Continuation from the previous 23 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is a direct continuation from the previous post on Data Loading into Clustered Columnstore by using different schemes.
We have seen quite clear results for those small datasets (3 million rows) on how it looks the best to load the data into tables with Clustered Columnstore Indexes, but have we really? :) This post is intended to take a better look into the results generated.
There are different ways & angles of result judging – and let us try to cover a couple of them. First things first – let us check the number of Row Groups generated and the total size of our tables. Note that we are skipping the original table with 12 Million rows in our query and that we are getting the real final size of those tables, since they have all of their Row Groups compressed.
select OBJECT_NAME(rg.object_id) as TableName, count(*) as RowGroupsCount, cast(sum(size_in_bytes) / 1024.0 / 1024 as Decimal(9,2)) as SizeInMb
from sys.column_store_row_groups rg
where object_id != object_id('FactOnlineSales')
group by OBJECT_NAME(rg.object_id)

What can we see – first of all that the only method which has produced a different number of segments was where we were Loading Data into a HEAP using a Bulk functionality. Let us check out more details:
select *
from sys.column_store_row_groups rg
where rg.object_id = object_id('FactOnlineSales_Bulk_HEAP')
order by rg.partition_number, rg.row_group_id;

Here I can see that actually this method has produced a Row Group with just 2048 rows. This is quite unfortunate to say at least, but I guess we shall need to test with much more data to see if this is a one time artifact or this happen regularly for every couple of Row Groups. My guess is that it might happened for the last couple of Row Groups and if you are loading and so lets say for a 100 Groups than it should be a minor problem.
But lets get back to our compressed tables and pay more attention to the compressed table and their sizes.
From the first look they all look quite about the same, but lets check on some of those details – The worst result is definitely by the Bulk Load into a HEAP, and it is logical since we are looking at the table with an extra Row Group. Than we actually see 2 similar groups of similar results – Clustered Columnstore loads (33.77 MB) and loads into HEAP (~33.89), which gives an idea that used algorithms should produce similar results. Of course this needs to be proved by a very serious testing, but for exercise it is interesting enough to notice.
The difference in produced sizes for compressed Row Groups represent around 4% in the favor of the faster methods – by using tables with Clustered Columnstore Indexes by default.
But there is at least one more important aspect that we need to be aware about – the Dictionaries. Lets check on them:
SELECT OBJECT_NAME(i.object_id) as TableName, SUM(csd.on_disk_size)/(1024.0*1024.0) on_disk_size_MB
FROM sys.indexes AS i
JOIN sys.partitions AS p
ON i.object_id = p.object_id
JOIN sys.column_store_dictionaries AS csd
ON csd.hobt_id = p.hobt_id
where i.object_id != object_id('FactOnlineSales')
AND i.type_desc = 'CLUSTERED COLUMNSTORE'
group by OBJECT_NAME(i.object_id);
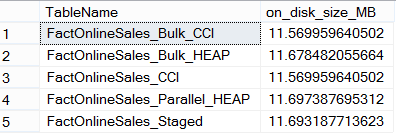
Its not easy to analyze this information in a table, but I can spare just simply say that the Dictionaries for data loaded directly into tables with Clustered Columnstore Indexes occupy less space, but lets not stop there and actually see the number of different dictionaries produced:
SELECT OBJECT_NAME(i.object_id) as TableName, count(csd.column_id) as DictionariesCount,
cast( SUM(csd.on_disk_size)/(1024.0*1024.0) as Decimal(9,2)) as on_disk_size_MB
FROM sys.indexes AS i
JOIN sys.partitions AS p
ON i.object_id = p.object_id
JOIN sys.column_store_dictionaries AS csd
ON csd.hobt_id = p.hobt_id
where i.object_id != object_id('FactOnlineSales')
AND i.type_desc = 'CLUSTERED COLUMNSTORE'
group by OBJECT_NAME(i.object_id);
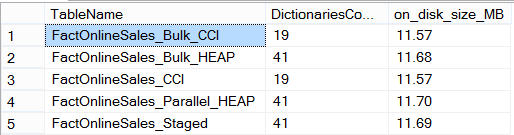
Now that’s a more sound information – we actually see that our data loading processes into tables with already existing Clustered Columnstore Indexes have produced much less dictionaries. This gives me an idea about check on the types of the dictionaries, and so I shall run the following query which will return to me the sizes of the Global Dictionaries, which as you should know are probably the most important ones, since they can be applied to every single Row Group potentially – meaning that we can benefit with even better compression in the future:
SELECT OBJECT_NAME(i.object_id) as TableName, count(csd.column_id) as DictionariesCount,
cast( SUM(csd.on_disk_size)/(1024.0*1024.0) as Decimal(9,2)) as on_disk_size_MB
FROM sys.indexes AS i
JOIN sys.partitions AS p
ON i.object_id = p.object_id
JOIN sys.column_store_dictionaries AS csd
ON csd.hobt_id = p.hobt_id
where i.object_id != object_id('FactOnlineSales')
AND i.type_desc = 'CLUSTERED COLUMNSTORE'
AND csd.dictionary_id = 0
group by OBJECT_NAME(i.object_id);
Here are our results:

