Continuation from the previous 10 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is all about the the difference in the compression algorithms between Clustered Columnstore and Nonclustered Columnstore Indexes. As in the previous post, I have decided to continue using Contoso BI Database. In this test I will ignore the compression ratio from the original tables, since I just want to compare the results of the compression between Nonclustered Columnstore and Clustered Columnstore Indexes.
I have choosen to investigate 4 fact tables: FactStrategyPlan, FactSales, FactInventory & FactSalesQuota – they all have a different amount of data and their number of columns is not prohibitive for playing with Nonclustered Columnstore Indexes.
Lets drop all the keys (first Foreign and then Primary) for our 4 tables:
-- Drop all Foreign Keys ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimAccount] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimCurrency] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimDate] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimEntity] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimProductCategory] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimScenario] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimChannel] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimCurrency] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimDate] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimProduct] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimPromotion] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimStore] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimCurrency] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimDate] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimProduct] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimStore] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimChannel] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimCurrency] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimDate] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimProduct] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimScenario] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimStore] -- Drop all the Primary Keys ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [PK_FactStrategyPlan_StrategyPlanKey] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [PK_FactSales_SalesKey] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [PK_FactInventory_InventoryKey] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [PK_FactSalesQuota_SalesQuotaKey]
Now, game on and let us create Clustered Columnstore Indexes to see how much space they actually take:
Create Clustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactSales on dbo.FactSales WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactInventory on dbo.FactInventory WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactSalesQuota on dbo.FactSalesQuota WITH (DATA_COMPRESSION = COLUMNSTORE);
Lets check on the occupied space by executing the following commands:
exec sp_spaceused 'dbo.FactStrategyPlan', true; exec sp_spaceused 'dbo.FactSales', true; exec sp_spaceused 'dbo.FactInventory', true; exec sp_spaceused 'dbo.FactSalesQuota', true;
My results were: dbo.FactStrategyPlan – 30.840 KB, dbo.FactSales – 46.864 KB, dbo.FactInventory – 88.672 KB, dbo.FactSalesQuota – 110.616 KB respectively.
For now, lets just drop the Clustered Columnstore Indexes and try to create Nonclustered Columnstore Indexes on the HEAP:
-- Drop Clustered Columnstore Indexes: Drop Index PK_FactStrategyPlan on dbo.FactStrategyPlan; Drop Index PK_FactSales on dbo.FactSales; Drop Index PK_FactInventory on dbo.FactInventory; Drop Index PK_FactSalesQuota on dbo.FactSalesQuota; -- Create NonClustered Columnstore Indexes: Create NonClustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan (StrategyPlanKey, Datekey, EntityKey, ScenarioKey, AccountKey, CurrencyKey, ProductCategoryKey, Amount, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); Create NonClustered Columnstore Index PK_FactSales on dbo.FactSales (SalesKey, DateKey, channelKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, UnitCost, UnitPrice, SalesQuantity, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, SalesAmount, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); Create NonClustered Columnstore Index PK_FactInventory on dbo.FactInventory (InventoryKey, DateKey, StoreKey, ProductKey, CurrencyKey, OnHandQuantity, OnOrderQuantity, SafetyStockQuantity, UnitCost, DaysInStock, MinDayInStock, MaxDayInStock, Aging, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); Create NonClustered Columnstore Index PK_FactSalesQuota on dbo.FactSalesQuota (SalesQuotaKey, ChannelKey, StoreKey, ProductKey, DateKey, CurrencyKey, ScenarioKey, SalesQuantityQuota, SalesAmountQuota, GrossMarginQuota, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); -- Lets get the compression results: exec sp_spaceused 'dbo.FactStrategyPlan', true; exec sp_spaceused 'dbo.FactSales', true; exec sp_spaceused 'dbo.FactInventory', true; exec sp_spaceused 'dbo.FactSalesQuota', true;
The results for the Nonclustered Columnstore Indexes were following: dbo.FactStrategyPlan – 36.520 KB, dbo.FactSales – 54.952 KB, dbo.FactInventory – 101.168 KB, dbo.FactSalesQuota – 116.456 KB.
