAINT PK_FactSales_SalesKey alter table dbo.[FactInventory] DROP CONSTRAINT PK_FactInventory_InventoryKey alter table dbo.[FactSalesQuota] DROP CONSTRAINT PK_FactSalesQuota_SalesQuotaKey alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCurrency alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCustomer alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimDate alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimProduct alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimPromotion alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimStore alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimAccount alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimCurrency alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimDate alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimEntity alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimProductCategory alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimScenario alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimChannel alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimCurrency alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimDate alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimProduct alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimPromotion alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimStore alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimCurrency alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimDate alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimProduct alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimStore alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimChannel alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimCurrency alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimDate alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimProduct alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimScenario alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimStore; GO Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales;
 If you open our FactOnlineSales table you will see a number of statistics objects already created previously. Note that we have a freshly created PK_FactOnlineSales statistics object, which was created for the Clustered Columnstore Index. Let’s check what is stored inside of this statistics object:
If you open our FactOnlineSales table you will see a number of statistics objects already created previously. Note that we have a freshly created PK_FactOnlineSales statistics object, which was created for the Clustered Columnstore Index. Let’s check what is stored inside of this statistics object:
dbcc show_statistics( 'dbo.FactOnlineSales', [PK_FactOnlineSales]);
Empty.
Because there is no support for the statistics for the Columnstore Indexes objects.
Running any tests agains this table would be quite a provocative option, because we have a number of statistics objects that might provide some information to Query Optimiser, and so let’s simply create a copy of this table, which shall contain no other statistics, beside the empty one from the Clustered Columnstore Index:
For the tests purposes, I shall disable database options “Auto Create” & “Auto Update” Statistics:
ALTER DATABASE [ContosoRetailDW] SET AUTO_CREATE_STATISTICS OFF GO ALTER DATABASE [ContosoRetailDW] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT GO
Now off to create table with a copy of the original data and without any of the statistics objects:
CREATE TABLE [dbo].[FactOnlineSalesNoStats](
[OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL,
[DateKey] [datetime] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [int] NULL,
[SalesQuantity] [int] NOT NULL,
[SalesAmount] [money] NOT NULL,
[ReturnQuantity] [int] NOT NULL,
[ReturnAmount] [money] NULL,
[DiscountQuantity] [int] NULL,
[DiscountAmount] [money] NULL,
[TotalCost] [money] NOT NULL,
[UnitCost] [money] NULL,
[UnitPrice] [money] NULL,
[ETLLoadID] [int] NULL,
[LoadDate] [datetime] NULL,
[UpdateDate] [datetime] NULL
);
Create Clustered Columnstore Index PK_FactOnlineSalesNoStats on dbo.FactOnlineSalesNoStats;
GO
set identity_insert dbo.FactOnlineSalesNoStats ON
insert into dbo.FactOnlineSalesNoStats
(OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate)
SELECT [OnlineSalesKey]
,[DateKey]
,[StoreKey]
,[ProductKey]
,[PromotionKey]
,[CurrencyKey]
,[CustomerKey]
,[SalesOrderNumber]
,[SalesOrderLineNumber]
,[SalesQuantity]
,[SalesAmount]
,[ReturnQuantity]
,[ReturnAmount]
,[DiscountQuantity]
