Continuation from the previous 5 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
In the previous 5 parts of this blog series I have described how some of the things related to Clustered Columnstore Indexes are functioning, and so in this part I wanted to show you some of my experiments – so expect a lot of T-SQL code here. :)
Lets kick off by creating a new table with a good number (2.4 Millions) of rows.
-- Table definition create table dbo.CCTest( id int not null, name varchar(50) not null, lastname varchar(50) not null ); GO -- Creating our Clustered Columnstore Index create clustered columnstore index CCL_CCTest on dbo.CCTest; GO -- Insert 2.4 million rows declare @i as int; declare @max as int; select @max = isnull(max(id),0) from dbo.CCTest; set @i = 1; begin tran while @i <= 2400000 begin insert into dbo.CCTest ( id, name, lastname ) values ( @max + @i, 'SomeName_', 'SomeLastName_' ); set @i = @i + 1; end; commit;
Now, lets take a look what kind of information is visible inside of the available DMV's:
select * from sys.column_store_dictionaries; select * from sys.column_store_segments; select * from sys.column_store_row_groups;
Right after the insertion the first 2 DMVs are apparently empty, while the new one sys.column_store_row_groups is actually showing some relevant information.
 This happens because we just created 3 Delta Stores and Tuple Mover have not encoded and created Segments out of them. 2 of the Delta Stores have already reached status "CLOSED" because they have reached the maximum number of rows for a Row Group - 1048576, while the last one is still "OPEN". Note: Typically everybody mentions 1 million, but this is because we are IT people, and we do understand that typically there are no round numbers on the computers. :)
This happens because we just created 3 Delta Stores and Tuple Mover have not encoded and created Segments out of them. 2 of the Delta Stores have already reached status "CLOSED" because they have reached the maximum number of rows for a Row Group - 1048576, while the last one is still "OPEN". Note: Typically everybody mentions 1 million, but this is because we are IT people, and we do understand that typically there are no round numbers on the computers. :)
Note: If you wait long enough then the Tuple Mover shall kick in (it does every 5 minutes by default, and after its work the information inside the first 2 DMV's shall be updated.
To continue we can wait until Tuple Mover kicks in, or we can invoke it manually by rebuilding or reorganizing our table or Clustered Columnstore Index or we can simply rebuild the whole table. (Note: in this example we shall be ignoring partitions.)
Lets rebuild the whole table in order to make sure that everything is well compressed:
alter table dbo.CCTest rebuild; GO -- Lets consult our views once again: select * from sys.column_store_dictionaries; select * from sys.column_store_segments; select * from sys.column_store_row_groups;
Now we have some results from the first 2 DMV's and the new one DMV for the Row Groups is showing different results:
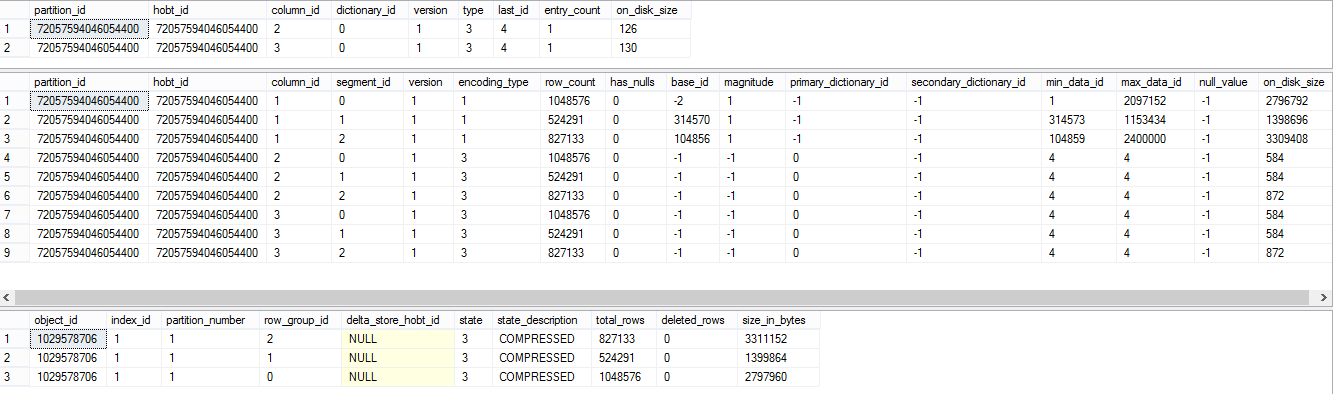 Lets study the results and try to understand what has just happened.