Note: Of course I am ignoring the fact that the Noncslutered Columnstore Index is not the only storage required for the table, but because in the post I am just focussing on the compression itself, I will be ignoring the rest of the required space.
 Lets compare the results now: it is quite visible that in the case of all 4 tables tested in this blog post, Clustered Columnstore has beaten the Nonclustered Columnstore Index by applying a better compression as it was expected.
Lets compare the results now: it is quite visible that in the case of all 4 tables tested in this blog post, Clustered Columnstore has beaten the Nonclustered Columnstore Index by applying a better compression as it was expected.
Clustered Columnstore vs HEAP NonClustered Columnstore:
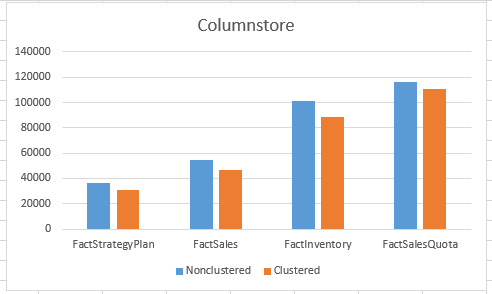
The average improvement was rounding about 10%, but once again I would like to stress that this is a very small test data with just 4 cases. This case serves though to test and to prove that the Clustered Columnstore Index has a different algorithm then the Nonclustered Columnstore Index, and that the Clustered Columnstore Indexes besides other improvement (updateable, supported data types, etc) offers a significantly better compression ratio using the default compression.
Update: Now let us consider the situation when the Nonclustered Columnstore Index is being built on the top of a Unique Clustered Index:
-- Drop NonClustered Columnstore: Drop Index PK_FactStrategyPlan on dbo.FactStrategyPlan; Drop Index PK_FactSales on dbo.FactSales; Drop Index PK_FactInventory on dbo.FactInventory; Drop Index PK_FactSalesQuota on dbo.FactSalesQuota; -- Create a traditional Unique Clustered Index create clustered Index PK_FactStrategyPlan on dbo.FactStrategyPlan (StrategyPlanKey ASC) WITH ( DATA_COMPRESSION = PAGE); create clustered Index PK_FactSales on dbo.FactSales (SalesKey ASC) WITH ( DATA_COMPRESSION = PAGE); create clustered Index PK_FactInventory on dbo.FactInventory (InventoryKey ASC) WITH ( DATA_COMPRESSION = PAGE); create clustered Index PK_FactSalesQuota on dbo.FactSalesQuota (SalesQuotaKey ASC) WITH ( DATA_COMPRESSION = PAGE); -- Create a NonClustered Columnstore Index Create NonClustered Columnstore Index NC_PK_FactStrategyPlan on dbo.FactStrategyPlan (StrategyPlanKey, Datekey, EntityKey, ScenarioKey, AccountKey, CurrencyKey, ProductCategoryKey, Amount, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); Create NonClustered Columnstore Index NC_PK_FactSales on dbo.FactSales (SalesKey, DateKey, channelKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, UnitCost, UnitPrice, SalesQuantity, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, SalesAmount, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); Create NonClustered Columnstore Index NC_PK_FactInventory on dbo.FactInventory (InventoryKey, DateKey, StoreKey, ProductKey, CurrencyKey, OnHandQuantity, OnOrderQuantity, SafetyStockQuantity, UnitCost, DaysInStock, MinDayInStock, MaxDayInStock, Aging, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); Create NonClustered Columnstore Index NC_PK_FactSalesQuota on dbo.FactSalesQuota (SalesQuotaKey, ChannelKey, StoreKey, ProductKey, DateKey, CurrencyKey, ScenarioKey, SalesQuantityQuota, SalesAmountQuota, GrossMarginQuota, ETLLoadID, LoadDate, UpdateDate) WITH ( DATA_COMPRESSION = COLUMNSTORE); -- Lets get the compression results: exec sp_spaceused 'dbo.FactStrategyPlan', true; exec sp_spaceused 'dbo.FactSales', true; exec sp_spaceused 'dbo.FactInventory', true; exec sp_spaceused 'dbo.FactSalesQuota', true; -- Drop the Nonclustered Columnstore: Drop Index NC_PK_FactStrategyPlan on dbo.FactStrategyPlan; Drop Index NC_PK_FactSales on dbo.FactSales; Drop Index NC_PK_FactInventory on dbo.FactInventory; Drop Index NC_PK_FactSalesQuota on dbo.FactSalesQuota; -- Create the Clustered Columnstore: Create Clustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactSales on dbo.FactSales WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactInventory on dbo.FactInventory WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactSalesQuota on dbo.FactSalesQuota WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE); -- Lets get the compression results: exec sp_spaceused 'dbo.FactStrategyPlan', true; exec sp_spaceused 'dbo.FactSales', true; exec sp_spaceused 'dbo.FactInventory', true; exec sp_spaceused 'dbo.FactSalesQuota', true;
The amounts of data inside of the tables is less even for the Clustered Columnstore is because we are rebuilding on the top of the existing ordered traditional clustered index, this way enabling a better compression.