,[DiscountAmount]
,[TotalCost]
,[UnitCost]
,[UnitPrice]
,[ETLLoadID]
,[LoadDate]
,[UpdateDate]
FROM [ContosoRetailDW].[dbo].[FactOnlineSales]
set identity_insert dbo.FactOnlineSalesNoStats OFF
Let’s check if there are any statistics created for the columns of the FactOnlineSalesNoStats table:
SELECT *
FROM sys.stats
WHERE object_id = OBJECT_ID('dbo.FactOnlineSalesNoStats');
![]()
Cool, just one empty statistics object, as expected. :)
Let us run a simple query on the created table:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats]
The result itself is not interesting for this investigation, but the actual execution plan and the estimations are the things that I am looking for:
![]() Our execution plan consists from a number of iterators, with Columnstore Index Scan being the most important and interesting one, so let us check its properties:
Our execution plan consists from a number of iterators, with Columnstore Index Scan being the most important and interesting one, so let us check its properties:
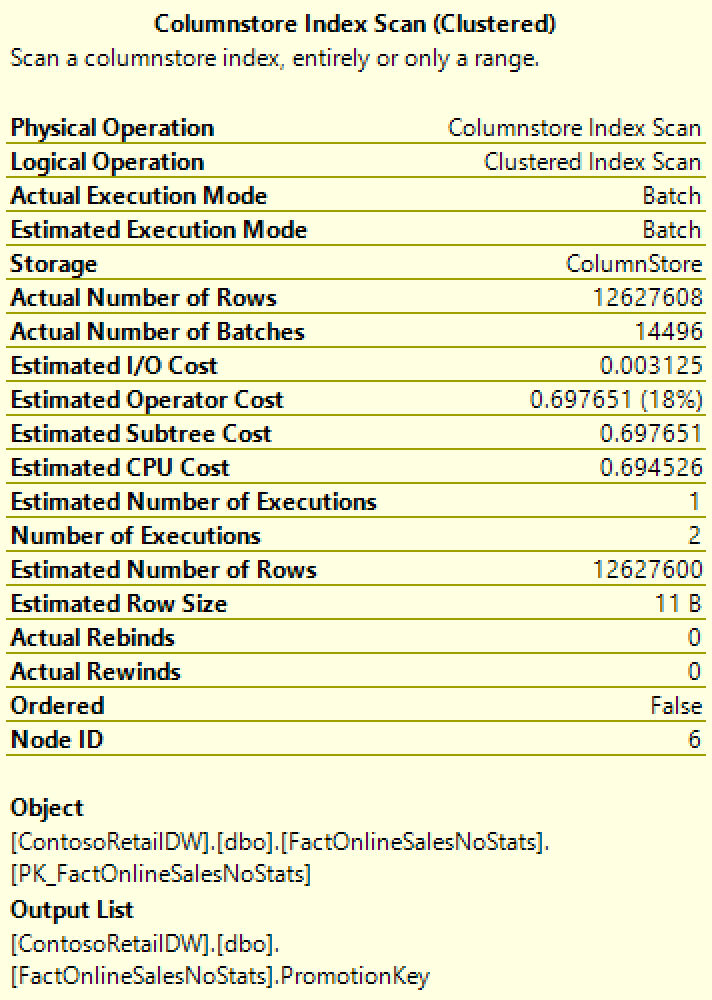 We have processed 12.627.608 Rows while scanning the table, but somehow and somewhere we have managed to estimate that the total size of the table shall be 12.627.600 rows, having a difference of just 8 rows with the actual number.
We have processed 12.627.608 Rows while scanning the table, but somehow and somewhere we have managed to estimate that the total size of the table shall be 12.627.600 rows, having a difference of just 8 rows with the actual number.
I am aint not a Query Optimiser, but if I would guess one possible way of how it does it estimation, I would advance with the idea of checking the average number of rows per Segment and multiply it by the number of segments, to see what number I will receive:
select sum( total_rows ) as TotalRows
, avg( total_rows ) * count(distinct seg.row_group_id) as EstimatedRowsNumber
, count(distinct seg.row_group_id) as Segments
from sys.column_store_row_groups seg
where OBJECT_ID = OBJECT_ID('FactOnlineSalesNoStats')
![]() Notice, that I have got pretty good close number, even though I am convinced that in the reality the formula for the calculation should be extremely complex with a some important inclusions of Delta-Stores and Deleted Bitmaps.
Notice, that I have got pretty good close number, even though I am convinced that in the reality the formula for the calculation should be extremely complex with a some important inclusions of Delta-Stores and Deleted Bitmaps.
I am just playing some basic stuff here :)
Cardinality Estimator
In SQL Server 2014 we have received a new Cardinality Estimator and if you check the restore DB script you will notice that I have updated the compatibility mode to 120, automatically enabling the new Cardinality Estimator for my Database.
Now let’s run some queries with different predicates:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where OnlineSalesKey = 32188091
The resulting execution plan is almost exactly the same, the major difference here is that the predicate is getting pushed down to the Columnstore Index Scan. The interesting part here is the number of rows that the Cardinality Estimator is expecting to get – 3353.53.
Let’s try a completely ridiculous number that I am sure does not belong to FactOnlineSales, since I verified it, and the result of the following query shall be NULL:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where OnlineSalesKey = 999999999
This time we have got the very same estimated number of 3353.53
Hmm, maybe this has something to do with this particular column, let’s try to use a different column as a predicate:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where StoreKey = 307
Still the same situation, still the same number 3353.53 even though this time we have really got a lot of data to process – 4.134.535 rows actually.
And what if I go and select a datetime column?
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where DateKey = '2007-05-08'
No changes, it is all about the same “magic” number of 3353.53 estimated rows whenever I ran a query on this table with a single predicate.
If I try to run a query with multiple predicates on the same column (2 for example) this number begins to rise:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where StoreKey = 307 or StoreKey = 308
This query gives me 5329.93 rows as estimation, the very same number should I run 2 predicates on the OnlineSalesKey column. If we go for 3 predicates the number rises to 6218.03 rows.
