 One of my all-time favorite phrases is that “there are 3 kind of lies: lies, damned & statistics”. So let us talk about the statistics in SQL Server :)
One of my all-time favorite phrases is that “there are 3 kind of lies: lies, damned & statistics”. So let us talk about the statistics in SQL Server :)
The presence of statistics is the essential element of the decision for the Query Optimizer ( as long as we are not talking about Columnstore Indexes, which is a very different Story).
The process of statistics update is what might start any DBA talking for hours, especially if they had ever dealt with such platforms as SAP. (Hint: Number of tables and their size is the problem … )
In the upcoming SQL Server 2014 (I am writing this article at the time when we still have CTP2), Microsoft will be giving us a new feature – Incremental Statistics. This feature will allow us to create and update statistics on the partition level with much better frequency.
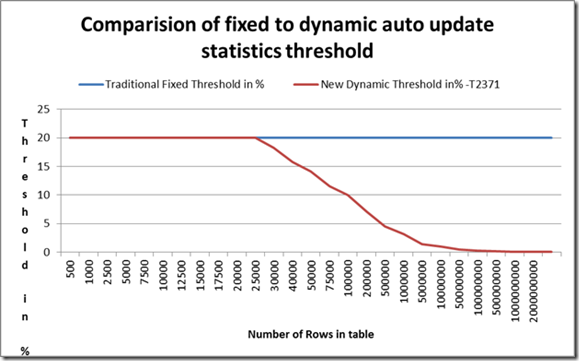 Traditionally we could have an automated statistics update when we reach a 20% threshold of the table in question, which is still a pain in the neck for some cases, such as Filtered Statistics, for example.
Traditionally we could have an automated statistics update when we reach a 20% threshold of the table in question, which is still a pain in the neck for some cases, such as Filtered Statistics, for example.
In Service Pack 1 for SQL Server 2008 R2, Microsoft has introduced a trace flag 2371 which enabled a different threshold for automated statistics update for the tables with large number of rows.
For a good number of cases this trace flag was a very nice improvement, but that was never enough.
For very big tables with billions of rows there is still a need to update statistic regularly especially in the cases when we are loading new data into our table. Should loaded data be under the current threshold, then we won’t get any statistics update and it would mean that the queries running on that partition would be using potentially wrong statistics.
And should we hit the threshold, then for updating the statistics, we need to sample whole table, which might take long time. Very long time.
Enter Incremental Statistics in SQL Server 2014! The target of the incremental statistics in SQL Server 2014 is to enable a very fast update of very large partitioned tables, as well as enabling auto-update with higher frequency.
The implementation idea is to have one statistics object for each partition, with binary merge of per-partition statistics to form the global statistics when necessary, while persisting on the disk the complete tree of statistics objects.
Any update for a partition will mean just merging the newly created object with the rest of the statistics tree.
This feature is definitely targeting partitioned tables, since it will allow a very fast update of a part of a table.
The syntax for this operation very similar to creation of a traditional statistics:
CREATE STATISTICS STAT_NAME ON TABLE_NAME (colA, colB)
with INCREMENTAL=ON
For an update operation on statistics object, we can invoke it on the partition level, with the sample below resampling the first and the fourth partitions:
UPDATE STATISTICS TABLE_NAME (STAT_NAME)
with RESAMPLE ON PARTITIONS(1, 4)
We can also disable or enable incremental object creation for the existing statistics, by using the following command:
UPDATE STATISTICS TABLE_NAME (STAT_NAME)
with INCREMENTAL= { ON | OFF }
And for the case when we want the auto created statistics to be incremental, we can use the following command:
ALTER DATABASE dbName
SET AUTO_CREATE_STATISTICS ON
(INCREMENTAL=ON)
Notice, that for database operation the (INCREMENTAL = ON) is being used, while for incremental statistics creation with INCREMENTAL=ON is being used. I hope Microsoft will get to correct this to be identical before the final release.
So for the performance test, I will be using my old code for ContosoRetailDW database, which is creating a couple of partitions:
-- Add 4 new filegroups to our database
alter database ContosoRetailDW
add filegroup OldColumnstoreData;
GO
alter database ContosoRetailDW
add filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add filegroup Columnstore2009;
GO
-- Add 1 datafile to each of the respective filegroups
alter database ContosoRetailDW
add file
(
NAME = 'old_data',
FILENAME = 'C:\Data\MSSQL\DATA\old_data.ndf',
SIZE = 10MB,
FILEGROWTH = 125MB
) to Filegroup [OldColumnstoreData];
GO
alter database ContosoRetailDW
add file
(
NAME = '2007_data',
FILENAME = 'C:\Data\MSSQL\DATA\2007_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add file
(
NAME = '2008_data',
FILENAME = 'C:\Data\MSSQL\DATA\2008_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) to Filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add file
(
NAME = '2009_data',
FILENAME = 'C:\Data\MSSQL\DATA\2009_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2009;
GO
-- Create the Partitioning scheme
create partition function pfOnlineSalesDate (datetime)
AS RANGE RIGHT FOR VALUES ('2007-01-01', '2008-01-01', '2009-01-01');
-- Define the partitioning function for it, which will be mapping data to each of the corresponding filegroups
create partition scheme ColumstorePartitioning
AS PARTITION pfOnlineSalesDate
TO ( OldColumnstoreData, Columnstore2007, Columnstore2008, Columnstore2009 );
-- Now let us create a Clustered Index on our table:
Create Clustered Index PK_FactOnlineSales
on dbo.FactOnlineSales (DateKey)
with (DATA_COMPRESSION = PAGE)
ON ColumstorePartitioning (DateKey);
With a partitioning being ready, now it is the time for some tests: first of all, let us see the creation of the statistics objects, I have executed the following code 5 times:
USE [ContosoRetailDW] GO dbcc freeproccache; set statistics time on set statistics io on CREATE STATISTICS [PtdFactOnlineSales] ON [dbo].[FactOnlineSales]([DateKey]) GO set statistics time off set statistics io off drop statistics [dbo].[FactOnlineSales].[PtdFactOnlineSales];
My results were varying between 390 ms & 422 ms for CPU time and between 404 ms & 450 ms for the elapsed time.