Now, lets take a look at the results:

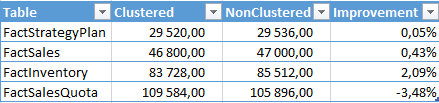
It looks like there are some other external factors that potentially influence the size of the created tables, and that the variation can go either side in a couple of percent.
The difference between the results is very insignificant, which actually shows that the compression itself is extremely close or really the same. I have heard before and truly believed that the difference would be quite significant, but these tests has shown me so far that the difference is absolutely minimal.
This test proves that the Clustered Columnstore Indexes are making the Noncslutered Columnstore Indexes obsolete (especially when not using a traditional Clustered Index for Nonclustered Columnstore) in a major number of scenarios, and that only some very specific cases will be deserving the Nonclustered Columnstore Indexes usage.
to be continued with Clustered Columnstore Indexes – part 12 (“Compression Dive”)
Pingback: Clustered Columnstore Indexes – part 1 (“Intro”) | Nikoport
Hi Experts,
Can we deduce that both the algorithms are the same.
Here Heap+ NCCI should also be taken into consideration.
Hi Manish Kumar,
Yes, the algorithms are the same, but the internal architecture varies between the different columnstore solutions. The overall compression algorithm appears to be the same.
May be i’ve understood wrong, above you have made clustered column store index over unique clustered index. Two clustered index on a table? Or you have rebuild that index on a new table
Hi aakash,
I suggest to try out the script.
Best regards,
Niko Neugebauer
Dear Niko Neugebauer,
We are facing huge performance impact, When creating Non clustered column store index in our production environment against our staging table holds 135 columns, we exclude one computed column. This table holds 1 billion two hundred and 39 million records. Our server holds 2 sockets fitted with two eight core server class CPU, Running with 16 physical core (8 + 8) and 16 logical core of overall 32 cores CPU installed with 256 GB of RAM. SQL server capped with 232 GB of Memory. The index is still running for more than 12 hours. The stage table is a heap overall table storage is 950 GB, We crossed 14 hours, the disk size reduced from 1 TB to 700 GB of size and CPU is peaked with 100% utilization. SQL Server running with 2016 version and server isolation is configured with snapshot isolation, Tempdb residing in a drive with space 2 TB, Everything looks good, Server MAX DOP setting is with default i.e 0 and index creation uses all the cores. Do you have any thoughts our job completion and performance improvement for our index creation process?
Hi Kannan,
I suggest looking at these 2 following posts: http://www.nikoport.com/2014/06/21/clustered-columnstore-indexes-part-31-memory-pressure-and-row-group-sizes/ & http://www.nikoport.com/2015/02/18/clustered-columnstore-indexes-part-48-improving-dictionary-pressure/ to find out if you are suffering
while measuring the real impact on the row groups. It looks like you are getting throttled.
Best regards,
Niko Neugebauer