A more complex scenario with 2 different predicates on 2 different columns:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where StoreKey = 305 or OnlineSalesKey = 32188091;
This time we get a different execution plan:
 This time we get predicate scan goes out of the Columnstore Index into Filter iterator and as a bonus we even get a warning. (I am really wondering right now why do we Compute Scalar on the rows that will get filtered out later)
This time we get predicate scan goes out of the Columnstore Index into Filter iterator and as a bonus we even get a warning. (I am really wondering right now why do we Compute Scalar on the rows that will get filtered out later)
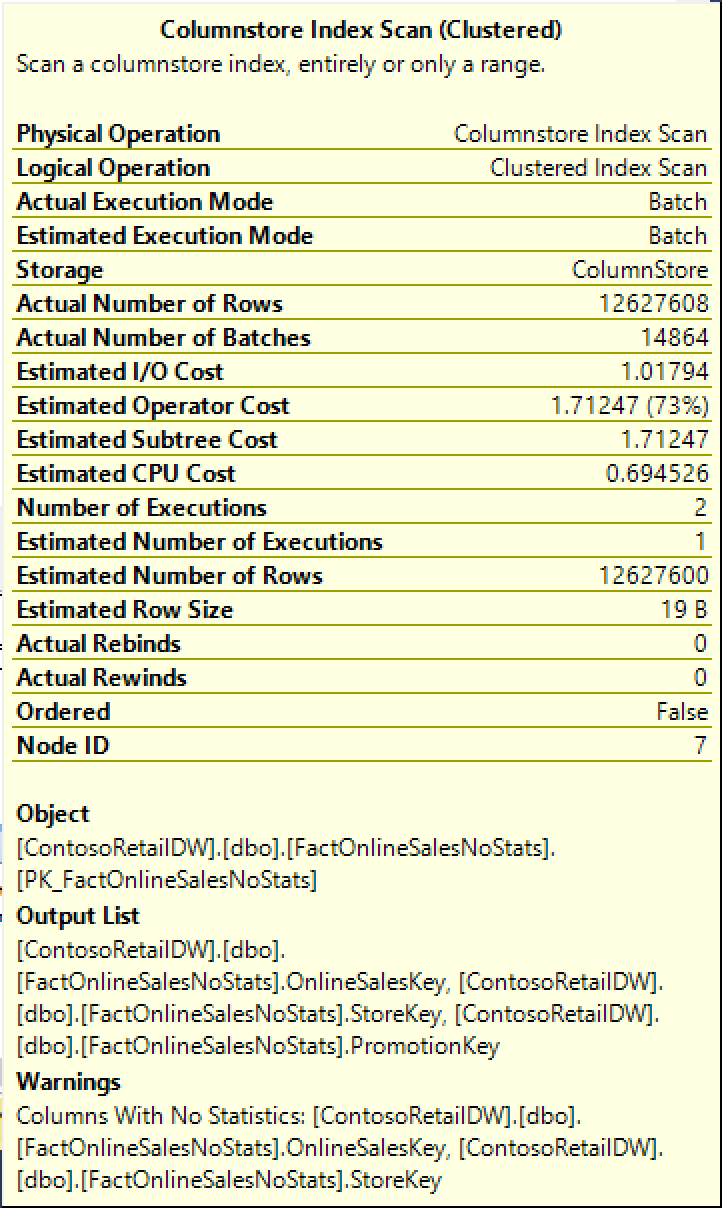 So this time it looks that the estimation is back to the 12.627.600 rows, as all involved Columnstore Index Segments were scanned.
So this time it looks that the estimation is back to the 12.627.600 rows, as all involved Columnstore Index Segments were scanned.