Lets study the results and try to understand what has just happened.
First of all we have 2 Dictionaries, which correspond to our 2nd and 3rd columns in the table. This makes perfect sense, since both of those columns have Varchar datatype. Value 3 at the Type says that the hash dictionary is using string values. Each of the dictionaries has just 1 entry, which is also quite logical given the fact that we have inserted almost the same values into both of the string columns.
Inside the sys.column_store_segments DMV we see the number of rows which is equal to the number of Segments times Columns in the table:
ColumnStore_Segments = Segments * Cols
Notice that the number of rows per each Row Group is equal and that this is the view that contains all the relevant information about the Segments max and min values, as well as its size on the disk. It is quite remarkable that String values being so similar in fact occupying so few space, while integer column while even sequential is still occupying the majority of space. This really shows the power of the compression, as well as one of the points where compression algorithm might be improved.
Now lets take a look at what has happened to the sys.column_store_row_groups DMV:
All 3 Delta Stores have become Segments and their status has changed to "COMPRESSED" respectively. Other remarkable difference is the number of the rows in the segments. While the first Segment (id=0) has stayed with maximum number of rows, the 2nd Segment has "shared" some of the rows with the third one, so instead of having ~300K rows, the 3rd Segment has now around 800K rows.
From seeing this I assume that Tuple Mover Rebuild Process is actually trying to balance the things and while rebuilding the whole table it might decide to movie data from one Segment to another if it sees that it can improve the performance of the System.
Lets not stop here and let us add 100.000 rows more to our table:
declare @i as int; declare @max as int; select @max = isnull(max(id),0) from dbo.CCTest; set @i = 1; begin tran while @i <= 100000 begin insert into dbo.CCTest ( id, name, lastname ) values ( @max + @i, 'SomeName_', 'SomeLastName_' ); set @i = @i + 1; end; commit; -- What can be seen inside of the Row Groups DMV select * from sys.column_store_row_groups;
 Now because we have had no other Delta Store open, SQL Server has decide to create a new Delta store, where it has inserted our new 100.000 rows. Lets run this script again to see if there is any difference. This time it has the same number of Row Groups and no new Delta Stores has been added.
Now because we have had no other Delta Store open, SQL Server has decide to create a new Delta store, where it has inserted our new 100.000 rows. Lets run this script again to see if there is any difference. This time it has the same number of Row Groups and no new Delta Stores has been added.
Bulk Insert:
This is all have been fun, but let's try now to work with Bulk Insert to observe its behavior. I have prepared 2 files to play with - "CCITest.csv" with around 80K rows and "CCITest_2.csv" with around 160K rows. In this experiment I am trying to observe the behavior described earlier in the part 2 that Bulk Insert is treating the insertion differently basing on the amount of rows.
-- Drop the table
drop table dbo.CCTest;
GO
BULK INSERT Columnstore.dbo.CCTest
FROM '\\XComp\Share\CCITest.csv'
WITH
(
FIELDTERMINATOR =';',
ROWTERMINATOR ='\n'
);
BULK INSERT Columnstore.dbo.CCTest
FROM '\\XComp\Share\CCITest_2.csv'
WITH
(
FIELDTERMINATOR =';',
ROWTERMINATOR ='\n'
);
-- Lets check our Row Groups:
select *
from sys.column_store_row_groups;

And here we go, just as expected - 80K rows did not create a compressed Segment but a Delta Store, while the 160K rows have created a perfectly compressed Segment. :)
This blog post is updated on 9th of June 2013 after the information & insight provided by Remus Rusanu.
to be continued with Clustered Columnstore Indexes – part 7 ("Transaction Isolation")
Pingback: Clustered Columnstore Indexes – part 1 (“Intro”) | Nikoport
hi Niko,
do you know if Bulk Insert is supported with PDW AU1. I tried the above bulk insert syntax and its not working.
Hi Sesuraj,
I believe you should try DWLoader.exe
Best regards,
Niko Neugebauer