Here we go – there are no Global Dictionaries for the tables with Clustered Columnstore Indexes. Don’t forget that once Global Dictionaries have been created, there are no chances to add any more values to them – they will be staying closed for any further intervention until we shall decide rebuilding our respective partition or table.
Data Loading for tables with Clustered Columnstore was fast, but the potential results in the future might be less encouraging, should compression be the paramount of your DataWareHouse. Theoretically. :) Lets test it ;)
Now we shall simply go and do an incremental load of 9 million rows into each of those tables, by using a traditional method of copying data:
insert into dbo.FactOnlineSales_Staged
select top 6000000
OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
from dbo.FactOnlineSales;
insert into dbo.FactOnlineSales_CCI
select top 6000000
OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
from dbo.FactOnlineSales;
insert into dbo.FactOnlineSales_Bulk_CCI
select top 6000000
OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
from dbo.FactOnlineSales;
insert into dbo.FactOnlineSales_Bulk_HEAP
select top 6000000
OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
from dbo.FactOnlineSales;
-- We shall need to update identity insert on the next table:
set identity_insert dbo.FactOnlineSales_Parallel_HEAP on
insert into dbo.FactOnlineSales_Parallel_HEAP
(OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate)
select top 6000000
OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
from dbo.FactOnlineSales;
The following timings were observed: 39 seconds 39 seconds, 36 seconds, 34 seconds, 37 seconds. It is interesting that we are actually seeing that data loading into Bulk Heap is being the fastest at this point.
What about the sizes of those tables and the respective number of the Row Groups:
select OBJECT_NAME(rg.object_id) as TableName, count(*) as RowGroupsCount, cast(sum(size_in_bytes) / 1024.0 / 1024 as Decimal(9,2)) as SizeInMb
from sys.column_store_row_groups rg
where object_id != object_id('FactOnlineSales')
group by OBJECT_NAME(rg.object_id)
Let’s say that I was at least surprised with the results:
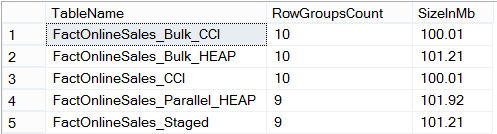
This is a very clear sign that even though in the last couple of cases data loading was faster plus the number of the Row Groups involved is smaller – which justifies this difference – the real size of the table was not affected as I would have expected.
We are still dealing with smaller tables for data loading into Clustered Columnstore Indexes, and even though this a very small test for a very small subset of data – I think that at least this test is demonstrative of possibility where having Clustred Columnstore Indexes by default might be a very good option from a lot of perspectives.
Oh and by the way – the Global Dictionaries stayed unaffected, as suspected:
SELECT OBJECT_NAME(i.object_id) as TableName, count(csd.column_id) as DictionariesCount,
cast( SUM(csd.on_disk_size)/(1024.0*1024.0) as Decimal(9,2)) as on_disk_size_MB
FROM sys.indexes AS i
JOIN sys.partitions AS p
ON i.object_id = p.object_id
JOIN sys.column_store_dictionaries AS csd
ON csd.hobt_id = p.hobt_id
where i.object_id != object_id('FactOnlineSales')
AND i.type_desc = 'CLUSTERED COLUMNSTORE'
AND csd.dictionary_id = 0
group by OBJECT_NAME(i.object_id);

to be continued with Clustered Columnstore Indexes – part 25 (“Faster Smaller Better Stronger”)
I guess the final size also depends on the data. In the HEAP cases global dictionaries can be created that are the most efficient. Probably, not every data set needs them (this one seems not to). Especially, if the dict size is a small fraction of the total CI size, this does not matter (as I understand it).
Very useful blog series. This is saving me a ton of investigative work :) A fun read as well.
Hi Tobi, you are absolutely right that it all depends on the quality and the type of the data.
Thank you for your kind words – I try my best to make something useful for the others.