The warning that you can see on the screen, that mentions the lack of the statistics is the very same one you will get even if you are working on a table with Columnstore Index with a statistics on the necessary columns, here is an example script for the Original FactOnlineSales column:
CREATE STATISTICS [Stat_FactOnlineSales_StoreKey] ON [dbo].[FactOnlineSales]([StoreKey]) GO select avg([PromotionKey]*1.) from [dbo].[FactOnlineSales] where StoreKey = 305 or OnlineSalesKey = 32188091;
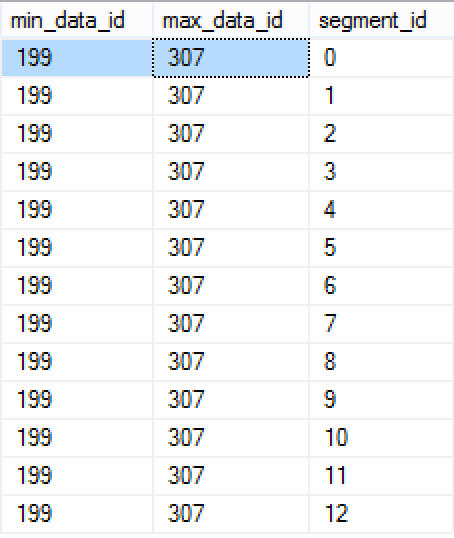
Query optimiser acted very correctly in this case because the actual information distributed between the Segments of the column 3 (StoreKey) is equal for each Segment and goes from 199 to 307:
select min_data_id, max_data_id, segment_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.hobt_id = part.hobt_id
where OBJECT_ID = OBJECT_ID('FactOnlineSalesNoStats')
and column_id = 3
Old Cardinality Estimator
Let’s try to run the same queries with an old Cardinality Estimator:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where OnlineSalesKey = 32188091 OPTION (QUERYTRACEON 9481);
 The plan is different, since it works in SQL Server 2012 compatibility mode for Nonclustered Columnstore Indexes, but the estimations are extremely correct – we have got just 1 row here. Running the OnlineSalesKey = 999999999 gets the same estimation, just 1 row.
The plan is different, since it works in SQL Server 2012 compatibility mode for Nonclustered Columnstore Indexes, but the estimations are extremely correct – we have got just 1 row here. Running the OnlineSalesKey = 999999999 gets the same estimation, just 1 row.
Lets advance to a different column:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where StoreKey = 307 OPTION (QUERYTRACEON 9481);
This time the estimation for the Columnstore Index Scan was 211.832 Rows, which is definitely closer to the actual number of rows, but does it really bring any difference ?(The number of pages that are being processed is the same, it is all based on the number of Segments that expected to contain the searched values.)
It does. Let’s execute the following script which compares 2 execution plans, 1 on the table with statistics and the other one without:
select avg([PromotionKey]*1.) from [dbo].[FactOnlineSales] where StoreKey = 307; select avg([PromotionKey]*1.) from [dbo].[FactOnlineSalesNoStats] where StoreKey = 307;
Here are the results:


The difference is easy to understand and to spot: the aggregation are quite different (3rd operator from right) – Hash Match vs Stream Aggregate.
As a result the first query runs just 22 ms vs 589 ms for the second one.
In bigger and more complex plans the difference might go even bigger.
Here is more info from the SQLSentry Plan Explorer on the difference between those 2 queries:
![]()
Final Thoughts
– The statistics are still the key element in order to get a good execution plan.
– There is only 1 type of the data access iterator for Columnstore Indexes – Scan, so no matter how many rows are expected we are scanning corresponding Segments, with all their Pages & Extents
For the current 2 releases – SQL Server 2012 and SQL Server 2014, for Columnstore Indexes – statistics do not affect the data access operations.
It should make the difference in the future for the Columnstore Lookup Indexes as I mentioned before. :)
to be continued with Clustered Columnstore Indexes – part 42 (“Materialisation”)
Hi Niko,
Your article starts with the statement that columnstore indexes don’t use statistics because they don’t need them. But later in the article you prove this statement wrong. For instance in the query with a filter on the StoreKey column, where the actual number of rows is over 1000 times more than the estimate. With statistics, a better estimate would have been made, as you will see when you run the same query on the original FactOnlineSales table.
This will not impact the scan of the columnstore index itself, but it may have a major impact on the rest of the plan if this is just a part of a more complicated query. For instance, a sort, hash match aggregate, or hash match join may have an insufficient memory grant, causing expensive spills to tempdb.
(Luckily, SQL Server *does* actually create and use statistics, even for columnstore indexes, as I accidentally found out when I tried to reproduce your scripts but had forgotten to run the script that explicitly disables statistics creation – after running a few queries, I had several automamtically created statistics, and I got fairly accurate estimates in my plans).
(Also, the warning you got in one of your plans hints about exactly that – it warns you about two columns with no statistics, which the optimizer does not like).
Hi Hugo,
thank you for the comment :)
After experimenting further I agree with you,
I focused on the Columnstore Index Scan and really did not looked with attention at what other iterators might get affected. Even some simple plans differ on the aggregate operations when having statistics.
That’s it, no more articles writing at 2:30 AM on the vacations. :)
This article has been updated.
Hi Niko,
I have observed that UPDATE STATISTICS on a CLUSTERED COLUMNSTORE seems to run as MAXDOP 1 whereas on a row store table it goes parallel. Is this something you have experienced?
Thanks