I then decided to execute a couple of times the creation of the Incremental statistics, using the following script:
USE [ContosoRetailDW] GO dbcc freeproccache; set statistics time on set statistics io on CREATE STATISTICS [PtdFactOnlineSalesIncremental] ON [dbo].[FactOnlineSales](DateKey) WITH INCREMENTAL = ON GO set statistics time off set statistics io off drop statistics [dbo].[FactOnlineSales].[PtdFactOnlineSalesIncremental];
This time the execution times varied from 407ms to 422ms for CPU time, and between 437 ms and 489 ms for the elapsed time, which is slightly slower then the creation of the non-incremental statistics.
I decide to consult sys.stats DMV for the information about created statistics objects:
select *
from sys.stats
where object_id = object_id('dbo.FactOnlineSales')
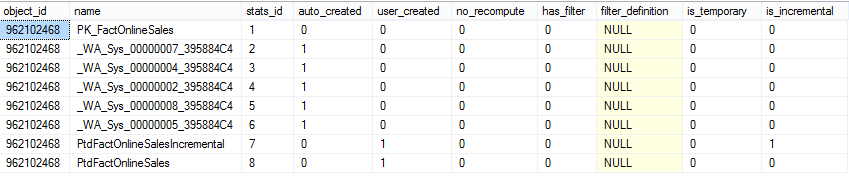
Given results has shown that my PtdFactOnlineSalesIncremental statistics were the only one created as Incremental.
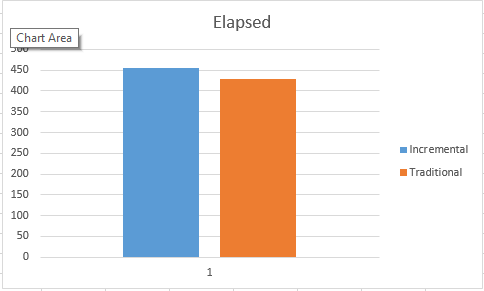
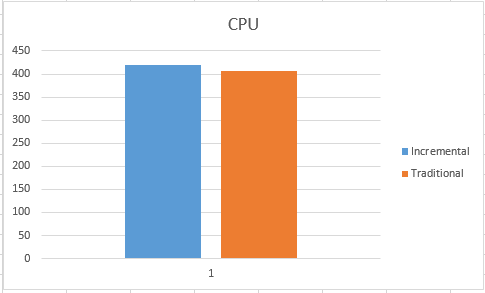 Here are the images of the average times, they show clearly that Incremental statistics are to take a little bit more time than the traditional ones. This is an expected result, since we are creating more objects internally.
Here are the images of the average times, they show clearly that Incremental statistics are to take a little bit more time than the traditional ones. This is an expected result, since we are creating more objects internally.
I know that these tests are quite basic, but all other tests I have done so far – have given quite a similar picture.
to be continued … SQL Server Incremental Statistics part 2
Hi Niko
Just a note on the apparent confusion about the difference in syntax between:
UPDATE STATISTICS TABLE_NAME (STAT_NAME)
WITH INCREMENTAL= { ON | OFF }
And:
ALTER DATABASE dbName
SET AUTO_CREATE_STATISTICS ON
(INCREMENTAL=ON)
The former is a DDL command like “ALTER Index” is, whereas the latter command is a Database SET option.
Set Options so far do not use the “with-clause” – just like those other examples of SET options:
ALTER DATABASE AdventureWorks2012
SET FILESTREAM
( NON_TRANSACTED_ACCESS = OFF )
ALTER DATABASE AdventureWorks2012
SET CHANGE_TRACKING = ON
(AUTO_CLEANUP = ON, CHANGE_RETENTION = 2 DAYS);
So you can be sure this will remain that way, and hopefully feel better, because there actually is a (deeper) reason behind it. – Whether SET commands could have been “designed” differently altogether in the first place, that is yet a different discussion :-)
Andreas
Good point! :) Very well noted, Andreas! :)